前言:首先!先谢谢各位大佬的捧场

在讲代码前,先容我先废话一句,为什么我用bs4来进行数据解析?
因为可以bs4可以不用正则来解析,当然我们也可以用xpath(后面我会讲到的)。

废话不多说,直接上内容!
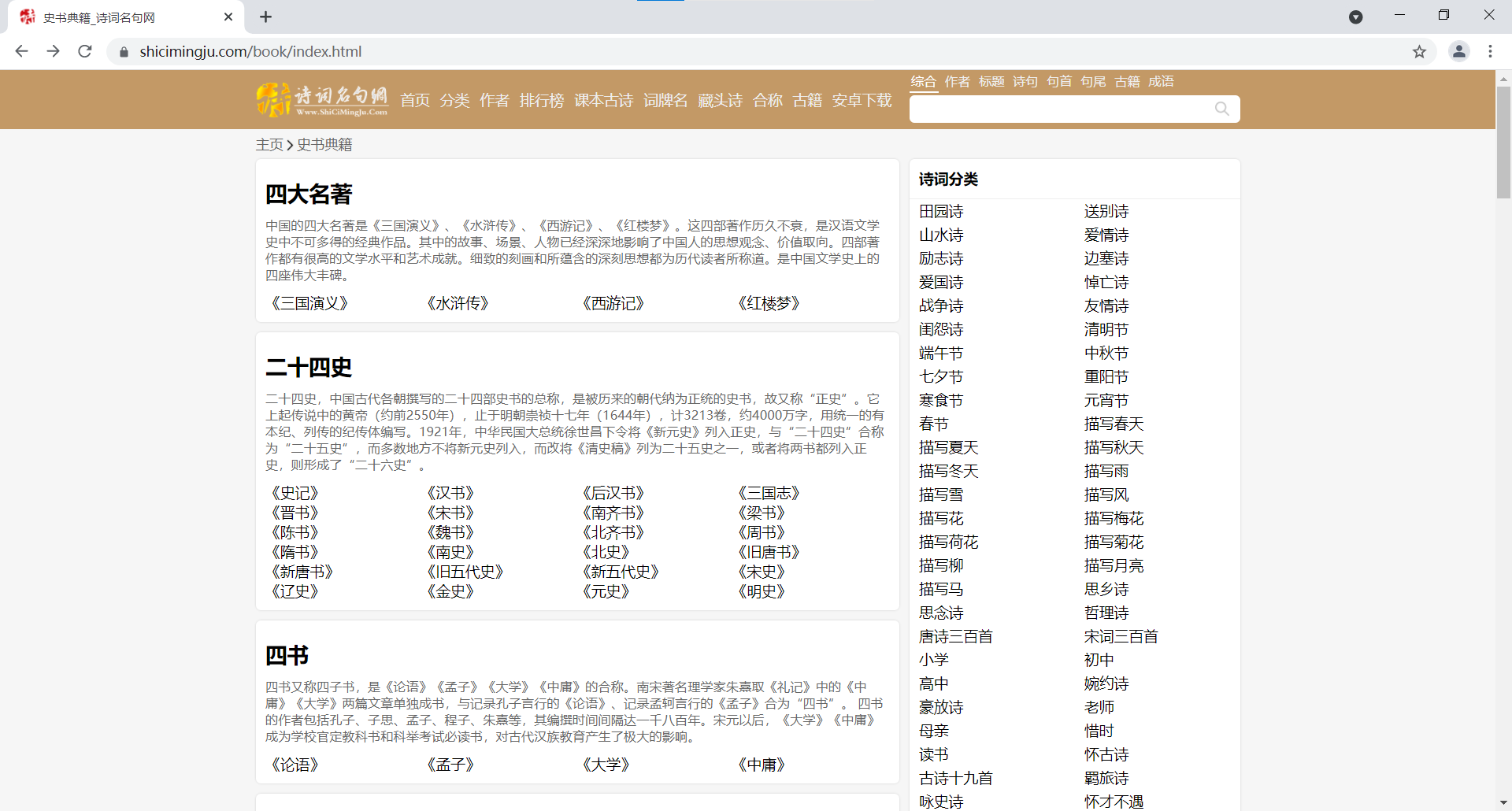
今天我们的目的就是爬它,网址如下:史书典籍_诗词名句网 https://www.shicimingju.com/book/index.html
https://www.shicimingju.com/book/index.html

1.引入库
import requests
from bs4 import BeautifulSoup2.分析内容,理清思路
我们先来看这个页面
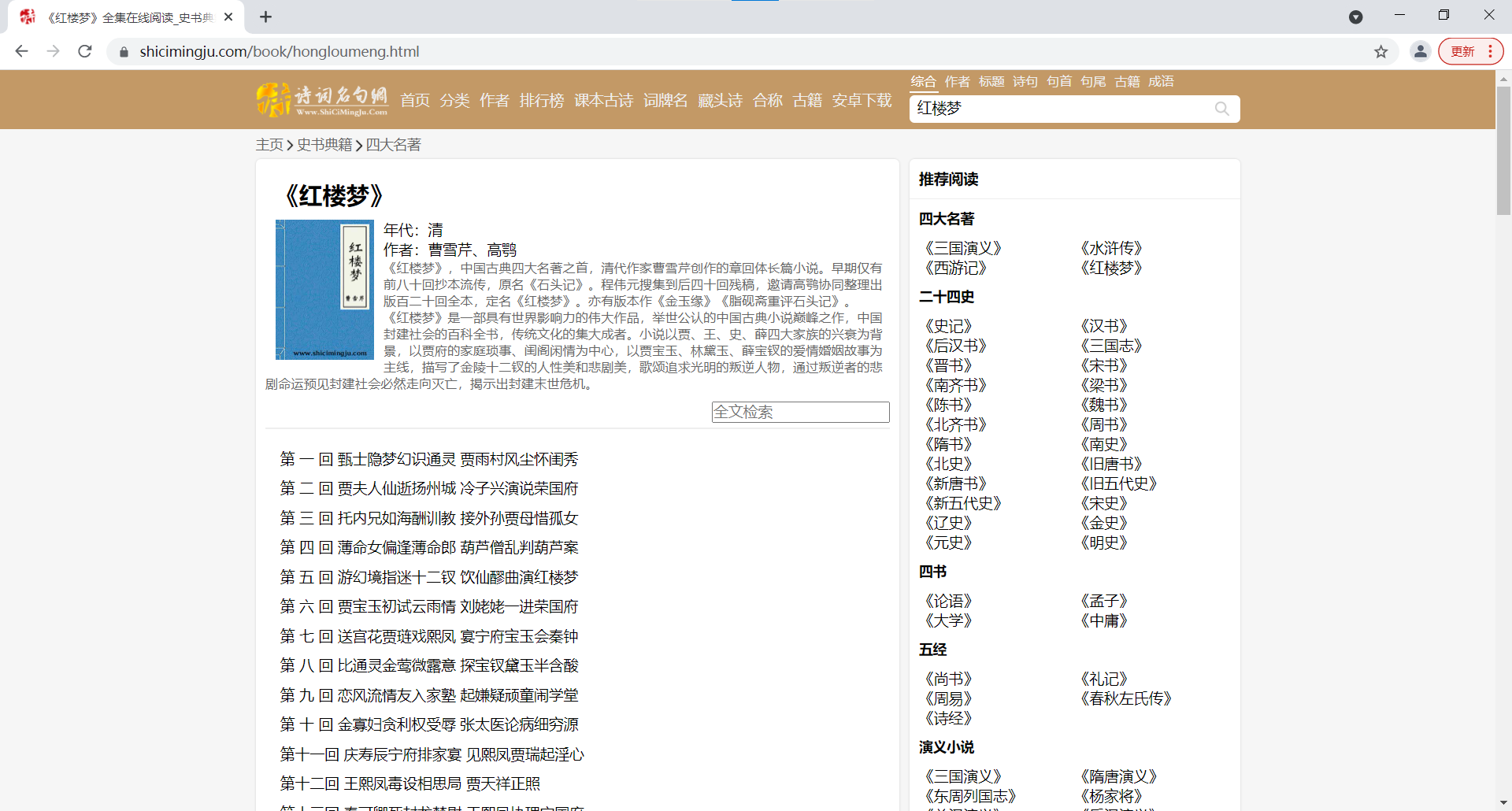
挺好的,请求方法是get方法,但编码方式要注意一下。
 如果按照我们爬虫的思路,我们只需要五步走就可以成功爬取这张页面:1.指定url,2.发起请求 ,3.获取响应数据 ,4.数据解析 ,5.持久化存储。但是我们想要爬的是整本红楼梦的内容,好吧!让我们先回到网页看看,能不能找到一点规律!
如果按照我们爬虫的思路,我们只需要五步走就可以成功爬取这张页面:1.指定url,2.发起请求 ,3.获取响应数据 ,4.数据解析 ,5.持久化存储。但是我们想要爬的是整本红楼梦的内容,好吧!让我们先回到网页看看,能不能找到一点规律!
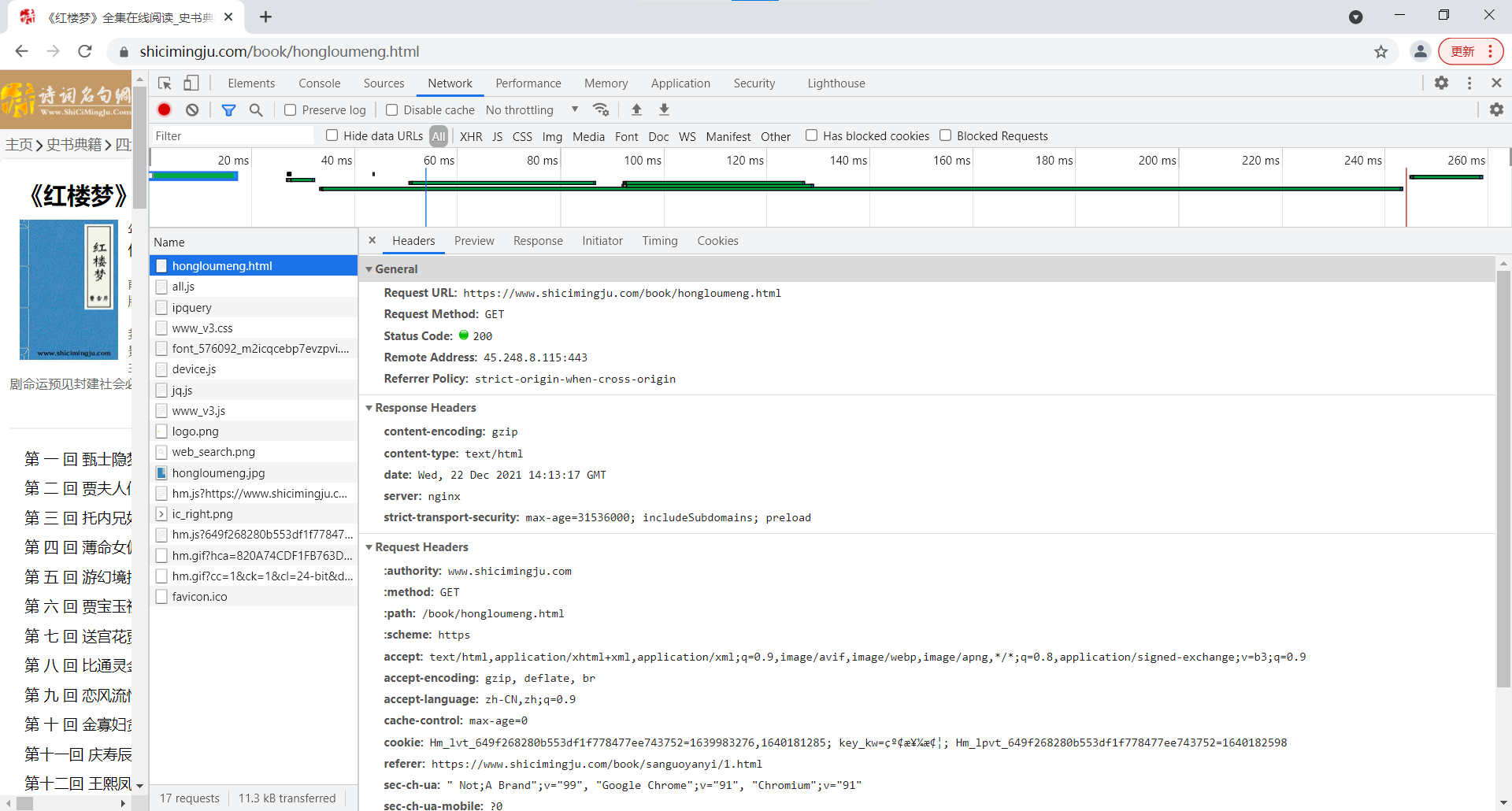
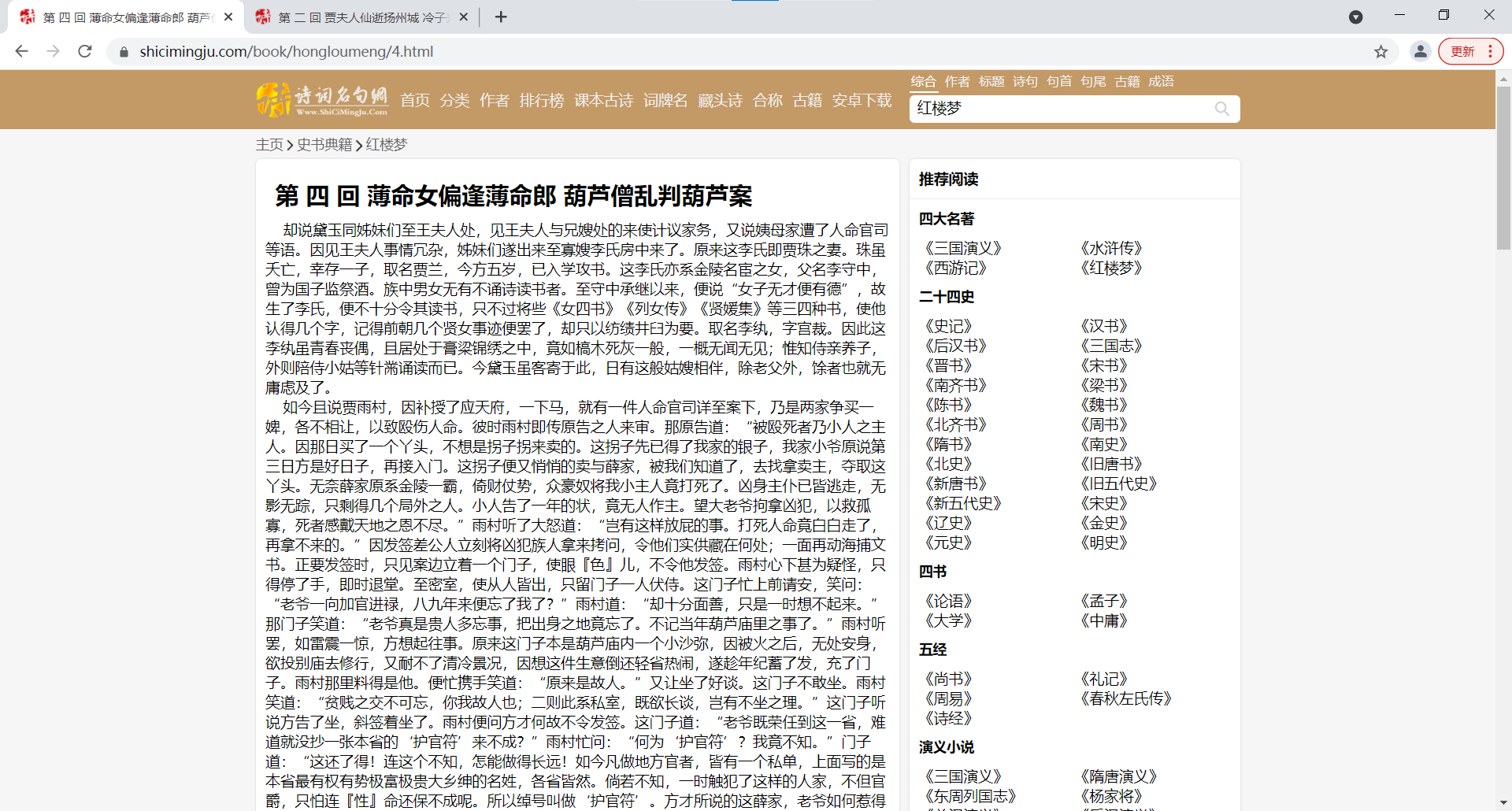 我们将俩张页面的网址对比一下:
我们将俩张页面的网址对比一下:
https://www.shicimingju.com/book/hongloumeng/2.html
https://www.shicimingju.com/book/hongloumeng/4.html
我们就发现hongloumeng后面跟着的数字实际上就是这本书的章回数,我们试验一下果真如此!那我们能不能用一个循环来把整本书内容保存下来呢!这样我们的思路理清了。
完整代码
之前写的到这里就差不多结束了 今天挑战一波自己 讲解代码
估计得干到一点了 又是一个不眠之夜 点点赞哇各位

代码很简单,也很容易理解。
requests库和Beautifulsoup库是必备的!requests库是用来模拟浏览器请求数据,Beautifulsoup是用来解析数据。
import requests
from bs4 import BeautifulSoup按照我前面讲的五个步骤。
1.指定url
url="https://www.shicimingju.com/book/sanguoyanyi.html"如果没有UA伪装是肯定不行的!(这个伪装有点简单,如果在后期我们进行网页爬取时,发现拒绝访问,我们可以补添参数!)
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}2.发起请求和3.获取响应数据
我把发起请求和获取响应数据合在了一起,提高代码的执行效率!
我们在前面就发现了这个网页采用的GST请求方法!因此不需要传入data。
page_text==requests.get(url=url,headers=headers).text4.数据解析
soup=BeautifulSoup(page_text,'lxml')
li_list=soup.select('.book-mulu > ul > li')这是将互联网上获取的页面源码加载到该对象中
而'.book-mulu>ul>li'这个是层级选择器。
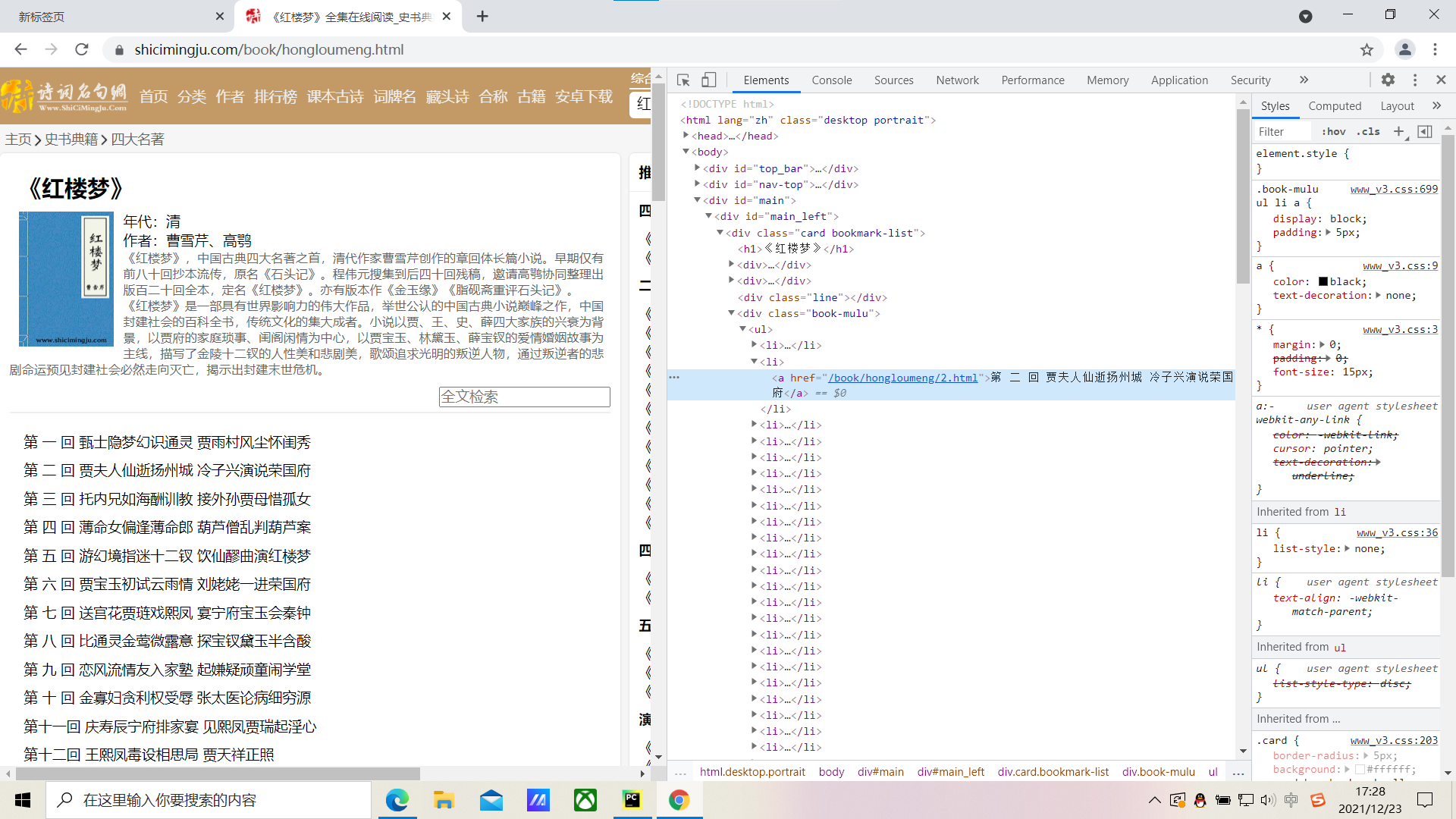 这样看是不是就有些明白了。
这样看是不是就有些明白了。
5.持久化存储
这是用循环将目录下的所以内容爬取下来
![]()
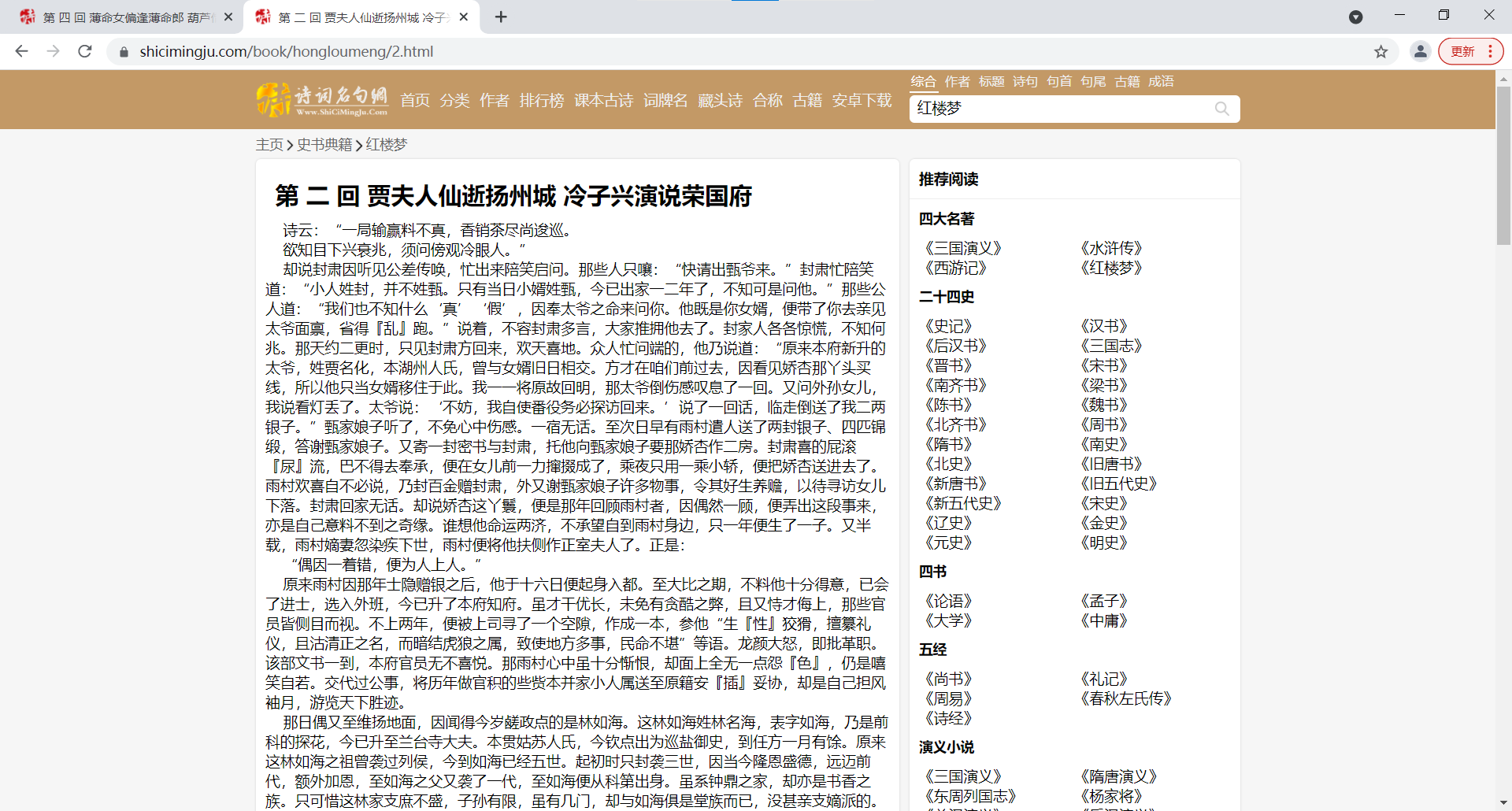
我们如何顺着这个目录爬下去呢?我才用是
detail_url="https://www.shicimingju.com"+li.a['href']这种拼接方式,因为我们发现在a标记的下面的链接并不完整。
接下来的代码其实跟上面是一样的,都是获取数据,解析数据,保存数据。只不过是目录下的正文爬取罢了!
for li in li_list:
title=li.a.string
detail_url="https://www.shicimingju.com"+li.a['href']
detail_page_text=requests.get(url=detail_url,headers=headers).text
detail_soup=BeautifulSoup(detail_page_text,'lxml')
div_tag=detail_soup.find('div',class_= "chapter_content")
content=div_tag.text
fp.write(title+':'+content+'n')
print(title,'爬取成功')拼接代码
我们将代码拼接下来,会发现出错,这是因为编码的方式不同。我有俩种解决方案,大家可以看一下!
第一种方法
page_text = requests.get(url,headers) page_text.encoding = page_text.apparent_encoding page_text = page_text.text
这是因为编码的方式不同,所以我才这样修改。
方法一就将
detail_page_text = detail_page_text.encode('iso-8859-1')
这个加在
detail_page_text=requests.get(url=detail_url,headers=headers).text
后面
#!/usr/bin/env python
# -- coding: utf-8 --
# @Time : 2021/12/20 14:50
# @File : bs4解析实战.py
import requests
from bs4 import BeautifulSoup
#需求:爬取红楼梦所以章节和内容https://www.shicimingju.com/book/sanguoyanyi.html
#对首页的页面数据进行爬取
url="https://www.shicimingju.com/book/hongloumeng.html"
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
#page_text==requests.get(url=url,headers=headers).text
page_text = requests.get(url,headers)#编码方式不同
page_text.encoding = page_text.apparent_encoding
page_text = page_text.text
#需要在首页中解析出章节的标题和详情页的url
#实例化Beautifulsoup对象,需要将页面源码数据加载到该对象中
soup=BeautifulSoup(page_text,'lxml')
#解析章节标题和详情页的url
li_list=soup.select('.book-mulu > ul > li')
fp=open('./sg.txt','w',encoding='utf-8')
for li in li_list:
title=li.a.string
detail_url="https://www.shicimingju.com"+li.a['href']
#print(detail_url)
#对详情页发起请求,解析出章节内容
detail_page_text=requests.get(url=detail_url,headers=headers).text
detail_page_text = detail_page_text.encode('iso-8859-1')
# detail_page_text=requests.get(url,headers)
# detail_page_text.encoding=detail_page_text.apparent_encoding
# detail_page_text=detail_page_text.text
#解析出详情页中的相关的章节内容
detail_soup=BeautifulSoup(detail_page_text,'lxml')
div_tag=detail_soup.find('div',class_= "chapter_content")
#解析到章节的内容
content=div_tag.text
#print(div_tag)
fp.write(title+':'+content+'n')
print(title,'爬取成功')
第二种方法
方法二,不需要detail_page_text = detail_page_text.encode('iso-8859-1')
直接detail_page_text=requests.get(url=detail_url,headers=headers).text中的text修改成content就可以了。至于text和content的区别在于,content中间存的是字节码,而text中存的是Beautifulsoup根据猜测的编码方式将content内容编码成字符串。 直接输出content,会发现前面存在b'这样的标志,这是字节字符串的标志,而text是没有前面的b,对于纯ascii码,这两个可以说一模一样,对于其他的文字,需要正确编码才能正常显示。(内容来自百度)
#!/usr/bin/env python
# -- coding: utf-8 --
# @Time : 2021/12/20 14:50
# @File : bs4解析实战.py
import requests
from bs4 import BeautifulSoup
#需求:爬取红楼梦所以章节和内容https://www.shicimingju.com/book/sanguoyanyi.html
#对首页的页面数据进行爬取
url="https://www.shicimingju.com/book/hongloumeng.html"
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
#page_text==requests.get(url=url,headers=headers).text
page_text = requests.get(url,headers)#编码方式不同
page_text.encoding = page_text.apparent_encoding
print(page_text.apparent_encoding)
page_text = page_text.text
#需要在首页中解析出章节的标题和详情页的url
#实例化Beautifulsoup对象,需要将页面源码数据加载到该对象中
soup=BeautifulSoup(page_text,'lxml')
#解析章节标题和详情页的url
li_list=soup.select('.book-mulu > ul > li')
fp=open('./sg.txt','w',encoding='utf-8')
for li in li_list:
title=li.a.string
detail_url="https://www.shicimingju.com"+li.a['href']
#print(detail_url)
#对详情页发起请求,解析出章节内容
detail_page_text=requests.get(url=detail_url,headers=headers).content
#detail_page_text = detail_page_text.encode('iso-8859-1')
# detail_page_text=requests.get(url,headers)
# detail_page_text.encoding=detail_page_text.apparent_encoding
# detail_page_text=detail_page_text.text
#解析出详情页中的相关的章节内容
detail_soup=BeautifulSoup(detail_page_text,'lxml')
div_tag=detail_soup.find('div',class_= "chapter_content")
#解析到章节的内容
content=div_tag.text
#print(div_tag)
fp.write(title+':'+content+'n')
print(title,'爬取成功')
结语
这就是最终结果!如果大家想要爬取诗词名句网任一文章,只需要修改它的url就可以了。
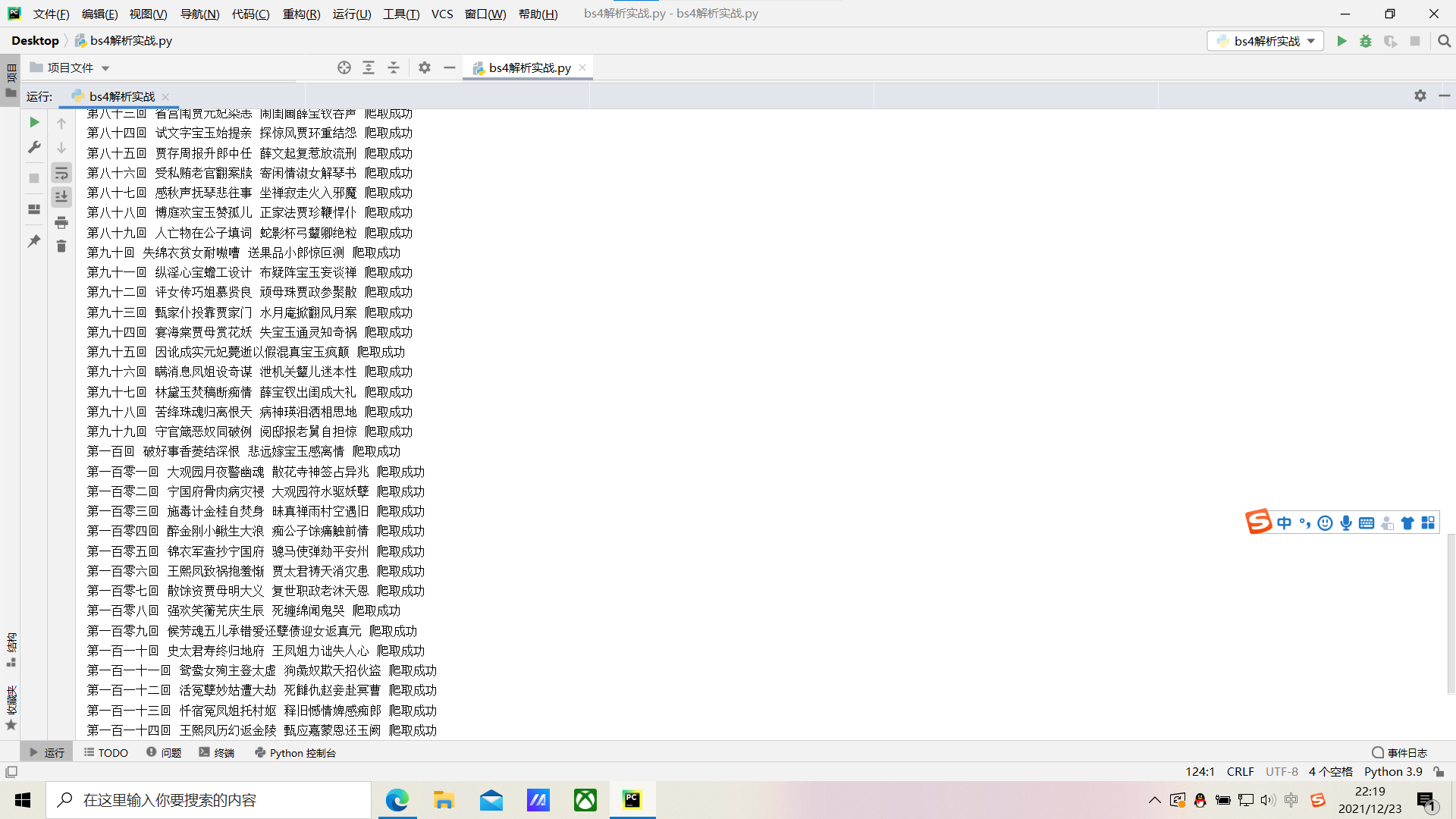
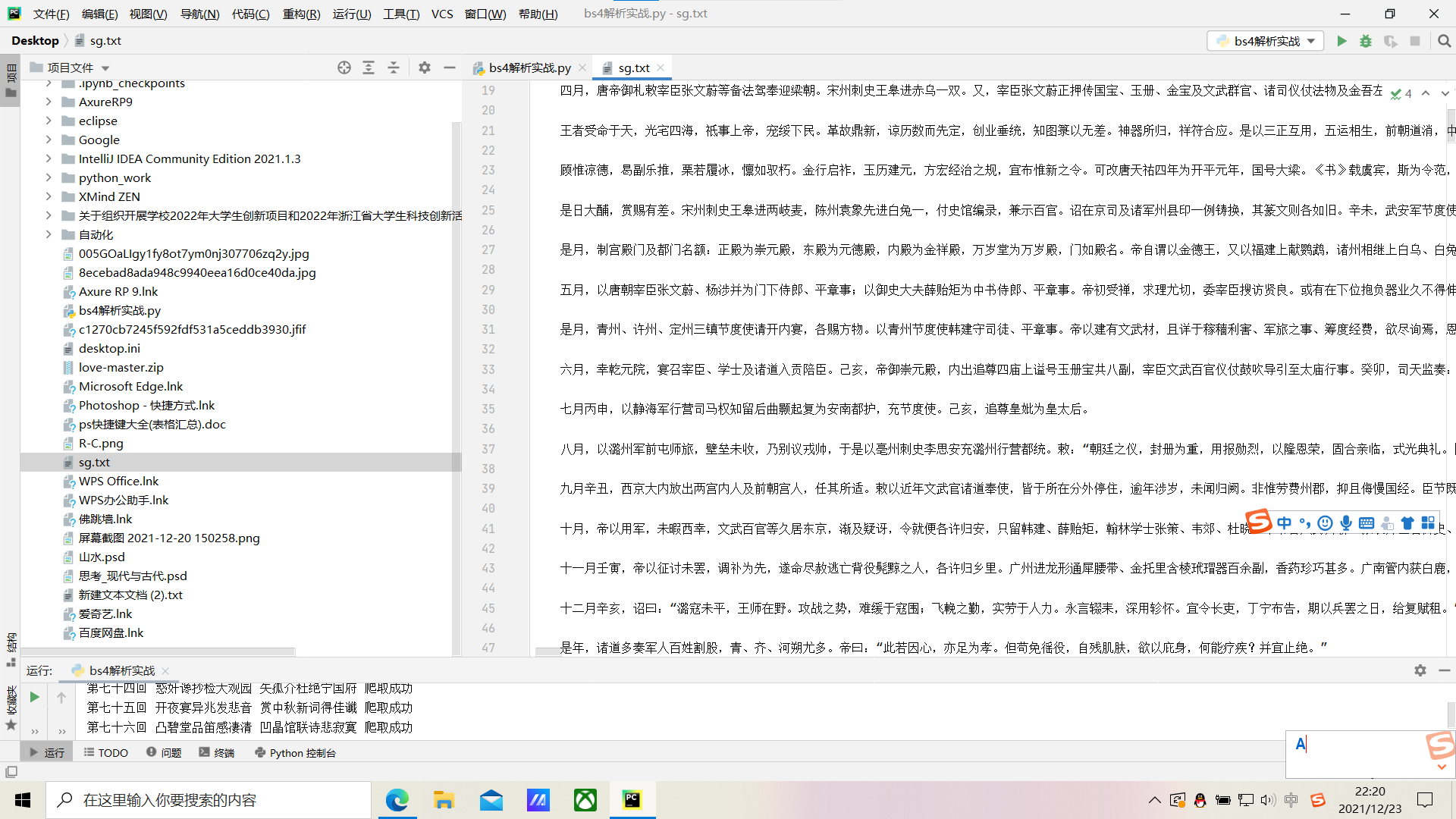
最后
以上就是过时戒指最近收集整理的关于学习笔记——bs4解析完整代码的全部内容,更多相关学习笔记——bs4解析完整代码内容请搜索靠谱客的其他文章。








发表评论 取消回复