准备工作
在Chrome浏览器中使用XPath
以百度首页为例,先简单讲一下怎么在Chrome浏览器中使用XPath解析网页的数据。
- 在Chrome浏览器中打开百度首页:www.baidu.com,然后按F12快捷键打开浏览器控制台,切换到Elements页签,就可以看到当前网页的HTML代码:
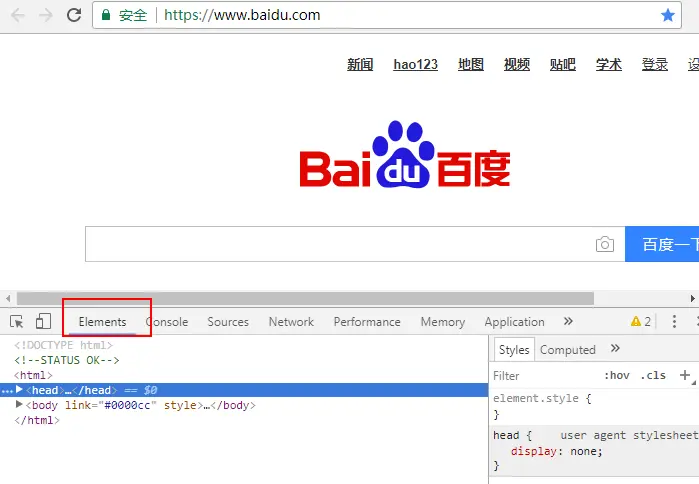
-
点击左边的箭头图标,指向百度的LOGO,效果如下:
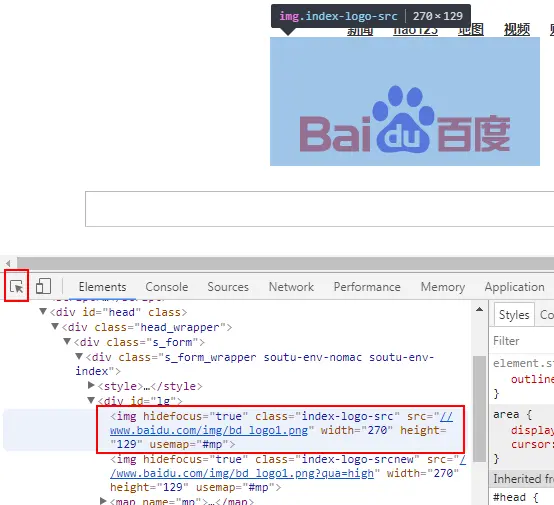
- 来分析LOGO图片链接所在的位置:它是一个class属性值为
s_form_wrapper soutu-env-nomac soutu-env-index的div标签下的第1个div标签下的img标签的src属性值。 -
根据上面对LOGO链接位置的分析,下面切到Console标签页面来写XPath表达式解析出这个LOGO的链接地址:
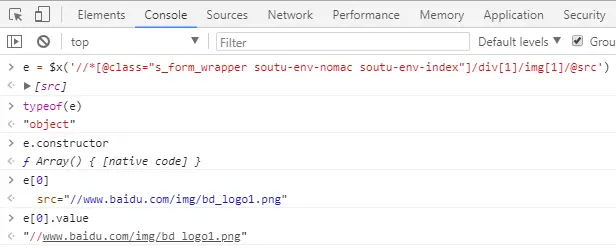
- 可见无论实际有多少个元素,XPath表达式的选取结果都是一个数组。
js的一些简单的用法
在Chrome控制台测试XPath,难免要接触到一些最基本的js语法,下面对可能用到的语法做一个简单的汇总:
控制台打印

查看一个对象的数据类型
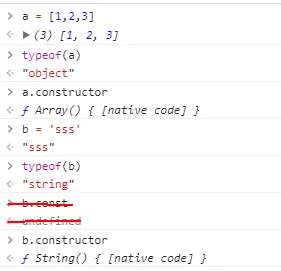
可见使用constructor比typeof看的的对象类型更准确。
循环遍历数组
-
方式1:普通for循环
-
方式2:for-in循环
-
方式3:for-of循环
综上可见使用for-of循环更为简洁一点。
定义函数
在这里封装了一个print函数来简化对console.log函数的调用。
JSON字符串和对象的相互转换
js是原生语法支持JSON数据结构的(JSON的全称就是JavaScript Object Notation, JS 对象标记),所以JSON字符串、对象的转换就非常方便了。
- JSON字符串转为对象
var str = '{"name":"Tom","info":{"age":18,"score":"A"}}';
obj = JSON.parse(str);
console.log(obj.name);
console.log(obj.info.score);
输出:
Tom
A
- 对象转为JSON字符串
var obj = {};
obj.name = 'Amy'
obj.info = {};
obj.info.age = 22;
str = JSON.stringify(obj);
console.log(str);
console.log(str.constructor);
输出:
{"name":"Amy","info":{"age":22}}
ƒ String() { [native code] }
js正则表达式的简单用法
- 定义一个正则表达式
两种方法:
// 方法1
var p1 = /d+/g; // 用`/.../`符号表示正则表达式对象,这里的`d+`就是正则表达式,后面的`g`是正则标识符,发挥一些特殊的作用。
// 方法2
var p2 = new RegExp('d+','g');
console.log(p1.constructor);
console.log(p2.constructor);
输出:
ƒ RegExp() { [native code] }
ƒ RegExp() { [native code] }
可见,用这两种方法定义的正则表达式是等效的。
- 正则表达式的几个方法
var p1 = /d+/g;
var s1 = '123';
var s2 = 'abc123e45';
# 测试字符串是否匹配正则
console.log(p1.test(s1));
console.log(p1.test(s2));
# 从字符串中查找和正则匹配的子串(一次查找一个,类似于迭代器)
console.log(p1.exec(s1));
# 从字符串中查找和正则匹配的子串列表
var ret = p1.exec(s2);
while(ret){
console.log(ret[0]);
ret = p1.exec(s2);
}
输出:
true
true
["123", index: 0, input: "123", groups: undefined]
123
45
解析各种网站的数据
解析简书首页文章列表
- 地址:https://www.jianshu.com/
-
文章列表总体结构:
-
列表项结构:
- 解析文章标题列表:
titles = $x('//*[@class="note-list"]/li/div[1]/a[1]/text()')
for (t of titles){
console.log(t.data);
}
输出:
“我妈说,我们属相相克”
我如此平庸,是否可以愉快地生活?
【真相】精神病院的快乐生活
QQ都可以注销了,而我暗恋的那个人却结婚了
2 跨越门槛 (1967—1979 年)
Android2017-2018最新面试题(3-5年经验个人面试经历)
致读者——如何提升自己的口才水平,成为说话高手?
...
想法:解析成千上万的简书的文章的标题,分析一下简书的文章标题是怎样一种"画风"。
- 解析文章发布时间列表:
times = $x('//*[@class="note-list"]/li/div[1]/div[1]/div[1]/span[1]/text()')
for (t of times){
console.log(t.data);
}
输出:
04.07 18:51
03.13 09:26
02.25 16:59
03.24 12:20
03.22 12:19
03.05 15:52
04.03 16:58
...
想法:解析大量(比如10万篇)简书文章的发布时间,统计这些文章发布时间的分布(一天的早中晚或周一到周日的分布),还可以进一步挖掘发布时间与浏览数、点赞数等数据之间的相关关系。
此外,简书首页列表是惰性加载的,可以研究一下怎样爬取这种惰性加载的网页。
解析网易云音乐评论列表
以网易云音乐上的一首歌:平凡之路为例,解析其下面的评论。网易云音乐的歌曲评论分为两种:精彩评论和最新评论,但它们具有相同的HTML结构。
-
地址:http://music.163.com/#/song?id=28815250
-
评论列表总体结构:
-
列表项结构:
-
解析评论内容列表:
comments = $x('//div[@class="cmmts j-flag"]/div[@class="itm"]/div[@class="cntwrap"]/div[1]/div[1]/text()')
for (c of comments){
console.log(c.data);
}
输出:
:去年高考完徒步搭车 川滇 滇藏 青藏线
一个半月
在旅途结束的西宁看了电影
回来单曲循环
16岁便独自搭车川藏线
作为妹子我也真算得上异类
平时不敢听它 一听就想哭想背包出发
现在大一 前几天憋坏了
逃课骑摩托车去了趟川西
奔驰在一望无际大草原柏油公路
单曲循环 平凡之路
放声大唱
你不知道有多自由
:朴树常年低调,但是出的歌都是好歌,去听听他以前的歌,都很好听,都不是那些简简单单的爱来爱去
:无论怎么样非常感谢韩寒的后会无期把朴树拉出来,重新站在大众面前,他还是那个Live会紧张,会发抖,不善言辞的人,但是,一开口,大家都安静了。
:有位自由诗人,他叫许巍;有位孤独诗人,他叫朴树;有位理想诗人,他叫李健;有位摇滚诗人,他叫郑钧。
:昨晚李志跨年,嘉宾竟是朴树!!朴树的牛仔裤外套着一条白出去流苏裙子 一双白色匡威高帮 有胡渣 脸上是沧桑和深沉 很文雅 话筒架的螺丝松了上紧了又松了 他笑了笑 笑的很好看 末尾李逼和朴师傅深情的拥抱 我手机没电了 用手箍了个相框 永远记住
:小野不会嫁给你的
:网易不颁一个年度金曲奖给朴树对得起这评论吗
:小时候跟着父亲去城里卖西瓜,害怕同学会看到我,就拼命地将自己隐藏起来,一路心惊肉跳。现在想来那条路绿树成荫,阳光飒爽,若不是我害怕面对自己的不完美,一定能看到许多美好的景致,那条路,正如其他的所有路,从来都不应该被逃避。
:今天在poetry of rock上放了这首歌,没有翻译,看着全班的老美一个个震惊与沉醉的表情,果然真正的艺术是可以打破语言与国家的界线
:正在看湖南卫视金鹰直播,小朴在唱这首歌,他很紧张,闭着眼,眼皮一直在抖。朴师傅别紧张,你很棒!
:这一个月 是我这半生来 最难熬的日子 今早 4:06分 正式宣布我 个人破产 这一个月的投资 赔了 24万 人生真的就像是赌博 我输了 输的好彻底 没有回旋的余地 听完这首歌 就让一切重新开始吧 ! 你好 明天 你好 未来 你好 自己。
:家人围着6岁的儿子问他的理想,儿子说他想当医生。外婆说医生好,社会地位高。奶奶说待遇也不错。爷爷说除了工资还有其他的收入呢!外公说更重要的是以后找对象方便。爸爸听后,满意地问儿子为什么想当医生。他说:“不是说医生可以治病救人吗?”
:十年前你说生如夏花般绚烂,十年后你说平凡才是唯一的答案.没有经历生如夏花,平凡不是我现在想要的答案.
:可能听了有一千遍。但真的每次都觉得,怎么能那么好。有过很多感慨,也收获过很多能量。刚刚又看了一遍响聊聊那个访谈,其实很多东西是没有变的吧,赤子之心没有变,真实纯粹没有变,不善言辞没有变。时间也让我确定了,为什么喜欢你那么久。
:去年在云南徒步旅行的时候单曲循环平凡之路脚底磨出血还在坚持只因为那句 向前走 就这么走人无执念 难有所成 就算只是走的 平凡之路
:dk
:马上中考了,体育不好,文化课也不好,家人想让我考一高,但我知道考不上,又能怎样。啊啊啊
:我曾经拥有着的一切 转眼间就飘散如烟
:我在学?
:祝福你,如果考上了希望你能记住你说的话。为人民服务,加油!
:但愿会有好运来临!
:今天省考,我心里有梦,我心怀天下,我为什么不去改变自己认为的现有现象,不需要达官显贵,不需要出人头地,不需要名留青史,只要有人记得我,举得我不太一样,觉得这个公务员不错,真为人明服务了,就足够了。周总理是我的偶像,我不能像总理那般风华绝代,一代天骄。我想我能坚持我的良知。
:你会不断的遇见一些人 也会不停的和一些人说再见 从陌生到熟悉 从熟悉再回陌生 从臭味相投到分道扬镳 从相见恨晚到不如不见 所谓生活 一半惊喜一半遗憾
:16年我第一次听到这首歌,当时正经历考试考砸后的调整期,18年还剩下47天高考的时候我再次循环这首歌,虽然当下的境遇和16年如出一辙,但心境大概更加平静了吧(
:最难的日子我都挺过来了,现在我怕什么?
:这首歌应该诠释了我的行业,我跨过山和大海,也穿过人山人海,我踏遍世界各个角落……
:跟一帮志同道合的朋友约好25岁那年去可可西里无人区的,如今当年那些说过誓言的人们,今年7月我在西藏等着你们
:学了好久 今天终于唱了 不一样的感觉
:真么晚了,还在听着平凡之路……
:要活出不一样的自己,
陌生人,
我爱你.
相信自己
别放弃呀.
:我是因为病没考…现在和别人差十分…很难受啊
:三点了给我两个赞可以吗?我不知道是什么让我坚持不睡
:我是真的爱你
:我爱你
:“我曾经跨过山河大海,也穿过人山人海。”那个第一的位置,我看了再看总感觉遥不可及,明明已经努力再努力了,却不及那些可悲之人。不知道在哪本书看到的一句话:“冲淡一切”,克制缺陷就已经很吃力了。
你不知道
我多想证明自己
想法:爬取网易云音乐的热门评论歌曲的评论,绘制每首歌的评论词云。
解析知乎问题回答列表
这里以知乎上的这个问题为例:如何评价朴树的歌曲《平凡之路》?,因为知乎的问题回答很多都有很大篇幅,所以在这里并不去解析答案内容,而是解析问题答案的答主昵称和答案赞数。
- 地址:https://www.zhihu.com/question/24497385
-
问题答案列表总体结构:
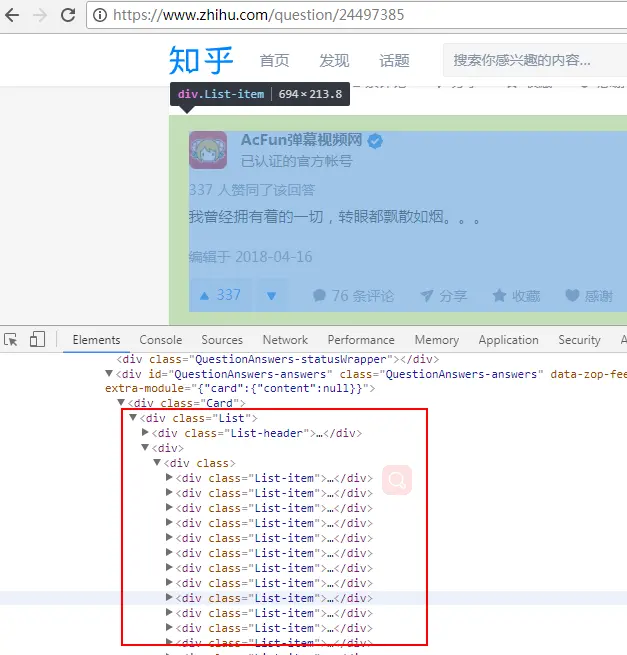
-
问题答案列表项结构:
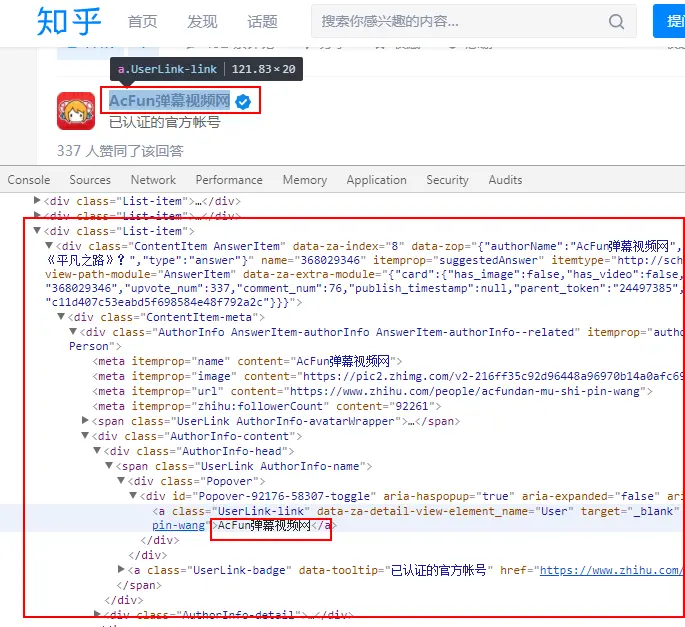
- 解析答案的答主昵称:
nickname_jsons = $x('//div[@class="List"]/div[2]/div[1]/div[@class="List-item"]/div[@class="ContentItem AnswerItem"]/@data-zop')
for(jso of nickname_jsons){
obj = JSON.parse(jso.value); // 把JSON字符串转为对象
console.log(obj.authorName);
}
输出:
七叔
陈壮壮
匿名用户
小愚先声
王晨
穆凡茜
朱雨天
木易movie
AcFun弹幕视频网
苏河
邓柯
Yue Yang
Ronnie X
- 解析答案的赞数:
upvote_jsons = $x('//div[@class="List"]/div[2]/div[1]/div[@class="List-item"]/div[@class="ContentItem AnswerItem"]/@data-za-extra-module')
for(jso of upvote_jsons){
obj = JSON.parse(jso.value); // 把JSON字符串转为对象
console.log(obj.card.content.upvote_num);
}
输出:
2031
170
343
392
177
...
解析新浪微博微博列表
下面来解析一下新浪微博首页的"头条"栏里面的微博列表(未登录的页码)。
- 地址:https://weibo.com/?category=1760
-
微博列表总体结构:
-
微博列表项结构:
- 下面来解析微博的标题列表:
list = $x('//ul[@class="pt_ul clearfix"]/div[@class="UG_list_b"]/div[@class="list_des"]/h3[1]/a[1]/text()')
for(title of list){
console.log(title.textContent);
}
输出:
不管是男团女团,听到“王思聪的公司”的反应都是一模一样的
张翰古力娜扎公布恋情,网友评论“婊子配狗”谢不娶郑爽之恩
央视曝光:饿死不碰这4类食物,每一口离癌都进一步,快点通知父母改!
张翰霸气公布恋情:就你了,傻丫头! 郑爽送祝福!
熊孩子18楼天台玩现实版”跳一跳“,这可是18楼啊!
白百何真是绝了,下面被看得一清二楚,网友:我也看到了 黑的都烂了
张翰公布最新恋情,女友帅气可爱有气质!郑爽娜扎还是另择良偶吧
...
看看微博的"头条"都是这样的一种"画风"。
解析链家网二手房数据列表
下面来解析一下链接网站上的二手房数据,以深圳为例。
- 地址:https://sz.lianjia.com/ershoufang/
-
数据列表总体结构:
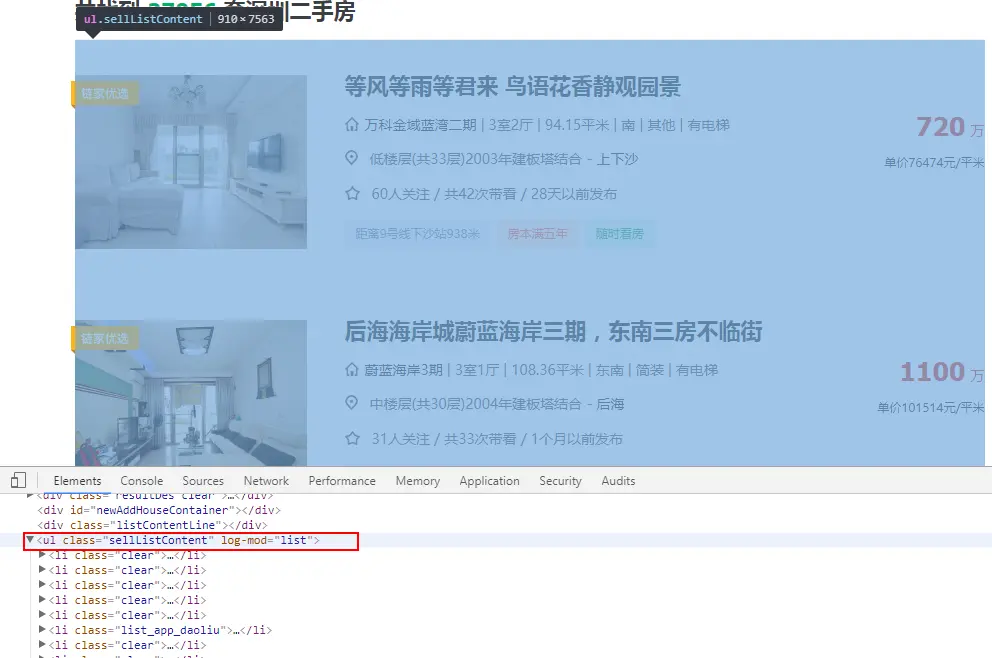
-
列表项结构:
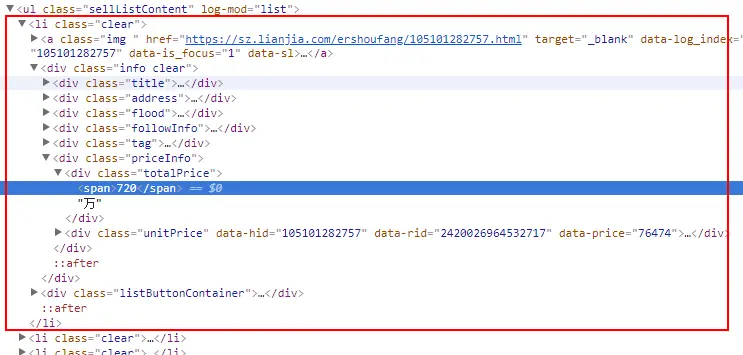
- 从列表项中解析出每条二手房信息的单价:
prices = $x('//ul[@class="sellListContent"]/li/div[@class="info clear"]/div[@class="priceInfo"]/div[@class="unitPrice"]/span/text()');
for (price of prices){
console.log(price.data);
}
输出:
单价76474元/平米
单价101514元/平米
单价61955元/平米
单价91504元/平米
单价68340元/平米
单价57409元/平米
单价51111元/平米
单价93358元/平米
单价68525元/平米
单价56217元/平米
单价69547元/平米
单价59635元/平米
单价100772元/平米
单价60230元/平米
单价55457元/平米
...
这里选取了前15条数据,可以粗略感受一下深圳的房价是个什么水平。
这里有个问题就是,上面获取到的这些房价还不是纯数字,那么怎么进一步解析出纯数字呢?那就要用到js的正则了,下面来继续解析出房价的纯数字:
for (price of prices){
var pattern = /d+/;
console.log(pattern.exec(price.data)[0]);
}
输出:
76474
101514
61955
91504
68340
57409
51111
93358
68525
56217
69547
59635
100772
60230
55457
...
通过使用正则解析,就把房价单价的纯数字解析出来了。
解析智联招聘招聘信息列表
下面解析一下智联招聘网站上的一些招聘数据。
- 地址:http://sou.zhaopin.com/jobs/searchresult.ashx?bj=2071000&in=300500&jl=%E6%B7%B1%E5%9C%B3&sm=0&p=1
这个链接的内容是职位类别为"银行"、行业类别为"银行"、地点为"深圳"的招聘岗位信息。
-
岗位列表总体结构:

-
列表项结构:
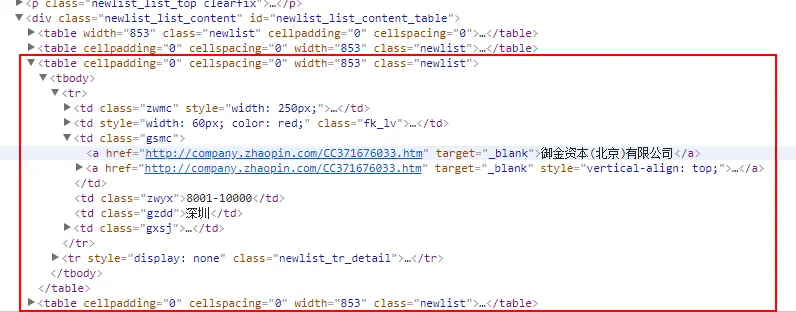
-
下面从每个列表项中解析出公司名称:
posts = $x('//div[@class="newlist_list_content"]/table[position()>1]/tbody/tr[1]/td[3]/a[1]/text()');
for(post of posts){
console.log(post.data);
}
输出:
渣打银行(中国)有限公司深圳分行
御金资本(北京)有限公司
深圳市泽源伟业电子有限公司
中信银行股份有限公司信用卡中心
深圳市泽源伟业电子有限公司
平安普惠投资咨询有限公司深圳雅宝路营业部
中信银行股份有限公司信用卡中心
上海友而信市场信息咨询有限公司深圳第三分公司
中信银行股份有限公司信用卡中心
平安普惠房产服务有限公司深圳梨园路分公司
...
解析猎聘网招聘信息列表
下面解析一下猎聘网上的信息:
- 地址:https://www.liepin.com/zhaopin/?d_sfrom=search_fp_nvbar&init=1
这是猎聘网"职位"首页的地址。
-
职位列表整体结构:
-
职位列表项结构:
- 下面来解析每一个职位的标题:
var posts = $x('//ul[@class="sojob-list"]/li/div[@class="sojob-item-main clearfix"]/div[@class="job-info"]/h3/a/text()');
for(var post of posts){
console.log(post.data.trim());
}
输出:
南宁分公司销售交易部负责人
景观设计师(施工图负责人)
大客户经理
资深商标代理人
HR & Admin Officer 人事行政专员/助理(偏薪酬)
招商主管/渠道销售经理/区域销售主管
网络运维专员
互联网广告销售总监
行政主管
棋牌游戏Java后端工程师
课程设计
...
等等,最后一个"课程设计"是什么鬼???看了详情才知道,这是教育培训机构设计课程的工作,而不是大学中有些课程的大作业的那个"课程设计",此"课程设计"非彼"课程设计"...
解析应届生求职网信息列表
- 地址:http://www.yingjiesheng.com/beijing/
-
列表总体结构:
-
列表项结构:
- 下面解析出职位名称列表:
var posts = $x('//tbody[@id="tb_job_list"]/tr[@class="tr_list"]/td[1]/a/text()');
for (var post of posts){
console.log(post.data);
}
输出:
[北京]博越锦程国际物流(北京)有限公司招聘进出口单证员
[北京]金腾(北京)国际投资咨询有限公司招聘前台接待
[北京]金腾(北京)国际投资咨询有限公司招聘文案助理
[北京]上海客汗网络科技有限公司招聘留学申请指导老师(海归)
[北京]上海客汗网络科技有限公司招聘销售顾问
[北京]深圳市万睿智能科技有限公司招聘设备实习生
[北京|上海]史泰博(上海)有限公司招聘史泰博中国销售培训生(欢迎应届生及2年以内工作经验者)
[北京]金腾(北京)国际投资咨询有限公司招聘市场专员
[北京]深圳市亿科思奇广告有限公司招聘媒介专员
[北京]深圳市亿科思奇广告有限公司招聘广告优化师/信息流优化师
...
解析中国房价行情网历年房价数据
- 地址:http://www.creprice.cn/rank/cityforsale.html?type=11&y=2018&m=3&citylevel=1
-
列表总体结构:
-
列表项结构:
- 解析房价列表:
var datas = $x('//tbody[@id="order_f"]/tr');
for(var tr of datas){
var city = tr.children[1].textContent.trim();
var price = tr.children[2].textContent.trim();
console.log(city + ':' + price);
}
输出:
北京:63,419
重庆:11,049
广州:32,668
上海:52,750
深圳:56,901
天津:25,007
解析淘宝网的信息
下面我们来解析淘宝的一些页面。
- 地址:https://www.taobao.com/
-
打开淘宝首页,发现左侧有一个"主题市场",这里面有很多种主题,那么说干就干,下面把主题市场的所有主题解析出来:

-
主题市场整体结构:
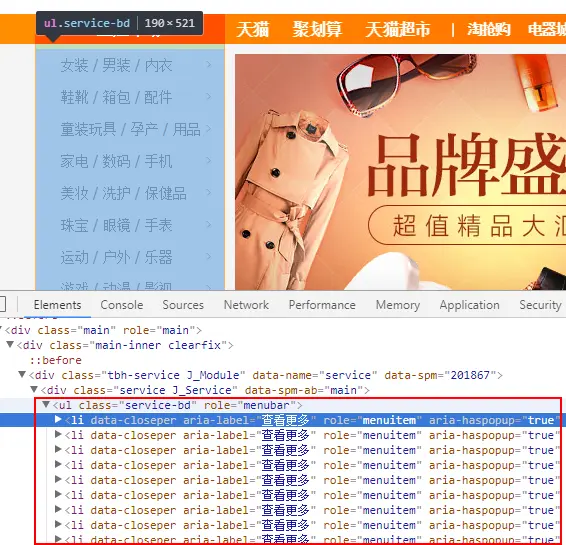
-
每一行的结构:
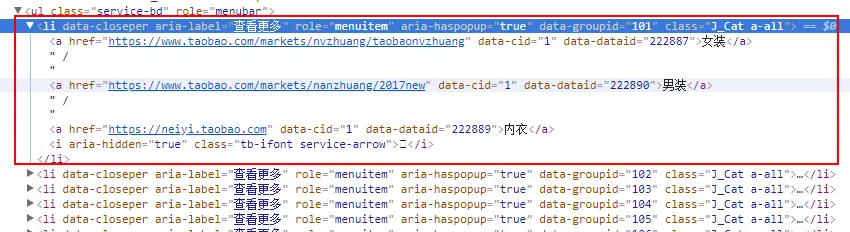
- 解析主题市场的所有主题,不同主题间用分号隔开输出:
var subjects = $x('//div[@class="service J_Service"]/ul[@class="service-bd"]/li/a/text()');
var output = '';
for (var s of subjects){
output = output + s.data + ';';
}
console.log(output);
输出:
女装;男装;内衣;鞋靴;箱包;配件;童装玩具;孕产;用品;家电;数码;手机;美妆;洗护;保健品;珠宝;眼镜;手表;运动;户外;乐器;游戏;动漫;影视;美食;生鲜;零食;鲜花;宠物;农资;房产;装修;建材;家具;家饰;家纺;汽车;二手车;用品;办公;DIY;五金电子;百货;餐厨;家庭保健;学习;卡券;本地服务;
解析京东商品列表
最后来解析一下京东首页的商品列表。
- 地址:https://search.jd.com/Search?keyword=iphonex&enc=utf-8&wq=iphonex
这是在京东首页搜索"iphonex"的结果页地址。
-
下面来解析每一个iPhoneX的价格,商品列表总体结构:
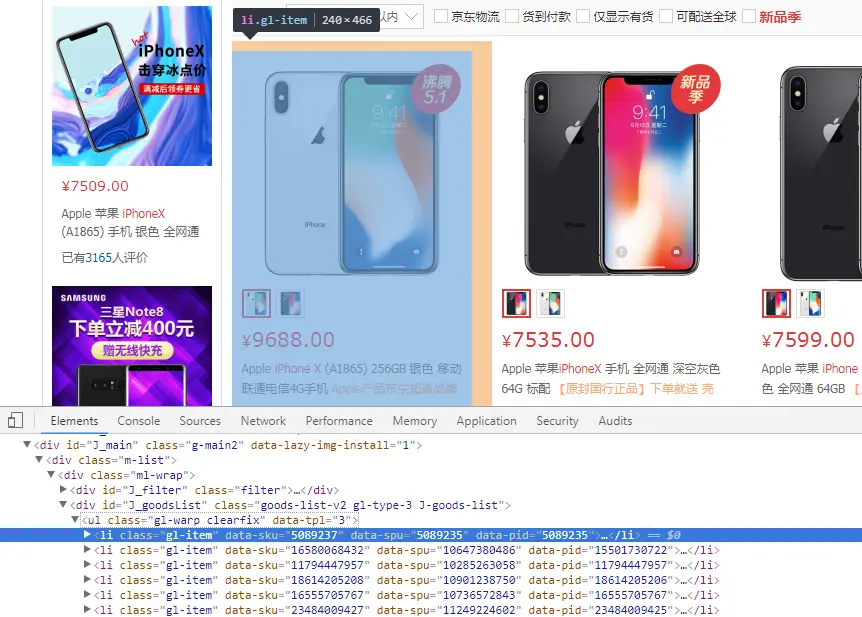
-
列表项结构:
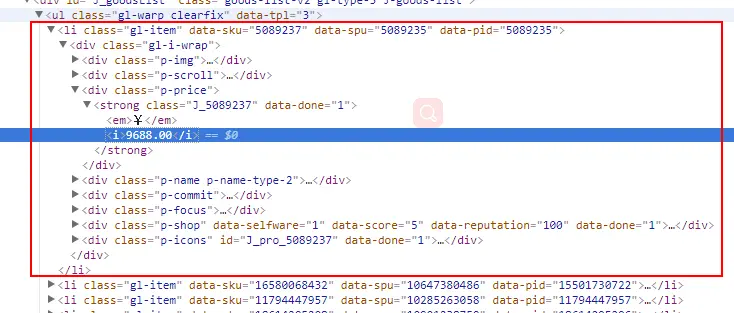
-
解析每一个iPhoneX的价格:
var iphones = $x('//ul[@class="gl-warp clearfix"]/li/div[1]/div[3]/strong/i/text()');
for (var iph of iphones){
console.log(iph.data);
}
输出:
9688.00
7535.00
7599.00
7509.00
8848.00
7515.00
7549.00
7548.00
7513.00
7688.00
...
使用XPath解析网页时的一些心得总结
- 多使用相对路径,而非使用绝对路径。在能确定节点、属性值等定位信息全局唯一的情况下(可以在HTML代码中预先搜索一下),路径范围越小越好。
- XPath表达式中的
text()函数只能用于节点的直接子节点有文本内容的情况,否则是解析不到东西的。 - 在Chrome的console控制台中使用XPath是无法链式调用的,也就意味着无法一次获取一个节点的多个不同属性,不过Python的lxml库是支持XPath链式调用的,也可使用js的DOM元素的方法来获取多个属性。
- 在Chrome中是可以通过审查元素功能直接获取一个页面元素的XPath表达式的,快速准确。
作者:m2fox
链接:https://www.jianshu.com/p/8cfabaf21845
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
最后
以上就是轻松小刺猬最近收集整理的关于使用XPath+Chrome浏览器解析网站的数据准备工作解析各种网站的数据使用XPath解析网页时的一些心得总结的全部内容,更多相关使用XPath+Chrome浏览器解析网站内容请搜索靠谱客的其他文章。








发表评论 取消回复