这是本人第 2 篇博客,也是爬虫系列的第 1 篇博客。
爬虫是我很早之前就开始接触的工具,主要用于爬取新浪财经的数据,毕竟当时没有Wind账号,找起数据很苦逼,只能自立更生。接下来一年左右,个人自由时间较为宽裕,想利用这段时间将自己的编程技能体系化,爬虫是我梳理的第一大部分,记录在此,供自己日后查阅,也希望可以帮助新入门者少走一些弯路。
注:爬虫系列所有案例仅供个人学习使用。
- 文章概要:本文将以链家北京租房信息页面爬取为例,重点介绍如何通过re、bs4、xpath三种方式解析网页内容;网页分析、数据存读等方面会简化处理,一带而过;
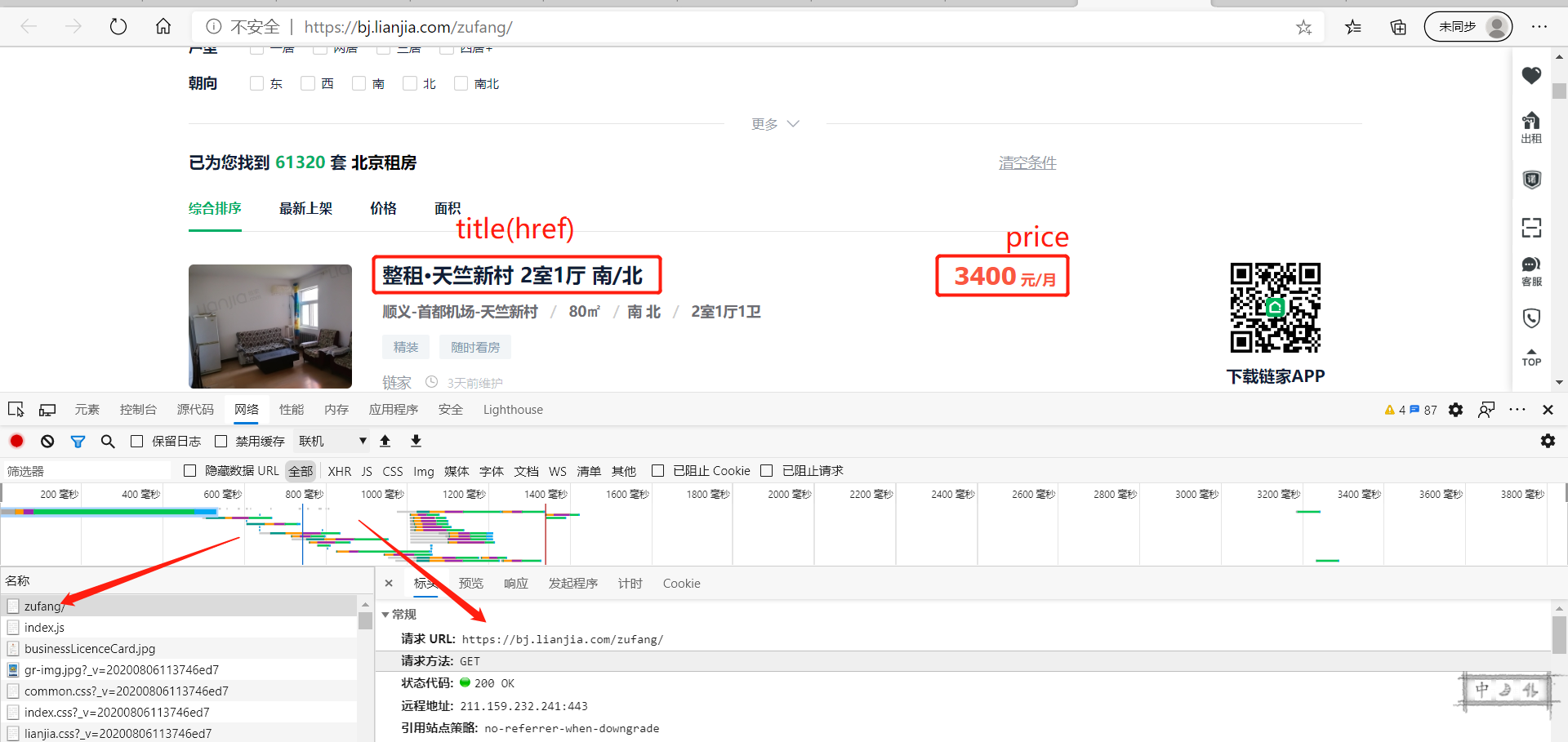
- 明确需求:抓取下图的房源名称title,租金price,以及点击后进入的房源详情页的链接href;
文章目录
- 1、网页内容获取
- 2、re
- 3、bs4
- 4、xpath
- 5、结果与总结
1、网页内容获取
首先,打开链家租房信息网页,按F12进入“检查”,可以发现获取页面信息所需操作较为简单,直接上代码(注:需要加cookie,否则爬取到的内容与在浏览器中看到的并不一致)。
import pandas as pd
import requests
from fake_useragent import UserAgent
import re
from bs4 import BeautifulSoup
from lxml import etree
def get_page(url):
'''获取页面内容'''
headers = {
'User-Agent': UserAgent().random, # 生成随机useragent,太方便了
'Cookie': cookie
}
page_text = requests.get(url=url, headers=headers).text
return page_text
2、re
正则表达式,最开始接触是因为excel,它的语法实在太多太麻烦,个人觉着对于非专业人士,没必要死磕非要记住所有。要是实在想学,可以点击菜鸟教程正则表达式教程学习。
理论概述:对于只注重应用的我们来说,会用 .*? 组合再加括号()和re.S就可以应对绝大多数情况。1) 点 . 表示匹配换行符 n 之外的任意单个字符,星号 * 表示前面的子表达式匹配任意多次(包括0次),? 表示匹配前面的子表达式0次或1次,起到非贪婪模式的作用。三者组合在一起,就能匹配任意类型的字符,并且当字符满足该组合之后的表达式时,停止匹配。2) 括号可以标记我们实际要抓取的内容。3) re.S 会将字符串看做一个整体,不理会换行符,没什么意外,就加上吧。下面会结合title以及href的匹配进行讲解。
常用函数:
re.compile(pattern, re.S) # 这是常用格式,相当于创建匹配模板,便于调用
re.findall(pattern, text) # 从text中依据创建的模板进行匹配,以list形式返回
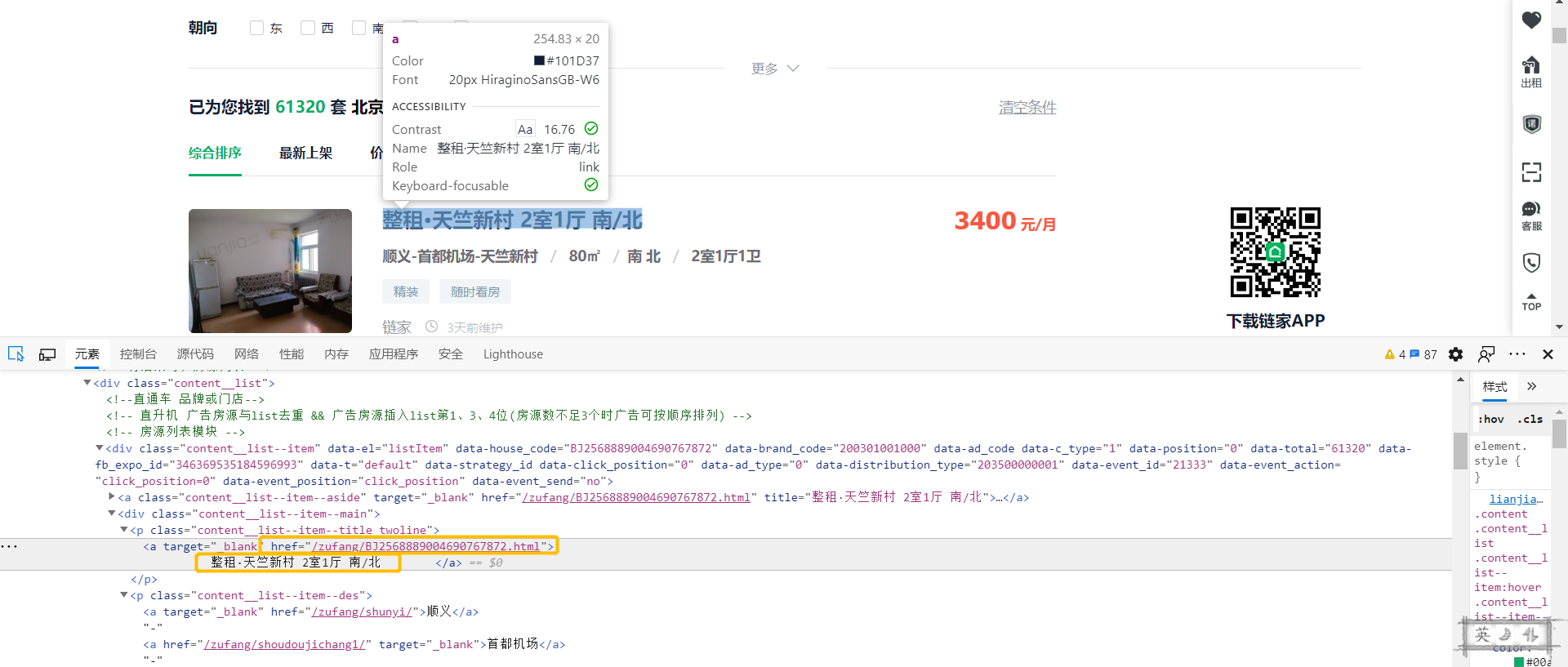
实例讲解 :先看title“整租·天竺新村 2室1厅 南/北 ”是被包在a标签中,但a标签千千万,要精准定位到心仪的a标签,就要往它的上级去找找看。经查证,p标签尤其是它的class值得信赖,借助它进行定位。可以发现被 > 和 </ a> 包着的就是我们要的,加上括号。定位到p标签后,href就具有辨识度了,借助href="(.*?)" 匹配到href的内容。简而言之,只要把要匹配位置的前后内容(比如 > 、</ a> )和标志性字符(比如p标签的class)清晰明了的打出来,中间加上(.*?)就可以了。
<p class="content__list--item--title twoline">
<a target="_blank" href="/zufang/BJ2568889004690767872.html">
整租·天竺新村 2室1厅 南/北 </a>
</p>
pattern_title = re.compile('<p class="content__list--item--title twoline">.*?>(.*?)</a>', re.S)
pattern_href = re.compile('<p class="content__list--item--title twoline">.*?href="(.*?)">', re.S)
def parse_re(page_text):
''''利用re 进行网页解析'''
pattern_title = re.compile('<p class="content__list--item--title twoline">.*?>(.*?)</a>', re.S)
pattern_href = re.compile('<p class="content__list--item--title twoline">.*?href="(.*?)">', re.S)
pattern_price = re.compile('<span class="content__list--item-price"><em>(.*?)</em>', re.S)
title = re.findall(pattern_title, page_text)
href = re.findall(pattern_href, page_text)
price = re.findall(pattern_price, page_text)
title = [i.strip() for i in title]
href = ['https://bj.lianjia.com/' + i.strip() for i in href]
price = [i.strip() for i in price]
result = dict(title=title, href=href, price=price)
return result
3、bs4
利用bs4进行解析,常用解析方式是 lxml ,先创建一锅汤soup,之后定位到标签,再获取标签的内容或属性。
定位到标签大致有两个思路:1) find系列,常用函数find(只查找第一个), find_all(查找到所有,list形式);2) select系列,可点击在线教程进行详细学习,和re一样,并不需要全部掌握,记住常用的标签选择器(a)、类选择器(.)、id选择器(#)、层级选择器(空格 >)就基本够用了,这些解决不了就去查查教程。
# find 系列
soup.find(标签, 属性值) # 选到具有特定属性值的标签,传递方式分两种
soup.find('p', id=id)
soup.find('p', class_=class) # 注意class后面要加下划线
soup.find('p', attrs={属性名: 属性值}) # 注:字典形式
soup.find_all(标签, 属性值) # 同find一样
# select 系列
soup.select('div .class > p ') # 找到类别为class的div标签,进一步找到div标签的所有 p 子标签
soup.select('div[属性名=属性值] > p') # 注意属性相关不用加引号,与xpath有区别
soup.select('div[title=titlename] > p') # 找到title为titlename的div标签,进一步找到div标签的所有 p 子标签
获取标签的属性,可将标签看做字典,直接在标签后加 [属性名]。获取内容的方式有三种,其中 string 获取的是标签直系文本内容,也就是说标签子标签中的内容不会获取到,而 text 和 get_text() 获取的是标签所有文本,包括子标签内的文本内容。
# 属性获取
p.attrs # 获取p标签所有的属性和属性值,返回字典
p.attrs['href'] # 获取p标签的href属性
p['href'] # 多简写为这种形式
# 内容获取
p.string # 获取p标签直系文本内容
p.text # 获取p标签所有文本内容
p.get_text() # 获取p标签所有文本内容
3.1 find 系列
def parse_bs_find(page_text):
soup = BeautifulSoup(page_text, 'lxml') # 做汤
lists = soup.find_all('p', attrs={'class': "content__list--item--title twoline"}) # attrs 进行标签定位
title = [i.a.text.strip() for i in lists] # 内容获取
href = ['https://bj.lianjia.com/' + i.a['href'].strip() for i in lists] # 属性获取
prices = soup.find_all('span', class_="content__list--item-price") # 直接加属性值参数进行标签定位
price = [i.em.text.strip() for i in prices] # 内容获取
result = dict(title=title, href=href, price=price)
return result
3.2 select 系列
def parse_bs_select(page_text):
soup = BeautifulSoup(page_text, 'lxml') # 做汤
lists = soup.select('div .content__list--item--main > p:first-of-type > a') # 类选择器.
title = [i.text.strip() for i in lists]
href = ['https://bj.lianjia.com/' + i['href'].strip() for i in lists]
prices = soup.select('span[class=content__list--item-price]>em') # 借助 [] 添加属性筛选条件
price = [i.text.strip() for i in prices]
result = dict(title=title, href=href, price=price)
return result
4、xpath
xpath 是我最喜欢用的方法,主要是因为获取属性和内容的方式较为简便,简单的使用我归纳到了下面的代码块,详细内容可点击在线教程进行学习。
使用时需要先实例化 etree 对象,得到一棵 tree ,之后进行提取就好了。(感觉过于好用以至于没有什么需要说的,直接看代码吧,比对网页源代码食用效果更佳)
# / : 表示从根节点开始定位
# // : 可以从任意位置开始定位
# ./ : 再对标签进行二次提取时需要用到,本文不涉及
属性定位://tag[@attrName='attrValue'] 注意属性值需要加@,引号,不同于bs4的select
索引定位://div[@class='song']/p[3] 第三个p标签
//div[@class='song']/p[last()] 最后一个p标签
//div[@class='song']/p[position()<3] 前两个p标签
取文本:
/text() 获取直系文本内容
//text() 获取所有文本内容
取属性:
/@attrName
def parse_xpath(page_text):
tree = etree.HTML(page_text) # 实例化tree
titles = tree.xpath('//p[@class="content__list--item--title twoline"]/a/text()') # 先找到class为content__list--item--title twoline的p标签,再找到子标签a,获取a标签中所有内容
title = [i.strip() for i in titles]
hrefs = tree.xpath('//p[@class="content__list--item--title twoline"]/a/@href') # 先找到class为content__list--item--title twoline的p标签,再找到子标签a,获取a标签的href属性
href = ['https://bj.lianjia.com/' + i.strip() for i in hrefs]
prices = tree.xpath('//span[@class="content__list--item-price"]/em/text()')
price = [i.strip() for i in prices]
result = dict(title=title, href=href, price=price)
return result
5、结果与总结
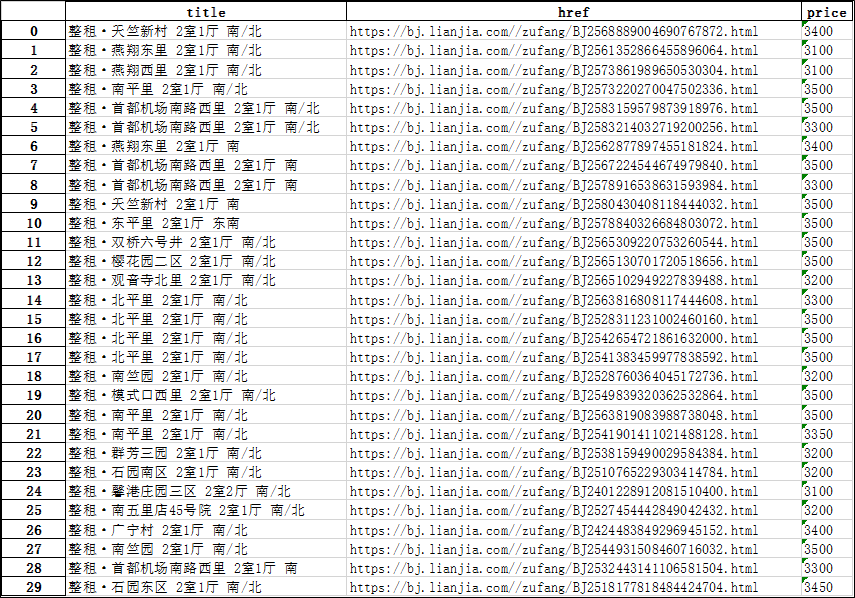
最终写一个主函数,个人习惯于使用pandas进行数据存读,希望有大佬可以提供更方便快捷的存读方式。结果展示如下图。
个人建议,如果学习爬虫只是为了好玩或是满足一些简单需求,学好xpath就可以的,方便快捷,居家必备。
if __name__ == "__main__":
url = 'https://bj.lianjia.com/zufang/'
page_text = get_page(url)
result = parse_bs_select(page_text)
df = pd.DataFrame(result)
df.to_excel('1.xlsx')
print(df)
最后
以上就是舒心网络最近收集整理的关于爬虫系列(一):解析网页的常见方式汇总——re、bs4、xpath——以链家租房信息爬取为例的全部内容,更多相关爬虫系列(一):解析网页内容请搜索靠谱客的其他文章。








发表评论 取消回复