
本文主要分为两个部分:一部分是网络爬虫的概述,帮助大家详细了解网络爬虫;另一部分是HTTP请求的Python实现,帮助大家了解Python中实现HTTP请求的各种方式,以便具备编写HTTP网络程序的能力。
01
网络爬虫概述
接下来从网络爬虫的概念、用处与价值和结构等三个方面,让大家对网络爬虫有一个基本的了解。
1. 网络爬虫及其应用
随着网络的迅速发展,万维网成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的挑战,网络爬虫应运而生。网络爬虫(又被称为网页蜘蛛、网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。下面通过图3-1展示一下网络爬虫在互联网中起到的作用:
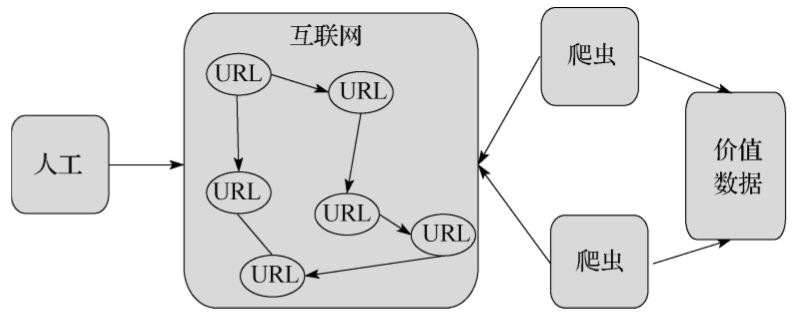
▲图3-1 网络爬虫
网络爬虫按照系统结构和实现技术,大致可以分为以下几种类型:通用网络爬虫、聚焦网络爬虫、增量式网络爬虫、深层网络爬虫。实际的网络爬虫系统通常是几种爬虫技术相结合实现的。
搜索引擎(Search Engine),例如传统的通用搜索引擎baidu、Yahoo和Google等,是一种大型复杂的网络爬虫,属于通用性网络爬虫的范畴。但是通用性搜索引擎存在着一定的局限性:
-
不同领域、不同背景的用户往往具有不同的检索目的和需求,通用搜索引擎所返回的结果包含大量用户不关心的网页。
-
通用搜索引擎的目标是尽可能大的网络覆盖率,有限的搜索引擎服务器资源与无限的网络数据资源之间的矛盾将进一步加深。
-
万维网数据形式的丰富和网络技术的不断发展,图片、数据库、音频、视频多媒体等不同数据大量出现,通用搜索引擎往往对这些信息含量密集且具有一定结构的数据无能为力,不能很好地发现和获取。
-
通用搜索引擎大多提供基于关键字的检索,难以支持根据语义信息提出的查询。
为了解决上述问题,定向抓取相关网页资源的聚焦爬虫应运而生。
聚焦爬虫是一个自动下载网页的程序,它根据既定的抓取目标,有选择地访问万维网上的网页与相关的链接,获取所需要的信息。与通用爬虫不同,聚焦爬虫并不追求大的覆盖,而将目标定为抓取与某一特定主题内容相关的网页,为面向主题的用户查询准备数据资源。
说完了聚焦爬虫,接下来再说一下增量式网络爬虫。增量式网络爬虫是指对已下载网页采取增量式更新和只爬行新产生的或者已经发生变化网页的爬虫,它能够在一定程度上保证所爬行的页面是尽可能新的页面。
和周期性爬行和刷新页面的网络爬虫相比,增量式爬虫只会在需要的时候爬行新产生或发生更新的页面,并不重新下载没有发生变化的页面,可有效减少数据下载量,及时更新已爬行的网页,减小时间和空间上的耗费,但是增加了爬行算法的复杂度和实现难度。
例如:想获取赶集网的招聘信息,以前爬取过的数据没有必要重复爬取,只需要获取更新的招聘数据,这时候就要用到增量式爬虫。
最后说一下深层网络爬虫。Web页面按存在方式可以分为表层网页和深层网页。表层网页是指传统搜索引擎可以索引的页面,以超链接可以到达的静态网页为主构成的Web页面。深层网络是那些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户提交一些关键词才能获得的Web页面。
例如用户登录或者注册才能访问的页面。可以想象这样一个场景:爬取贴吧或者论坛中的数据,必须在用户登录后,有权限的情况下才能获取完整的数据。
2. 网络爬虫结构
下面用一个通用的网络爬虫结构来说明网络爬虫的基本工作流程,如图3-4所示。
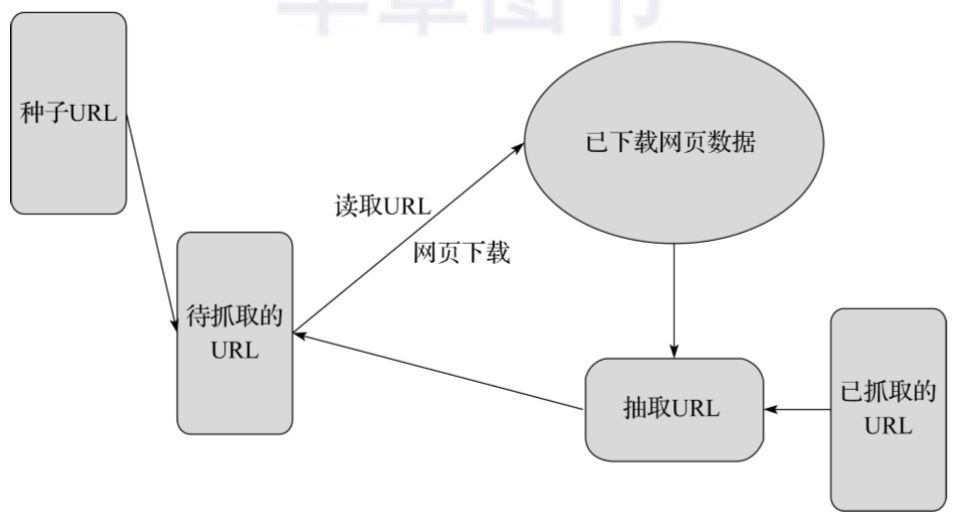
▲图3-4 网络爬虫结构
网络爬虫的基本工作流程如下:
-
首先选取一部分精心挑选的种子URL。
-
将这些URL放入待抓取URL队列。
-
从待抓取URL队列中读取待抓取队列的URL,解析DNS,并且得到主机的IP,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。
-
分析已抓取URL队列中的URL,从已下载的网页数据中分析出其他URL,并和已抓取的URL进行比较去重,最后将去重过的URL放入待抓取URL队列,从而进入下一个循环。
02
HTTP请求的Python实现
通过上面的网络爬虫结构,我们可以看到读取URL、下载网页是每一个爬虫必备而且关键的功能,这就需要和HTTP请求打交道。接下来讲解Python中实现HTTP请求的三种方式:urllib2/urllib、httplib/urllib以及Requests。
1. urllib2/urllib实现
urllib2和urllib是Python中的两个内置模块,要实现HTTP功能,实现方式是以urllib2为主,urllib为辅。
1.1 首先实现一个完整的请求与响应模型
urllib2提供一个基础函数urlopen,通过向指定的URL发出请求来获取数据。最简单的形式是:
import urllib2
response=urllib2.urlopen('http://www.zhihu.com')
html=response.read()
print html
其实可以将上面对http://www.zhihu.com的请求响应分为两步,一步是请求,一步是响应,形式如下:
import urllib2
# 请求
request=urllib2.Request('http://www.zhihu.com')
# 响应
response = urllib2.urlopen(request)
html=response.read()
print html
上面这两种形式都是GET请求,接下来演示一下POST请求,其实大同小异,只是增加了请求数据,这时候用到了urllib。示例如下:
import urllib
import urllib2
url = 'http://www.xxxxxx.com/login'
postdata = {'username' : 'qiye',
'password' : 'qiye_pass'}
# info 需要被编码为urllib2能理解的格式,这里用到的是urllib
data = urllib.urlencode(postdata)
req = urllib2.Request(url, data)
response = urllib2.urlopen(req)
html = response.read()
但是有时会出现这种情况:即使POST请求的数据是对的,但是服务器拒绝你的访问。这是为什么呢?问题出在请求中的头信息,服务器会检验请求头,来判断是否是来自浏览器的访问
最后
以上就是复杂老鼠最近收集整理的关于Python爬虫 手把手教你利用爬虫爬取网页 的全部内容,更多相关Python爬虫内容请搜索靠谱客的其他文章。








发表评论 取消回复