本期来学习下正则表达式,之前学习了requests模块(https://blog.csdn.net/weixin_44526949/article/details/86684091),requests模块相比urllib模块,在很多方面都显得非常简洁,可以说是urllib模块的一个升华。那么什么是正则表达式呢?简单来说,正则表达式是对字符串操作的一种逻辑公式,就是事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。正则表达式的应用非常广泛,而且在很多编程语言中都是必不可少的技术,在目前比较火的人工智能领域,尤其是自然语言处理领域,这种技术是一个从业人员必须要掌握的一门技术,熟练的掌握正则表达式,可以给我们的研究工作带来很大的方便。关于正则表达式的学习,可以参考这个网址(http://tool.oschina.net/regex/#)。
re.match
re.match尝试从字符串的起始位置 匹配一个模式,如果不是起始位置匹配成功的话,match()就返回None。
re.match(pattern,string,flags=0)
基本匹配
import re
content = "Hello 123 4567 World_This is a Regex Demo"
print(len(content))
result = re.match("^Hellosd{3}sd{4}sw{10}.*Demo$",content)
print(result)
print(result.group()) # 返回匹配的结果
print(result.span()) # 输出匹配结果的范围这是对content内容的一个完全匹配,这是一个最基本的匹配。
下面来做一个泛匹配:
import re
content = "Hello 123 4567 World_This is a Regex Demo"
result = re.match("Hello.*Demo$",content)
print(result)
print(result.group())
print(result.span())下面来实现一个对指定目标的匹配,如果我们想获得匹配结果中的要获得的内容可以加个(),比如获取1234567这个目标结果:
import re
content = "Hello 1234567 World_This is a Regex Demo"
result = re.match("Hellos(d+)sWorld.*Demo$",content)
print(result)
print(result.group(1)) # 把模式中第一个加了括号的匹配到的内容输出来
print(result.span())贪婪匹配,所谓的贪婪匹配指的是,对于给定的模式,尽可能多的匹配内容:
import re
content = "Hello 1234567 World_This is a Regex Demo"
result = re.match("He.*(d+).*Demo$",content)
print(result)
print(result.group(1))

可以看到,只输出了最后的数字7,这是因为,由于".*"是贪婪匹配,它会把“123456和前面的"Hello"匹配到一块,因为这样才能保证".*"匹配到最多的字符。而后面的".*"是同样的道理,(d+)表示至少要匹配一个数字,这样理所当然的只能得到结果为仅一个数字7。
非贪婪匹配,自然指的是,对于给定的模式,尽可能少的匹配内容:
import re
content = "Hello 1234567 World_This is a Regex Demo"
result = re.match("He.*?(d+).*Demo$",content)
print(result)
print(result.group(1))
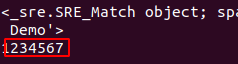
由于?是非贪婪匹配,而?好之后又是匹配数字,因此非贪婪匹配会尽量少的匹配非数字,而".*"是贪婪匹配,所以?会将第一个数字1之前的字符匹配到一块,而group(1)表示要匹配带第一个加了括号的内容(即数字),因此输出结果为1234567
转义:
对于特殊符号,比如$、?...这类符号要匹配的话,要在符号前面加一个""。
import re
content = "price is $10.00"
result = re.match("price is $10.00",content)
print(result)总之,尽量使用泛匹配、使用括号得到匹配目标、尽量使用非贪婪模式。另外re.match太过依赖于第一个字符,在使用时不太方便,比如:
import re
content = "Machine Learning is very interesting"
# 尝试从中间进行匹配
result = re.match("Learning.*",content)
print(result)![]()
由于开头不匹配,所以返回None
因此,下面来学习re.search
re.search
re.search扫描整个字符串并返回第一个成功的匹配。
import re
content = "Machine Learning is very interesting"
# 尝试从中间进行匹配
result = re.search("Learning.*",content)
print(result)![]()
可以看到,成功匹配并且返回了匹配的结果。
因此,一般最好使用re.search。
re.sub
re.sub的作用是替换字符串中每一个匹配的子串后返回替换后的字符串。
import re
content = "Computer Science is so interesting 太666了。"
new_content = re.sub("d+","good",content)
print(new_content)![]()
但是,如果要替换的内容包括字符串本身,如新替换的内容,是在原来的基础上添加额外的字符,比如”666“替换为"666 nice",此时可以进行如下操作:
import re
content = "Computer Science is so interesting 太666了。"
new_content = re.sub("(d+)",r'1 nice',content)
print(new_content)![]()
这里的'1'表示把第1个括号中的内容拿过来进行替换。
re.compile
将正则字符串编译成正则对象,以便于复用该匹配模式。
import re
content = """Hello 1234567 World_This
is a Regex Demo"""
# re.S表示“.”(不包含外侧双引号,下同)的作用扩展到整个字符串,包括“n”。
pattern = re.compile("Hello.*Demo",re.S)
result = re.match(pattern,content)
print(result)![]()
总之,正则表达式博大精深,要想融会贯通,所需要做的就是反复理解和练习。
最后
以上就是开放微笑最近收集整理的关于网络爬虫学习(八)的全部内容,更多相关网络爬虫学习(八)内容请搜索靠谱客的其他文章。








发表评论 取消回复