Python使用Requests和bs4来分析网页
PS: 也是从网上各个帖子中学习的Python,因此代码的格式以及内容有粘贴网上其他大神的代码,如有侵权请告知删除
以电影天堂为例
目的:爬取距今为之两周以内的电影链接
1 首先要找出主页和子页之间的关系
在网站中点击“最新电影”,会呈现多页电影列表,如图:
 分别对比首页,以及第二页,第三页的网址可知到
分别对比首页,以及第二页,第三页的网址可知到
第一页:‘https://www.dytt8.net/html/gndy/dyzz/index.html’
第二页:‘https://www.dytt8.net/html/gndy/dyzz/list_23_2.html’
第三页:‘https://www.dytt8.net/html/gndy/dyzz/list_23_3.html’
所以可以用以下代码来记录网址
for page in range(1, 3):
if page == 1:
index = 'index'
else:
index = 'list_23_' + str(page)
url = 'https://www.dytt8.net/html/gndy/dyzz/' + index + '.html'2 获取网页内容
首先要用requests获取网页内容,然后利用bs4进行分析
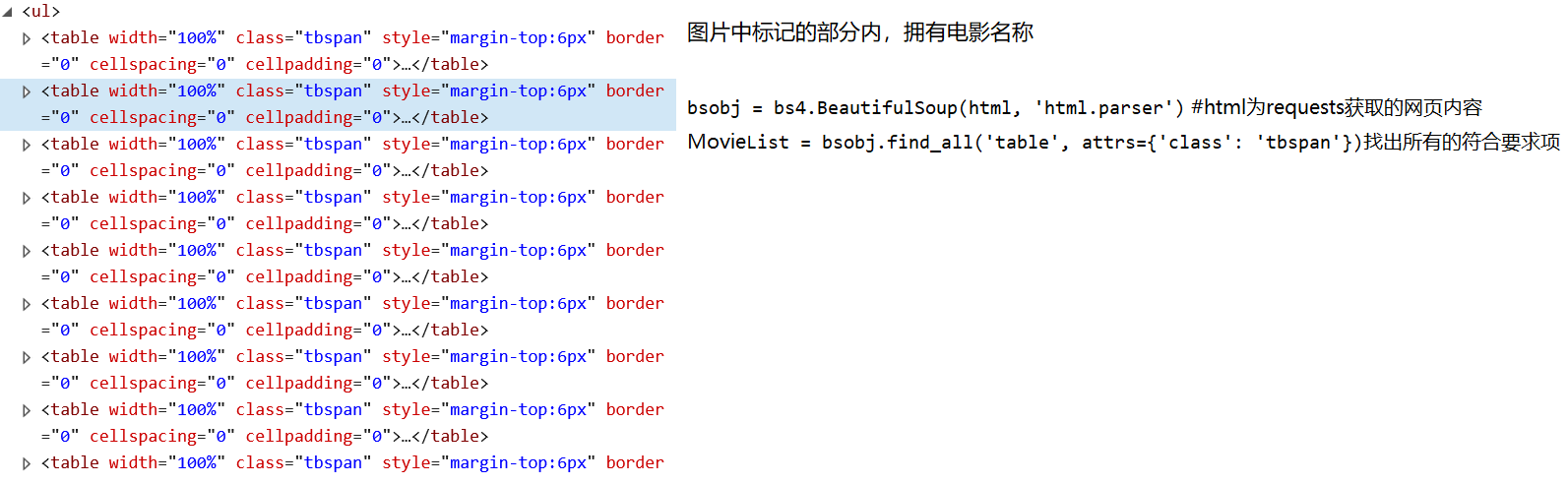
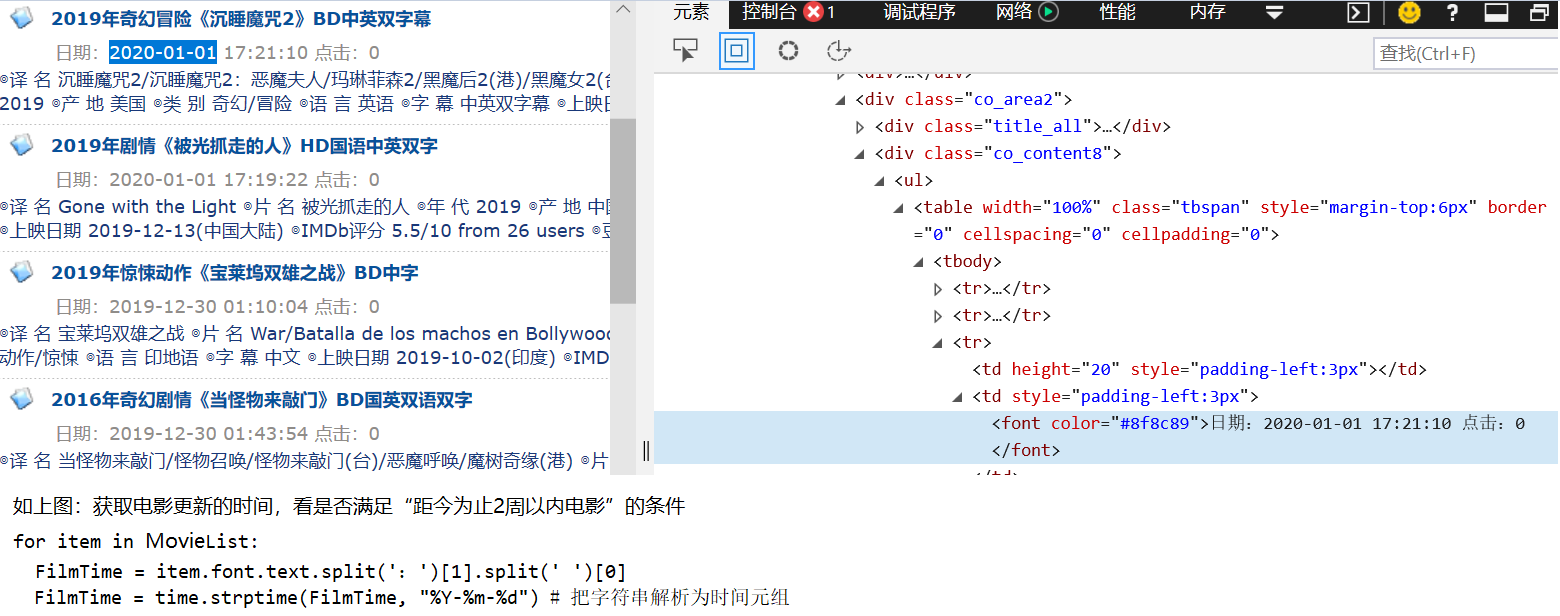
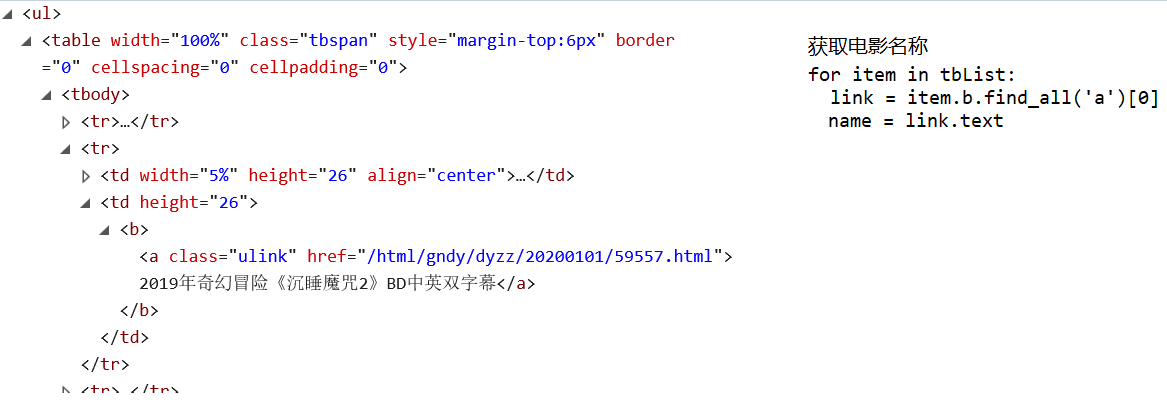
3 要想获取电影的链接,必须点击对应的电影名称,进入到下一个网页中,因此需要知道每个电影名称对应的下一个下载页面网址是什么
经查看可知,每一个电影的下载网址页面为:
url = ‘https://www.dytt8.net’ + link[“href”](上图中href的部分)
4 想要获取电影链接,需要对3中每个电影的url进行解析
当点击电影名称,进入到下载页面的时候,如图:
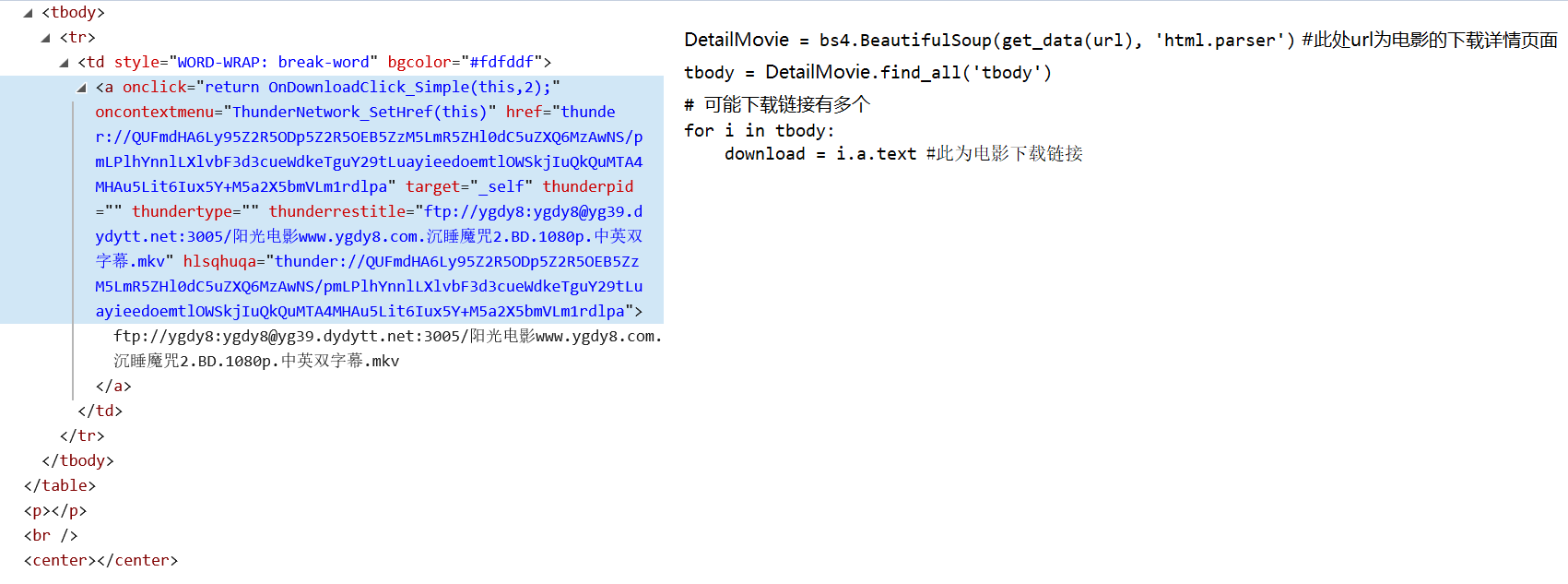
最后
以上就是发嗲盼望最近收集整理的关于Python使用Requests和bs4来分析网页Python使用Requests和bs4来分析网页的全部内容,更多相关Python使用Requests和bs4来分析网页Python使用Requests和bs4来分析网页内容请搜索靠谱客的其他文章。








发表评论 取消回复