背景介绍
一年一度的剁手节--双十一又要到了,不知道你们有没有发现一件事情,有许多商品竟然偷偷得涨价了,小编上次看得一双球鞋,才上个月底加入购物车,今天去看的时候竟然发现价格上涨了一百多!这不能忍呀,于是乎,小编就想如果在最低价的时候入手,然后就想到了它--爬虫!闲来无事的我,就开始琢磨起这事......

俗话说,实践出真知~
小编在这给大家安利一套《2020最新企业Pyhon项目实战》视频教程,关注小编私信“01”即可获取,希望大家一起进步哦。
1.导入模块
import urllib.requestimport re2.商品名称填写区域
这里“AJ”只是举个例子,当然也可以输入其他任意商品
keyname="AJ"#输入商品名称key=urllib.request.quote(keyname)3.添加报头
添加报头的目的是模拟浏览器去访问目标网页,这里我用的是火狐浏览器,当然谷歌也可以,但是需要改一下报头信息
headers=("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:80.0) Gecko/20100101 Firefox/80.0")opener=urllib.request.build_opener()opener.addheaders=[headers]urllib.request.install_opener(opener)4.分析商品网页
在京东首页先随便搜一个商品,以“男外套“为例子吧:
这是“男外套”第一页的URL:
'''https://search.jd.com/Search?keyword=%E7%94%B7%E5%A4%96%E5%A5%97&enc=utf-8&pvid=7fd9c2174f0b403da73119cfc5fe2f03'''继续点击第二页、第三页,把对应的URL复制下来进行分析第二页:
'''https://search.jd.com/Search?keyword=%E7%94%B7%E5%A4%96%E5%A5%97&page=3&s=51&click=0'''第三页
'''https://search.jd.com/Search?keyword=%E7%94%B7%E5%A4%96%E5%A5%97&page=5&s=101&click=0'''然后进行分析,在keyword后面更换一下商品名称复制到浏览器中打开,会打开京东商城搜索更换的商品名称的页面。
例如把第三页中的keyword后面的”%E7%94%B7%E5%A4%96%E5%A5%97“这一串字符串换为“女外套”,我们发现商城页面从“男外套”变成了“女外套”并已经进行了搜索
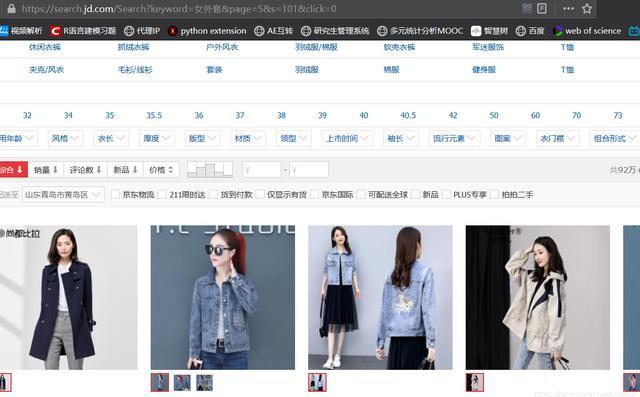
之前复制的第二个和第三个URL“page=”后面分别是3、5,由于搜索商品的页面默认是第一页,复制下来的URL也跟第二页、第三页差别比较大,于是我试着将“page=”后面的数字改为1,发先页面跳到了第一页;于是我们的URL就可以确定了:
url="https://search.jd.com/Search?keyword="+key+"&wq="+key+"&page="+str(i*2-1);然后对页面进行访问并读取编码:
data=urllib.request.urlopen(url).read().decode("utf-8","ignore")5.正则表达式的确定
查看搜索商品页面的源代码,在商品搜索界面先随便复制一张商品图的图像地址,复制在文本中,然后选择复制其中的一段(因为全部复制有可能找不到,实际图片地址和页面源代码里面的图片地址的格式可能不太一样),例如我复制任意一个商品的图片地址中的一段在源代码中进行搜索
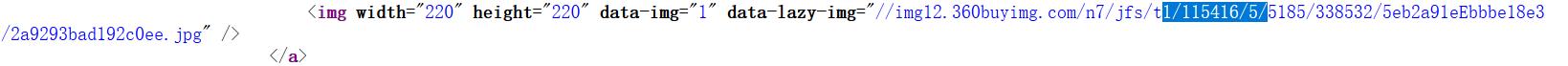
发现商品图片地址前面的标签是“data-lazy-img”然后再在源代码页面搜索此标签,发现"data-lazy-img"标签后面都是商品图片的图片地址,于是可以设置正则表达式:
pat='data-lazy-img="(.*?)"'然后再进行:
imagelist=re.compile(pat).findall(data)6.大图的爬取(之前的图片地址是小图)
先在搜索页面复制一张图片的地址到文本,然后再点进商品,去查看大图,再复制商品图片的地址到文本,进行分析,例如
小图图片地址'''https://img14.360buyimg.com/n7/jfs/t1/112463/24/19126/94054/5f7199a9E0a24e8f5/21931f19ee2f4874.jpg'''大图图片地址'''https://img14.360buyimg.com/n0/jfs/t1/112463/24/19126/94054/5f7199a9E0a24e8f5/21931f19ee2f4874.jpg'''从上图的地址分析得到只有一处不一样,那就是/n7和/n0,于是需要把爬取出来的字符串中的“/n7”换为"/n0":
b1=imagelist[j].replace('/n7', '/n0')注意:爬取的图片地址直接是打不开的,需要在前面加个“http:”
newurl="http:"+b1以下是此程序的完整代码:
import urllib.requestimport rekeyname="AJ"#输入商品名称key=urllib.request.quote(keyname)headers=("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:80.0) Gecko/20100101 Firefox/80.0")opener=urllib.request.build_opener()opener.addheaders=[headers]urllib.request.install_opener(opener)for i in range(1,10): url="https://search.jd.com/Search?keyword="+key+"&wq="+key+"&page="+str(i*2-1); data=urllib.request.urlopen(url).read().decode("utf-8","ignore") pat='data-lazy-img="(.*?)"' imagelist=re.compile(pat).findall(data) for j in range(0,len(imagelist)): b1=imagelist[j].replace('/n7', '/n0') print("第"+str(i)+"页第"+str(j)+"张爬取成功") newurl="http:"+b1 file="E:/新建文件夹/AJ/"+"第"+str(i)+"页第"+str(j)+"张"+".jpg"#file指先在指定文件夹里建立相关的文件夹才能爬取成功 urllib.request.urlretrieve(newurl, filename=file)结语
最后多说一句,小编是一名python开发工程师,这里有我自己整理了一套最新的python系统学习教程,包括从基础的python脚本到web开发、爬虫、数据分析、数据可视化、机器学习等。想要这些资料的可以关注小编,并在后台私信小编:“01”即可领取。
本文的文字及图片来源于网络加上自己的想法,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
最后
以上就是温暖西牛最近收集整理的关于爬取京东具体商品页面_双十一来临!如何用Python得出京东商品最低价格背景介绍1.导入模块2.商品名称填写区域3.添加报头4.分析商品网页5.正则表达式的确定6.大图的爬取(之前的图片地址是小图)结语的全部内容,更多相关爬取京东具体商品页面_双十一来临!如何用Python得出京东商品最低价格背景介绍1.导入模块2.商品名称填写区域3.添加报头4.分析商品网页5.正则表达式内容请搜索靠谱客的其他文章。








发表评论 取消回复