1.确定目标网址
目标网址:
![]()
确定我需要的数据
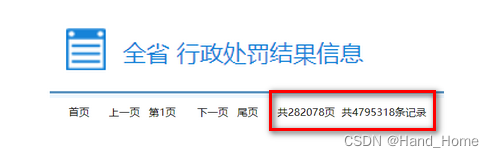
获取的数据量大,用到Scrapy框架
2. 我们就分析目标网址。
1)利用抓包,分析到一些包的路径。
每次下一页时,就会加载出新的包。这个链接网页是这样滴。
这个url地址很长,又找啊,终于找到个短一点的。
感觉这个也长我们就修改一下。第一页的url地址就有了,其它也只需用range()函数就能获取到他28w页数据了
访问结果也是一样滴
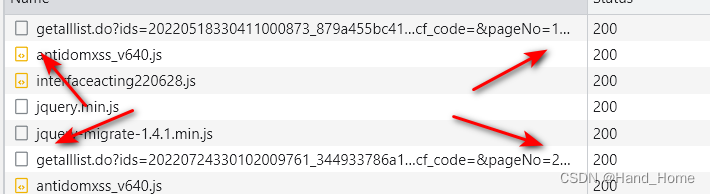



3.然后就剩写代码了呢就简单了,
1.用到了xpath
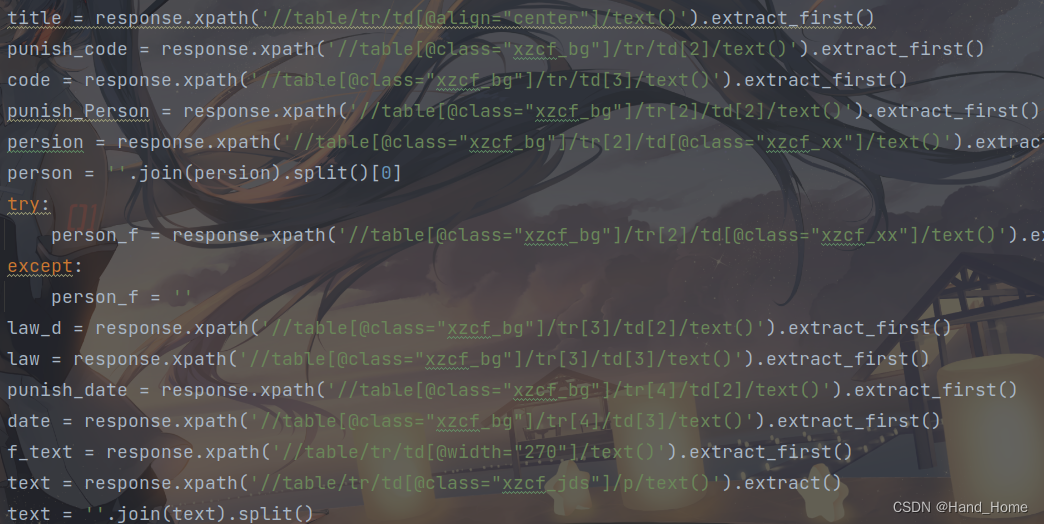
2.解决网站访问频次过高问题,设置设置时间间隔,不然太快,就会被封IP,让对面觉得你不是人为在浏览。
Scrapy设置时间间隔非常简单。
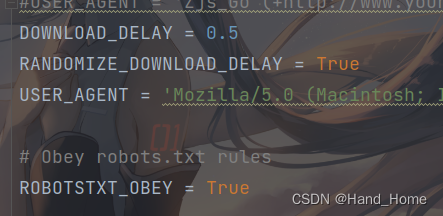
我们设置的是每0.5秒访问一次。
然后就是保存,我们保存csv格式。
class ZjsGoPipeline:
def __init__(self):
self.file = open('Z4.csv', 'wb')
self.exporter = CsvItemExporter(self.file, encoding='utf-8')
self.exporter.start_exporting()
def close_spider(self, spider):
self.exporter.finish_exporting()
self.file.close()
def process_item(self, item, spider):
# print('默认的字段数据:{}n'.format(item))
item = OrderedDict(item)
item = json.dumps(item, ensure_ascii=False)
print('调整后的字段数据:{}n'.format(item))
self.exporter.export_item(eval(item))
return item我们的爬虫就搞定了
最后
以上就是精明鸵鸟最近收集整理的关于Scrapy框架多线程爬取百万数据1.确定目标网址2. 我们就分析目标网址。 3.然后就剩写代码了呢就简单了,的全部内容,更多相关Scrapy框架多线程爬取百万数据1.确定目标网址2.内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复