注:本博客跟随此网络爬虫教程进行学习,有兴趣可以学习一下。
老规矩先上框架图:
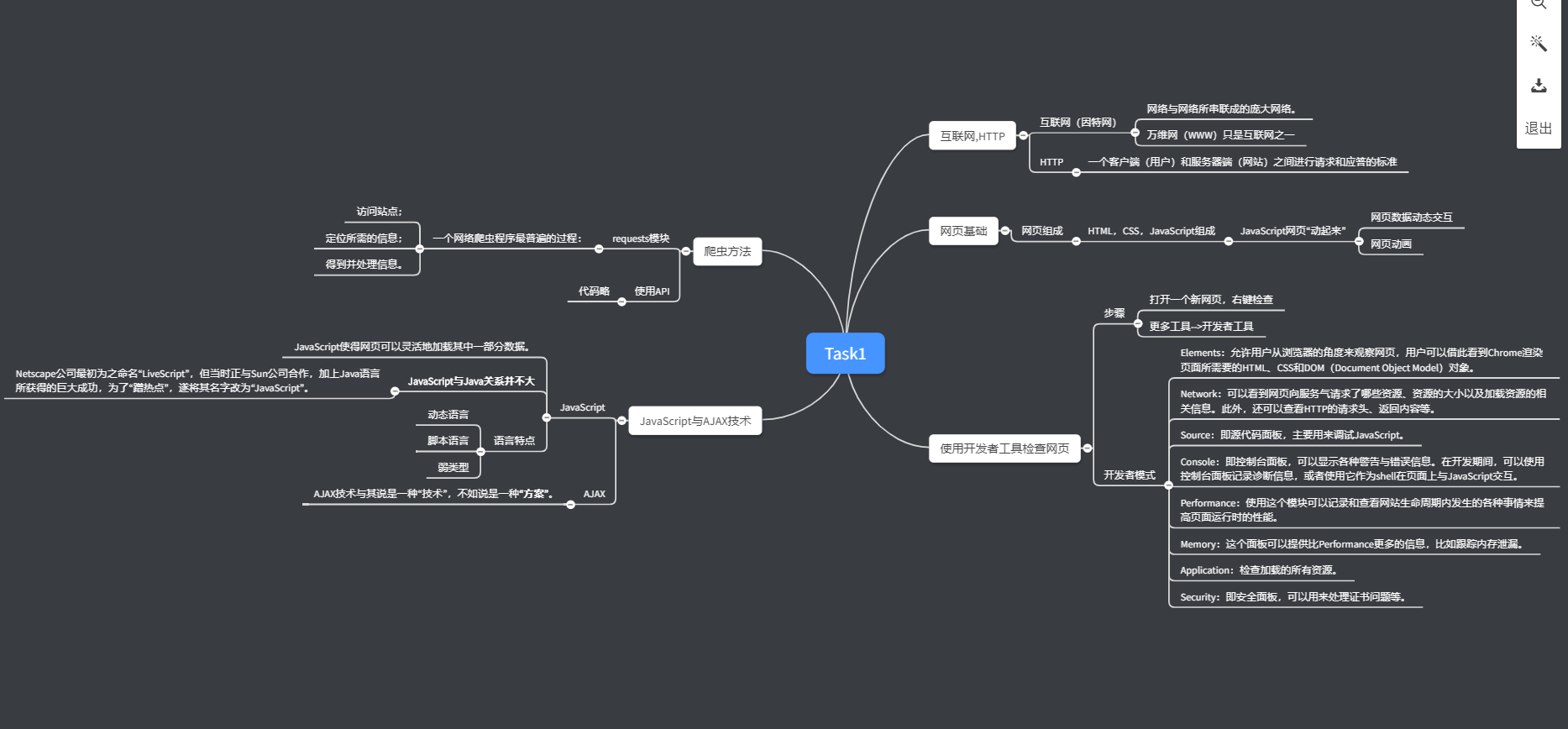
理论部分
互联网,HTTP
- 互联网(因特网)
- 网络与网络所串联成的庞大网络。
- 万维网(WW是互联网之一
- HTTP
- 一个客户端(用户)和服务器端(网站)之间进行请求和应答的标准
- 网页基础
- 网页组成
- HTML,CSS,JavaScript组成
- JavaScript网页“动起来”
- 网页数据动态交互
- 网页动画
- JavaScript网页“动起来”
- HTML,CSS,JavaScript组成
- 网页组成
- 使用开发者工具检查网页
- 步骤
- 打开一个新网页,右键检查
- 更多工具–>开发者工具
- 开发者模式
- Elements:允许用户从浏览器的角度来观察网页,用户可以借此看到Chrome渲染页面所需要的HTML、CSS和DOM(Document Object Model)对象。
- Network:可以看到网页向服务气请求了哪些资源、资源的大小以及加载资源的相关信息。此外,还可以查看HTTP的请求头、返回内容等。
- Source:即源代码面板,主要用来调试JavaScript。
- Console:即控制台面板,可以显示各种警告与错误信息。在开发期间,可以使用控制台面板记录诊断信息,或者使用它作为shell在页面上与JavaScript交互。
- Performance:使用这个模块可以记录和查看网站生命周期内发生的各种事情来提高页面运行时的性能。
- Memory:这个面板可以提供比Performance更多的信息,比如跟踪内存泄漏。
- Application:检查加载的所有资源。
- Security:即安全面板,可以用来处理证书问题等。
- 步骤
- 爬虫方法
- requests模块
- 一个网络爬虫程序最普遍的过程:
- 访问站点;
- 定位所需的信息;
- 得到并处理信息。
- 一个网络爬虫程序最普遍的过程:
- 使用API
- 代码略
- requests模块
- JavaScript与AJAX技术
- JavaScript
- JavaScript使得网页可以灵活地加载其中一部分数据。
- JavaScript与Java关系并不大
- Netscape公司最初为之命名“LiveScript”,但当时正与Sun公司合作,加上Java语言所获得的巨大成功,为了“蹭热点”,遂将其名字改为“JavaScript”。
- 语言特点
- 动态语言
- 脚本语言
- 弱类型
- AJAX
- AJAX技术与其说是一种“技术”,不如说是一种“方案”。
- JavaScript
代码部分
1.使用API
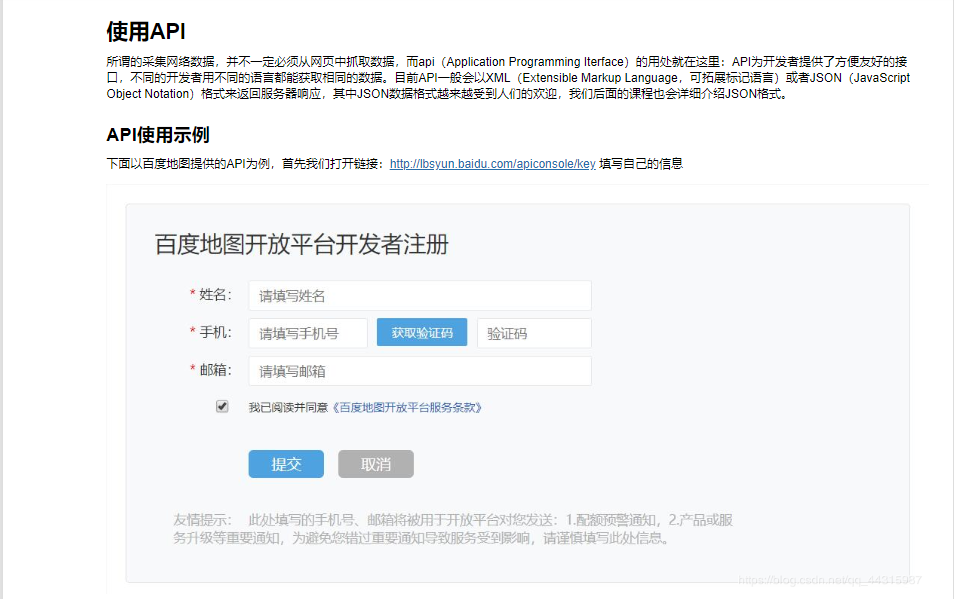
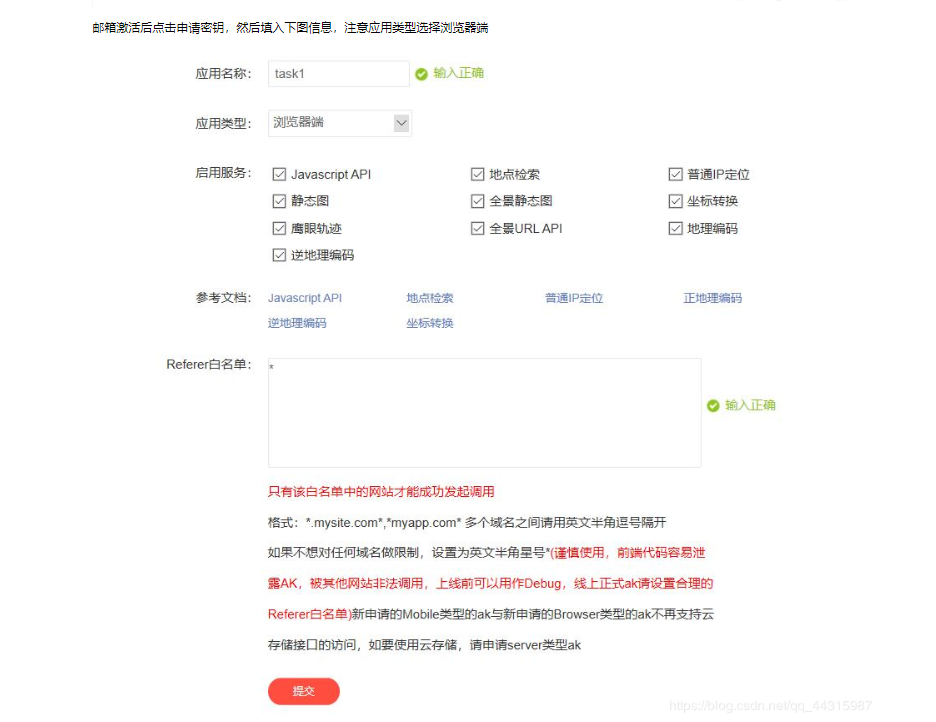
邮箱激活后,就有自己的ak了
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<meta name="viewport" content="initial-scale=1.0, user-scalable=no" />
<style type="text/css">
body,
html,
#allmap {
width: 100%;
height: 100%;
overflow: hidden;
margin: 0;
font-family: "微软雅黑";
}
</style>
<script type="text/javascript" src="http://api.map.baidu.com/api?v=3.0&ak=//写自己的ak"></script>
<title>地图展示</title>
</head>
<body>
<div id="allmap"></div>
</body>
</html>
<script type="text/javascript">
// 百度地图API功能
var map = new BMap.Map("allmap"); // 创建Map实例
map.centerAndZoom(new BMap.Point(116.404, 39.915), 11); // 初始化地图,设置中心点坐标和地图级别
//添加地图类型控件
map.addControl(new BMap.MapTypeControl({
mapTypes: [
BMAP_NORMAL_MAP,
BMAP_HYBRID_MAP
]
}));
map.setCurrentCity("北京"); // 设置地图显示的城市 此项是必须设置的
map.enableScrollWheelZoom(true); //开启鼠标滚轮缩放
</script>
结果如下:

2.使用Python request进行爬虫
import requests
import urllib
url='https://www.python.org/dev/peps/pep-0020/'
res=requests.get(url)
text=res.text
#print(text)
# 爬取Python之禅并存到txt文件
with open('zon_of_python.txt','w') as f:
f.write(text[text.find('<pre')+28:text.find('</pre>')-1])
print(text[text.find('<pre')+28:text.find('</pre>')-1])
res2=urllib.request.urlopen(url).read().decode('utf-8')
print(res2[res2.find('<pre')+28:res2.find('</pre>')-1])
def translate(word):
url="http://fy.iciba.com/ajax.php?a=fy"
data={
'f':'auto',
't':'auto',
'w':word,
}
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36',
}#User-Agent会告诉网站服务器,访问者是通过什么工具来请求的,如果是爬虫请求,一般会拒绝,如果是用户浏览器,就会应答。
response=requests.post(url,data=data,headers=headers)#发送请求
json_data=response.json()#获取json数据
return json_data
def run(word):
result=translate(word)['content']['out']
print(result)
return result
def main():
with open('zon_of_python.txt') as f:
zh=[run(word) for word in f]
with open('zon_of_python-CH.txt','w') as g:
for i in zh:
g.write(i+'n')
if __name__ == '__main__':
main()
结果如下:
爬取的是https://www.python.org/dev/peps/pep-0020/里的python之禅
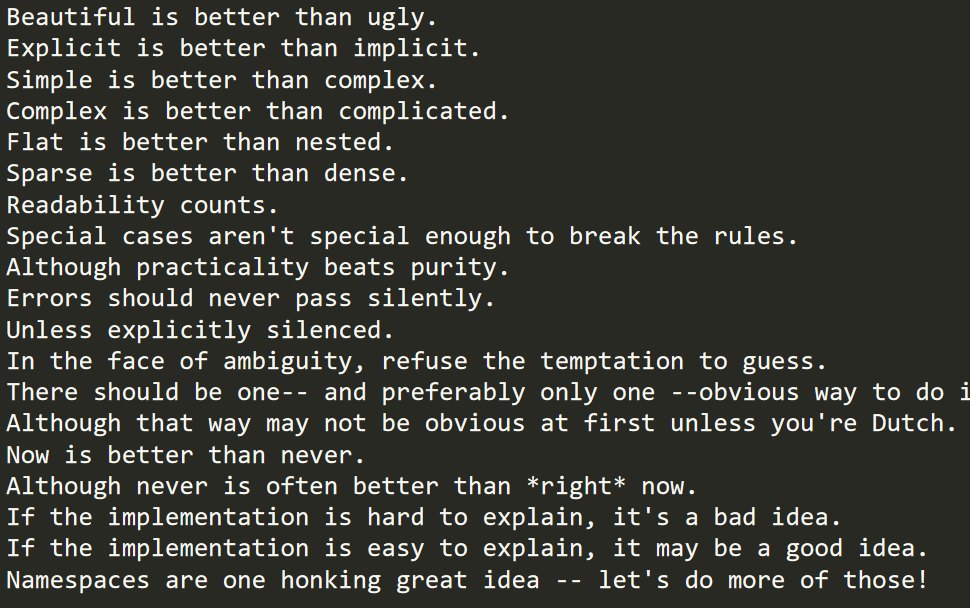
最后
以上就是快乐大侠最近收集整理的关于网络爬虫学习---第一期的全部内容,更多相关网络爬虫学习---第一期内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复