Lecture 11 :Linear Models for Classification
【参考】https://redstonewill.com/243/
【概括】
- 分类问题的三种线性模型:linear classification、linear regression和logistic regression。这三种linear models都可以来做binary classification;
- 比梯度下降算法更加高效的SGD算法来进行logistic regression分析;
- 两种多分类方法,一种是OVA,另一种是OVO。这两种方法各有优缺点,当类别数量k不多的时候,建议选择OVA,以减少分类次数。
11.1 Linear Models for Binary Classification
三种线性模型:
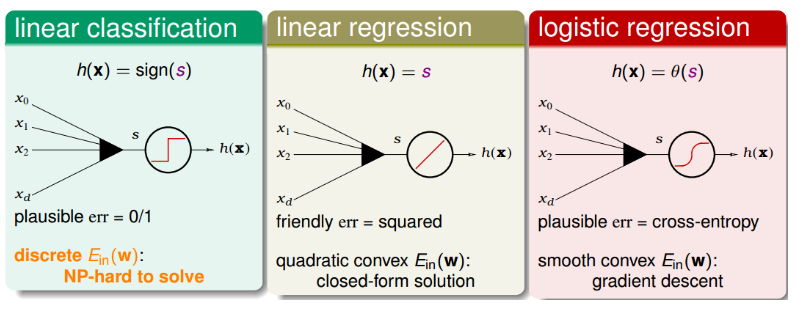
三种线性模型的Error function可以写成:
其中,ys就是指分类的正确率得分,其值越大越好,得分越高。



PLA,linear regression,logistic regression模型用来解linear classification问题的优点和缺点。通常,我们使用linear regression来获得初始化的w0,再用logistic regression模型进行最优化解。

11.2 Stochastic Gradient Descent
**随机梯度下降算法每次迭代只找到一个点,计算该点的梯度,作为我们下一步更新w的依据。**这样就保证了每次迭代的计算量大大减小,我们可以把整体的梯度看成这个随机过程的一个期望值。

**随机梯度下降可以看成是真实的梯度加上均值为零的随机噪声方向。**单次迭代看,好像会对每一步找到正确梯度方向有影响,但是整体期望值上看,与真实梯度的方向没有差太多,同样能找到最小值位置。随机梯度下降的优点是减少计算量,提高运算速度,而且便于online学习;缺点是不够稳定,每次迭代并不能保证按照正确的方向前进,而且达到最小值需要迭代的次数比梯度下降算法一般要多。
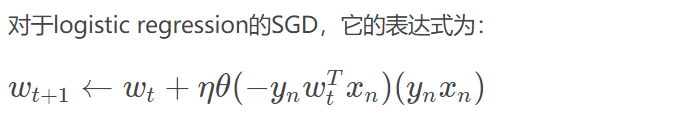
- SGD的终止迭代条件。没有统一的终止条件,一般让迭代次数足够多;
- 学习速率的取值是根据实际情况来定的,一般取值0.1就可以了。
11.3 Multiclass via Logistic Regression
soft软性分类,即不用{-1,+1}这种binary classification,而是使用logistic regression,计算某点属于某类的概率、可能性,去概率最大的值为那一类就好。
soft classification的处理过程:分别令某类为正,其他三类为负,不同的是得到的是概率值,而不是{-1,+1}。最后得到某点分别属于四类的概率,取最大概率对应的哪一个类别就好。
这种多分类的处理方式,我们称之为One-Versus-All(OVA) Decomposition。这种方法的优点是简单高效,可以使用logistic regression模型来解决;缺点是如果数据类别很多时,那么每次二分类问题中,正类和负类的数量差别就很大,数据不平衡unbalanced,这样会影响分类效果。但是,OVA还是非常常用的一种多分类算法。

11.4 Multiclass via Binary Classification
多分类算法OVA存在一个问题,就是当类别k很多的时候,造成正负类数据unbalanced,会影响分类效果,表现不好。现在,我们介绍另一种方法来解决当k很大时,OVA带来的问题。
这种方法呢,每次只取两类进行binary classification,取值为{-1,+1}。假如k=4,那么总共需要进行6次binary classification。那么,六次分类之后,如果平面有个点,有三个分类器判断它是正方形,一个分类器判断是菱形,另外两个判断是三角形,那么取最多的那个,即判断它属于正方形,我们的分类就完成了。
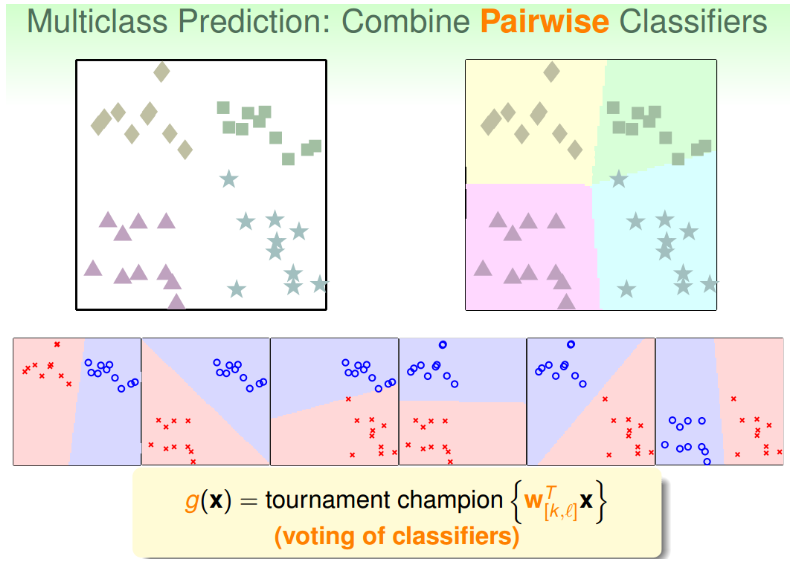
这种区别于OVA的多分类方法叫做One-Versus-One(OVO)。这种方法的优点是更加高效,因为虽然需要进行的分类次数增加了,但是每次只需要进行两个类别的比较,也就是说单次分类的数量减少了。而且一般不会出现数据unbalanced的情况。缺点是需要分类的次数多,时间复杂度和空间复杂度可能都比较高。

最后
以上就是暴躁乌冬面最近收集整理的关于Lecture 11 :Linear Models for Classification的全部内容,更多相关Lecture内容请搜索靠谱客的其他文章。








发表评论 取消回复