以下按自己的编码风格复现书本代码
单线程
程序主要思路:
graph TD
A(获取指定网页字符内容) -->B(从中筛选出所有图像url)
B --> C(逐一对图像url进行预处理:拼接,去重)
C --> D(逐一下载相应的图片到本地images子文件中)
D --> E(将下载的Url信息在控制台输出)
代码:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request # 可换用requests
import os
import time
import warnings
warnings.filterwarnings("ignore") # 在控制台屏蔽警告
class ThreadSpiderImages(object):
'''单线程爬取指定网站图片类'''
def __init__(self,start_url):
'''共同属性是UA头以及url'''
self.url = start_url
self.headers = {
"User-Agent": "Mozilla/5.0"
}
def get_html_text(self):
'''获取指定url的网页字符串'''
req = urllib.request.Request(self.url, headers=self.headers)
html = urllib.request.urlopen(req)
html_text = html.read()
dammit = UnicodeDammit(html_text, ["utf-8","gbk"]) # 猜测文档编码
html_text = dammit.unicode_markup
return html_text
def extract_imageurls(self,images):
'''
从解析出的bs4ResultSet对象中提取图像url信息,
返回图像urls
'''
urls = []
for image in images:
try:
src = image["src"] # 图像文件的src地址
url = urllib.request.urljoin(self.url, src) # 构建完整url
if url not in urls: # url去重
urls.append(url)
print(url)
except Exception as err:
print(err)
return urls
def download(self,urls):
'''下载urls中每个url对应的图像'''
count = 0
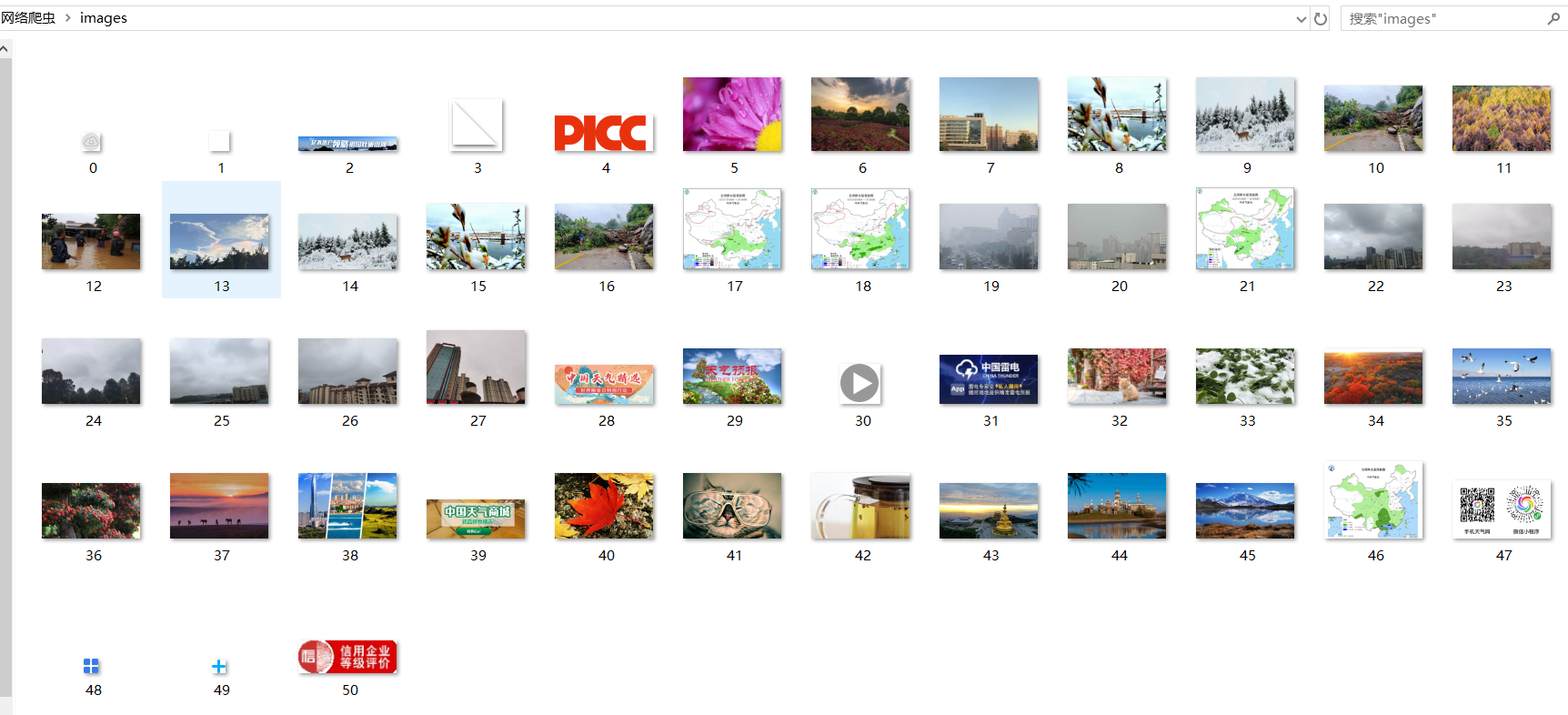
dirname = "images"
current_path = os.getcwd()
if not os.path.exists(dirname): # 如果文件夹不存在则创建
os.makedirs(dirname)
print("{}文件夹创建在{}".format(dirname, current_path))
try:
for url in urls:
pos = url[::-1].index(".") + 1 # 找到最后一个.在第几个位置(注意下标从0开始)
ext = url[-pos:] # 后缀名
# 将下载的图像文件存入当前文件夹下的images文件夹
filename = str(count) + ext
filepath = dirname + "\" + filename
try:
urllib.request.urlretrieve(url, filepath)
except:
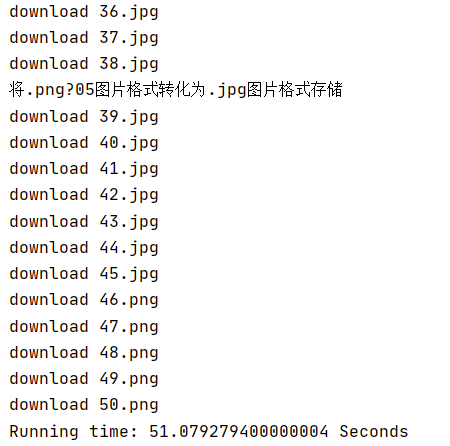
default_ext = '.jpg' # 将异常图片格式转化为默认格式.jpg
print("将{}图片格式转化为{}图片格式存储".format(ext,default_ext))
filename = str(count) + default_ext
filepath = dirname + "\" + filename
urllib.request.urlretrieve(url, filepath)
print("download "+filename)
count += 1
except Exception as err:
print(err)
if __name__ == "__main__":
start = time.clock()
start_url = "http://www.weather.com.cn/weather/101280601.shtml" # 指定网站
spider = ThreadSpiderImages(start_url)
try:
html_text = spider.get_html_text()
soup = BeautifulSoup(html_text, "html.parser")
images = soup.select("img") # 选择图像文件
urls = spider.extract_imageurls(images)
spider.download(urls)
except Exception as err:
print(err)
end = time.clock()
print('Running time: %s Seconds' % (end - start))
运行结果部分截图:

多线程
程序主要思路基本上同单线程,差别仅在于多线程中为每一个图像url创建线程对象,逐一以download函数为目标启动线程
代码:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request # 可换用requests
import os
import threading
import time
import warnings
warnings.filterwarnings("ignore")
class ThreadsSpiderImages(object):
'''多线程爬取指定网站图片类'''
def __init__(self,start_url):
'''共同属性是UA头以及url'''
self.url = start_url
self.headers = {
"User-Agent": "Mozilla/5.0"
}
def get_html_text(self):
'''获取指定url的网页字符串'''
req = urllib.request.Request(self.url, headers=self.headers)
html = urllib.request.urlopen(req)
html_text = html.read()
dammit = UnicodeDammit(html_text, ["utf-8","gbk"]) # 猜测文档编码
html_text = da
最后
以上就是谦让银耳汤最近收集整理的关于python scrapy框架基如何实现多线程_网络爬虫第三次作业——多线程、scrapy框架...的全部内容,更多相关python内容请搜索靠谱客的其他文章。








发表评论 取消回复