巨潮资讯网年报爬虫
- 代码直接复制即可使用
- 这是一个Post请求爬虫,与Get请求存在一点小区别,不过核心思想是一致的
Tips: - 需要在py文件夹目录下,新建一个“年报”名称的文件夹,存放下载的报表
- 同时在py文件夹目录下,需要一个stockcode.xlsx文件,里面是需要爬取的公司代码,格式如图所示,其中公司代码需要为字符型,数字型的保存会有问题(000520会变成520)
- B站视频讲解
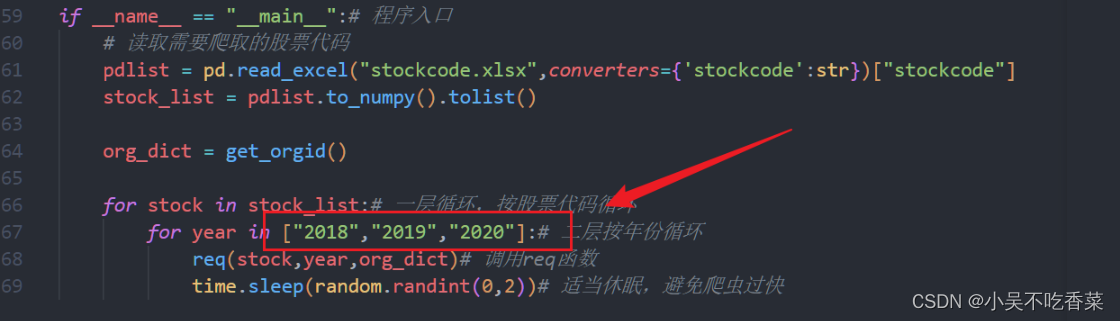
- 在代码中这个位置可以根据需要调整爬取年份
'''
由于数据量较大,建议将数据分成几组,多次爬虫,避免一次爬虫过程中,爬虫时间较长,出现意外情况而未能保存数据
'''
import requests,time,random,json
import pandas as pd
def req(stock,year,org_dict):
# post请求地址(巨潮资讯网的那个查询框实质为该地址)
url = "http://www.cninfo.com.cn/new/hisAnnouncement/query"
# 表单数据,需要在浏览器开发者模式中查看具体格式
data = {
"pageNum":"1",
"pageSize":"30",
"tabName":"fulltext",
"stock":stock + "," + org_dict[stock] ,# 按照浏览器开发者模式中显示的参数格式构造参数
"seDate":f"{str(int(year)+1)}-01-01~{str(int(year)+1)}-12-31",
"column":"szse",
"category":"category_ndbg_szsh",
"isHLtitle": "true",
"sortName":"time",
"sortType": "desc"
}
# 请求头
headers = {"Content-Length": "201","Content-Type":"application/x-www-form-urlencoded"}
# 发起请求
req = requests.post(url,data=data,headers=headers)
if json.loads(req.text)["announcements"]:# 确保json.loads(req.text)["announcements"]非空,是可迭代对象
for item in json.loads(req.text)["announcements"]:# 遍历announcements列表中的数据,目的是排除英文报告和报告摘要,唯一确定年度报告或者更新版
if "摘要" not in item["announcementTitle"]:
if "英文" not in item["announcementTitle"]:
if "修订" in item["announcementTitle"] or "更新" in item["announcementTitle"]:
adjunctUrl = item["adjunctUrl"] # "finalpage/2019-04-30/1206161856.PDF" 中间部分便为年报发布日期,只需对字符切片即可
pdfurl = "http://static.cninfo.com.cn/" + adjunctUrl
r = requests.get(pdfurl)
f = open("年报" +"/"+ stock + "-" + year + "年度报告" + ".pdf", "wb")
f.write(r.content)
print(f"{stock}-{year}年报下载完成!") # 打印进度
break
else:
adjunctUrl = item["adjunctUrl"] # "finalpage/2019-04-30/1206161856.PDF" 中间部分便为年报发布日期,只需对字符切片即可
pdfurl = "http://static.cninfo.com.cn/" + adjunctUrl
r = requests.get(pdfurl)
f = open("年报" +"/"+ stock + "-" + year + "年度报告" + ".pdf", "wb")
f.write(r.content)
print(f"{stock}-{year}年报下载完成!") # 打印进度
break
# 该函数主要是通过http://www.cninfo.com.cn/new/data/szse_stock.json该json数据,找到每个stock对应的orgid,并存储在字典org_dict中
def get_orgid():
org_dict = {}
org_json = requests.get("http://www.cninfo.com.cn/new/data/szse_stock.json").json()["stockList"]
for i in range(len(org_json)):
org_dict[org_json[i]["code"]] = org_json[i]["orgId"]
return org_dict
if __name__ == "__main__":# 程序入口
# 读取需要爬取的股票代码
pdlist = pd.read_excel("stockcode.xlsx",converters={'stockcode':str})["stockcode"]
stock_list = pdlist.to_numpy().tolist()
org_dict = get_orgid()
for stock in stock_list:# 一层循环,按股票代码循环
for year in ["2018","2019","2020"]:# 二层按年份循环
req(stock,year,org_dict)# 调用req函数
time.sleep(random.randint(0,2))# 适当休眠,避免爬虫过快
最后
以上就是曾经大碗最近收集整理的关于巨潮资讯网年报爬虫巨潮资讯网年报爬虫的全部内容,更多相关巨潮资讯网年报爬虫巨潮资讯网年报爬虫内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复