PHP 中根据url来获得网页内容非常的方便,可以通过系统内置函数file_get_contents(),传入url,即可返回网页的内容,比如获得百度首页的内容代码为:
就可以显示出百度首页的内容,但是,这个函数不是万能的,因为有些服务器会禁用掉这个函数,或者说这个函数因为没有传给服务器某些必要的参数,而被服务器拒绝响应,举个例子:
这个代码就不能得到网易的首页完全的代码,会返回如下的页面,这时我们就需要想其他的办法了。
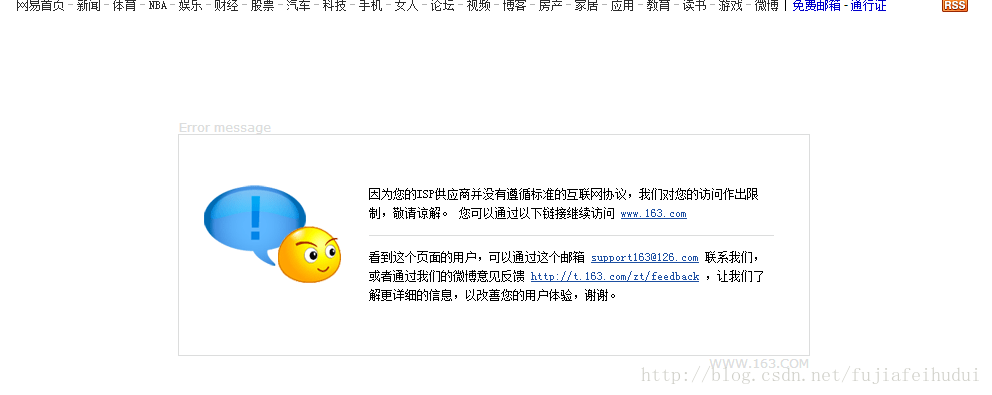
这里我们引入php的cURL 库,可以简单和有效地去抓网页。你只需要运行一个脚本,然后分析一下你所抓取的网页,然后就可以以程序的方式得到你想要的数据了。无论是你想从从一个链接上取部分数据,或是取一个XML文件并把其导入数据库,那怕就是简单的获取网页内容,cURL 是一个功能强大的PHP库。使用它首先你得在php的配置文件中开启它,开启的时候,在windows中可能需要一些 dll,这里就不相信介绍了,查看是否开启了curl,可以调用phpinfo();来查看,如果开启了,会在“Loaded Extensions”中显示。
下面给出使用curl获取网页代码的简单例子:
通过这段代码就可以输出网易首页的内容了,这里标记红颜色的代码是关键,因为他模拟了浏览器的agent,这样服务器就会以为它是浏览器去访问的,所以给他返回正确的html.
最后
以上就是酷酷缘分最近收集整理的关于php根据URL获得网页内容的全部内容,更多相关php根据URL获得网页内容内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复