文章目录
- Lecture 9:Linear Regression
- Linear Regression Problem
- Linear Regression Algorithm
- Generalization Issue
- Linear Regression for Binary Classification
Lecture 9:Linear Regression
Linear Regression Problem
例子:机器学习决定发放给用户的信用卡额度,和之前不同的是这个问题输出不是是/否,而是一个实数值。
线性回归的假设:
x = ( x 0 , x 1 , . . . , x d ) x=(x_0,x_1,...,x_d) x=(x0,x1,...,xd)代表用户的各项特征(特征向量)
我们希望输出的信用卡额度与特征的加权和非常接近: y ≈ ∑ i = 0 d w i x i yapprox sum_{i=0}^{d}w_ix_i y≈∑i=0dwixi
那么线性回归的假设形式: h ( x ) = w T x h(x)=w^Tx h(x)=wTx
这个假设的形式与perceptron有些类似,但没有sign的过程
以一维特征向量和二维特征向量为例,线性回归的目标是在空间内找到一条直线或者平面,使样本点与之更加接近,或者说使residual最小:

一般线性回归使用squared error来衡量误差:

Linear Regression Algorithm
E i n ( w ) E_{in}(w) Ein(w)是关于权重的函数,我们如何找到合适的 w w w使得 E i n ( w ) E_{in}(w) Ein(w)最小?
把 E i n ( w ) E_{in}(w) Ein(w)的公式转化为矩阵运算的形式(把多个向量的平方和转化为一个大向量长度的平方):

现在,我们的目标转化为:
m
i
n
w
E
i
n
(
w
)
=
1
N
∣
∣
X
w
−
y
∣
∣
2
min_wE_{in}(w)=frac{1}{N}||Xw-y||^2
minwEin(w)=N1∣∣Xw−y∣∣2
E
i
n
(
w
)
E_{in}(w)
Ein(w)一般有可微分、连续、凸函数的性质,所以只要找到梯度为0的位置,就是在函数图像上的最低点,也就是
E
i
n
(
w
)
E_{in}(w)
Ein(w)的最小值

求梯度:

梯度为0时,求出权重:

X T X X^TX XTX如果是可逆的,则 w = ( X T X ) − 1 X T y w=(X^TX)^{-1}X^Ty w=(XTX)−1XTy,只要样本数量 N N N远大于 d + 1 d+1 d+1就能保证矩阵的逆是存在的,称之为非奇异矩阵。
但是如果是奇异矩阵,不可逆怎么办呢?其实,大部分的计算逆矩阵的软件程序,都可以处理这个问题,也会计算出一个逆矩阵。所以,一般伪逆矩阵是可解的。

对比梯度下降法和正规方程法:
梯度下降法:
- 需要人为选择学习率
- 需要进行多次迭代
- 样本特征向量的维度很大时效果也很好
正规方程法:
- 不用确定学习率
- 不需要迭代
- 计算矩阵的逆运算时需要的时间复杂度是矩阵维度的三次方,因此当n过大时,使用正规方程组的时间会很长
Generalization Issue
下面说明线性回归可以通过最小二乘方法计算得到好的
E
i
n
E_{in}
Ein和
E
o
u
t
E_{out}
Eout

hat matrix的物理意义: y ^ hat{y} y^

如图, y y y是 N N N维空间中的向量(这里的 N N N指的是样本数据个数),代表样本数据实际输出值,粉色区域代表的是输入矩阵 X X X与不同的权重 w w w相乘构成的空间,所以预测的输出向量 y ^ hat{y} y^是在粉色空间中的一个向量。
机器学习的目标就是使 y ^ hat{y} y^尽可能接近 y y y,那么显然最好的是 y y y直接在粉色空间上垂直投影,hat matrix就表示将 y y y投影到 y ^ hat{y} y^这一操作: y ^ = H y hat{y}=Hy y^=Hy
那么从这个角度讲, y − y ^ = y − H y = ( I − H ) y y-hat{y}=y-Hy=(I-H)y y−y^=y−Hy=(I−H)y,所以 I − H I-H I−H表示的是将 y y y投影到 y − y ^ y-hat{y} y−y^的操作。
通过推导可以得到 t r a c e ( I − H ) = N − ( d + 1 ) trace(I-H)=N-(d+1) trace(I−H)=N−(d+1),物理意义是将 N N N维向量向 d + 1 d+1 d+1维空间投影时,余数剩余的自由度最大只有 N − ( d + 1 ) N-(d+1) N−(d+1)
如果存在噪声,如下图:

我们可以把 y y y看作是理想输出 f ( x ) f(x) f(x)加上noise的结果
上面的推导中 y y y通过 I − H I-H I−H转化为 y − y ^ y-hat{y} y−y^,而noise与y是线性变换关系,那么根据线性函数知识,我们推导出noise经过 I − H I-H I−H也能转换为 y − y ^ y-hat{y} y−y^
所以:
E
i
n
(
w
L
I
N
)
=
1
N
∣
∣
y
−
y
^
∣
∣
2
=
1
N
∣
∣
(
I
−
H
)
n
o
i
s
e
∣
∣
2
=
1
N
(
N
−
(
d
+
1
)
)
∣
n
o
i
s
e
∣
∣
2
E_{in}(w_{LIN})=frac{1}{N}||y-hat{y}||^2=frac{1}{N}||(I-H)noise||^2=frac{1}{N}(N-(d+1))|noise||^2
Ein(wLIN)=N1∣∣y−y^∣∣2=N1∣∣(I−H)noise∣∣2=N1(N−(d+1))∣noise∣∣2
(图中
σ
2
sigma^2
σ2是描述噪声的一个量)
最终得到:

把这两个变量画出来:

当N足够大时,二者逐渐接近,且收敛于 σ 2 sigma^2 σ2,二者之差为 2 ( d + 1 ) / N 2(d+1)/N 2(d+1)/N,(泛化误差)。这就类似VC理论,证明了当N足够大的时候,这种线性最小二乘法是可以进行机器学习的,算法有效!
Linear Regression for Binary Classification
能否将线性回归的方法应用于线性分类问题?
先对比一下两种方法:

下图展示了两种错误衡量方式的关系: e r r 0 / 1 ≤ e r r s q r err_{0/1}leq err_{sqr} err0/1≤errsqr
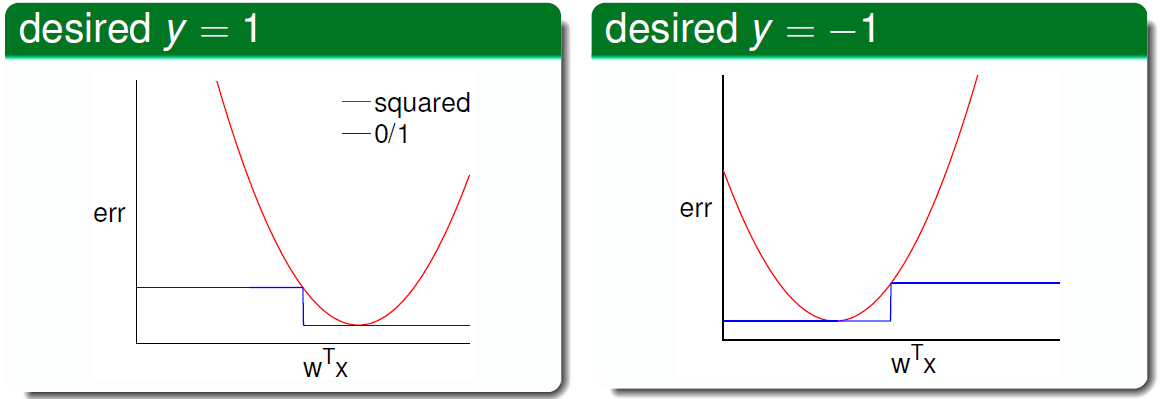
根据之前的VC理论, E o u t E_{out} Eout的上界满足:

所以 E o u t E_{out} Eout的上界只是变得更加宽松了,而不是没有上界,所以如果回归误差作为上限很小,那么分类误差也会很小,用线性回归方法仍然可以解决线性分类问题,效果不会太差。

最后
以上就是狂野香氛最近收集整理的关于【台大林轩田《机器学习基石》笔记】Lecture 9——Linear RegressionLecture 9:Linear Regression的全部内容,更多相关【台大林轩田《机器学习基石》笔记】Lecture内容请搜索靠谱客的其他文章。








发表评论 取消回复