今天再去爬取另外一个网站 http://pic.netbian.com/
先来看看这个网站的几张图片,我们试图单独爬取看看。


我们单独爬取一下试一试
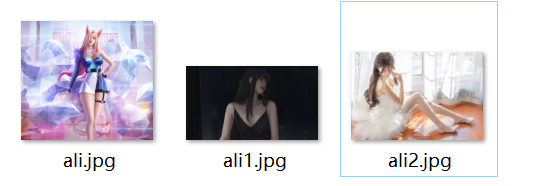
本地查看,证明图片是可以爬取成功的。
代码如下:
import requests #导入模块
def run4():
headers = {'referer': 'http://pic.netbian.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:47.0) Gecko/20100101 Firefox/47.0'}
with open("D:/estimages/ali.jpg", "wb") as f :
f.write(requests.get("http://pic.netbian.com/uploads/allimg/201207/233228-16073551488aeb.jpg", headers=headers).content)
f.close
with open("D:/estimages/ali1.jpg", "wb") as f :
f.write(requests.get("http://pic.netbian.com/uploads/allimg/200618/005100-1592412660d6f4.jpg", headers=headers).content)
f.close
with open("D:/estimages/ali2.jpg", "wb") as f :
f.write(requests.get("http://pic.netbian.com/uploads/allimg/190518/174718-1558172838db13.jpg", headers=headers).content)
f.close
if __name__ == "__main__": #主程序入口
run4() #调用上面的run方法
开始开始。。。
接下来我们得分析下这个网站的结构,http://pic.netbian.com/ 是根url,存在多个标签,也是个分层的展示结构。
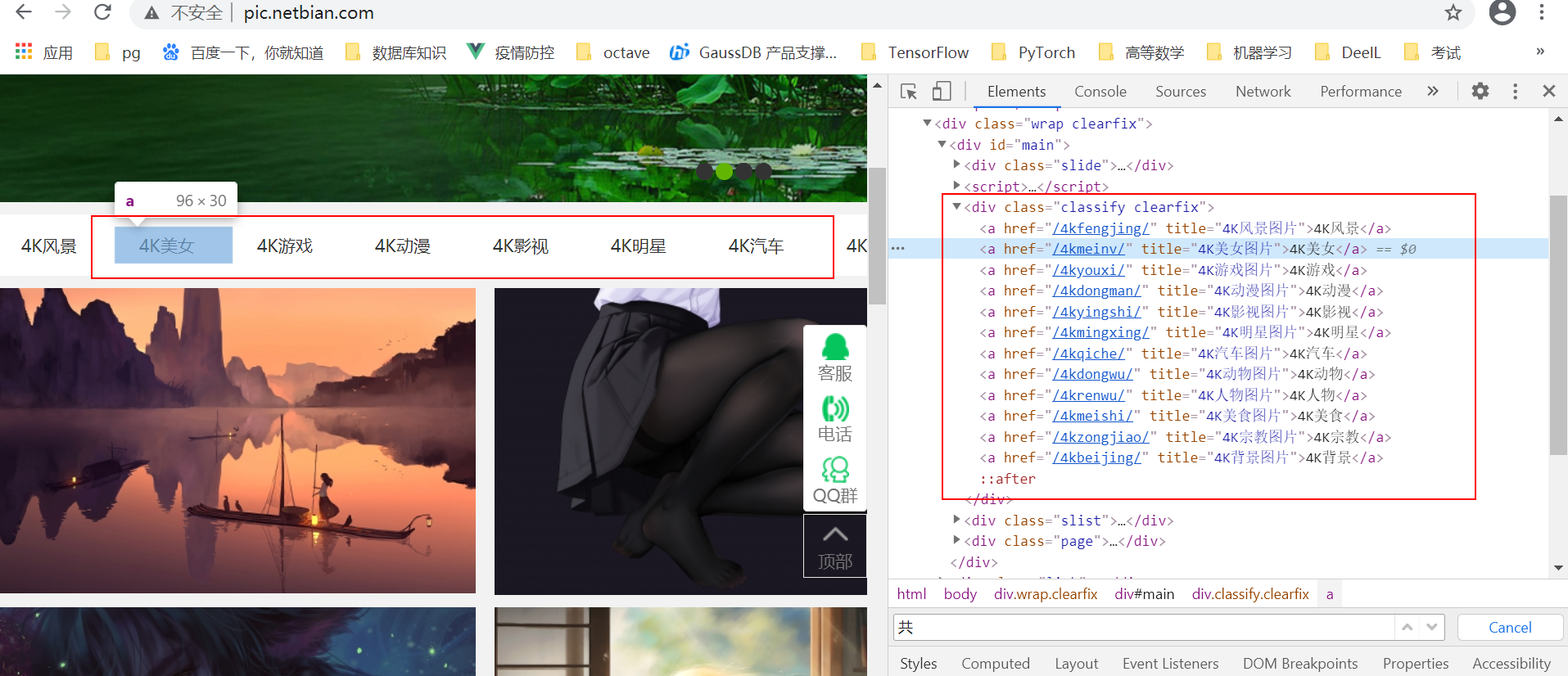
而且是固定这些标签,数量是固定的,因此我们还是先爬取标签按种类。
随意选首页即可把所有的标签都爬取下来。
而且标签的 href 值是下一层的地址,text文本是标签的文本内容。
点击一个标签进去,发现是一大堆属于该标签的图片,还有分页。
比如我点击的是【4K美女】,地址栏显示的是http://pic.netbian.com/4kmeinv/
此时每张图片的HTML位置如下:在class=”slist”的div块中。

因此我们需要把这个div下所有img都需要爬取出来。
另外分页栏如下:
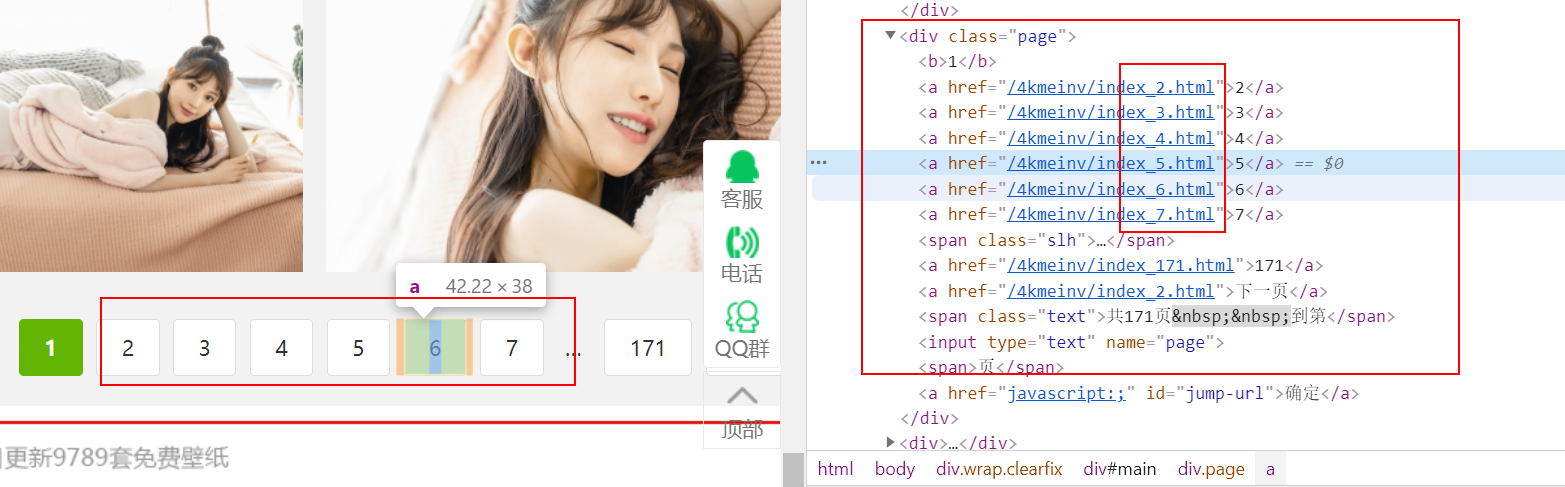
经过观察可见每个分页栏的命名也是很有规律的啊,因此我们可以推测出 http://pic.netbian.com/4kmeinv/ 是等于http://pic.netbian.com/4kmeinv/index.html ,在浏览器中这样输入,果然是对的,其他的页面都是按照 index_+数字编号的方式。
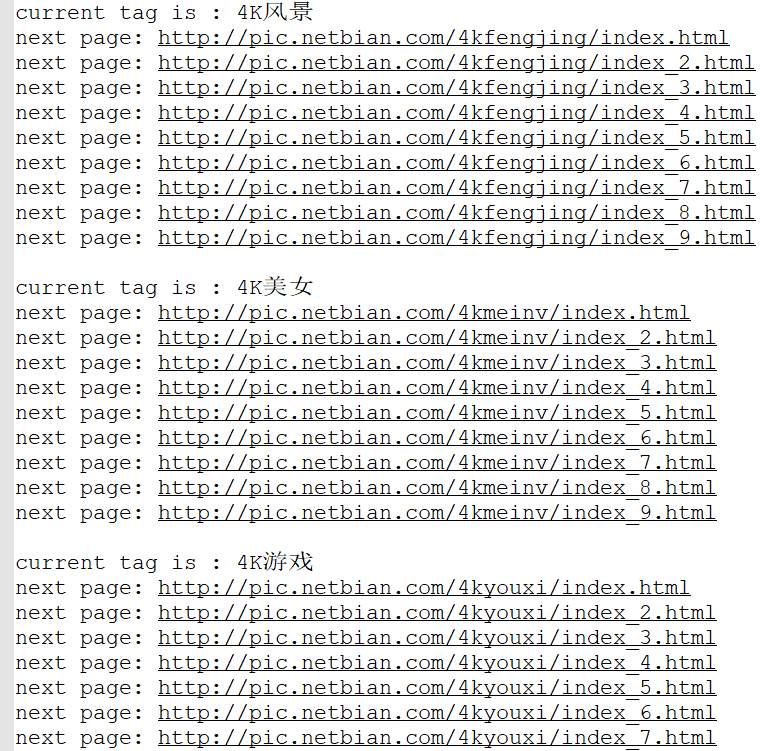
后面我会把完整代码贴上,需要把save_all_images函数的调用注释掉,且让线程顺序执行的展示结果(也就是在t.start() 后面增加了t.Join(),这样就能顺序执行了),我做了额外处理,就是页面实在太多了,越是做了截断(每个标签最多爬取10个页面)。
这里我还是选择找【下一页】的href值来选择下一个页面。
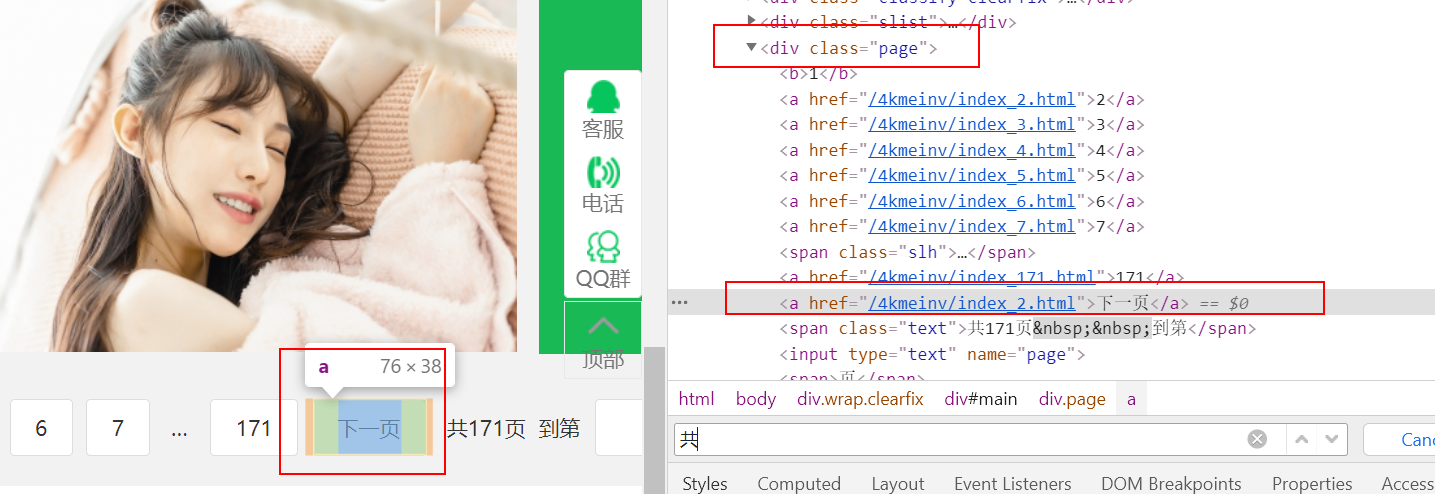
它处在class=”page”的div中,找到这个【下一页】,得到其href值,就得到了下一个页面的地址。
这样一来,我们的策略就是:
1:先得到所有的标签
2:根据标签建立一个线程单独处理该标签下所有图片
3:每一个标签下,按照分页,一旦访问一个页面,就爬取该页面所有图片。
具体代码如下:
#-*- coding:utf-8 -*-
import os
import requests
from bs4 import BeautifulSoup
import threading
import time
rootrurl = 'http://pic.netbian.com/'
save_dir = 'D:/estimages/'
no_more_pages = 'END'
max_pages = 8
image_cache = set()
index = len(image_cache)
# step 1: 得到所有标签tags
html = BeautifulSoup(requests.get(rootrurl).text.encode('iso-8859-1').decode('gbk'), features="html.parser")
tag_list = {}
for link in html.find('div', {'class': 'classify clearfix'}).find_all('a'):
tag_list[link.string] = link.get('href')
print("the number of unique tag is : %d" % len(tag_list))
print(tag_list)
# step 2: 根据每个标签分别爬取,每个标签点进去都是一个分页
# 因此需要做好分页,鉴于图片太多了,我们需要做个多线程来操作
class myThread (threading.Thread): #继承父类threading.Thread
def __init__(self, threadID, key ,value):
threading.Thread.__init__(self)
self.threadID = threadID
self.key = key
self.value = value
def run(self): #把要执行的代码写到run函数里面 线程在创建后会直接运行run函数
time.sleep(1)
print("Thread %d is running..." % self.threadID)
self.serachSubPages(self.key, self.value)
print("Thread %d is over..." % self.threadID)
def serachSubPages(self, key ,value):
# 建立这个标签的子目录,图片太多了,按照标签建立子目录,方便存储和整理
tag_name = key
if not os.path.exists(save_dir + tag_name):
os.mkdir(save_dir + tag_name)
print("current tag is : " + tag_name)
url = rootrurl + value + 'index.html'
pages = 0;
while 1:
print("next page: " + url)
html = BeautifulSoup(requests.get(url).text.encode('iso-8859-1').decode('gbk'), features="html.parser")
self.save_all_images(html, save_dir + tag_name)
if pages >= max_pages: #每个标签最多搜索的页面数
break;
pages = pages + 1
url = self.findNextPage(html)
if url == no_more_pages:
break
url = rootrurl + url
def save_all_images(self, html, saveDir):
global index
imgs = html.find('div', {'class': 'slist'}).find_all('img')
print('total imgs is %d:' % len(imgs))
for img in imgs:
# 有一些图片的href是src, 有一些图片的href是original,因此都是要考虑的。
href = img.get('src')
print(href)
# 判断是否重复下载
if href not in image_cache:
with open(
'{}/{}'.format(saveDir, href.split("/")[-1]), 'wb') as jpg: # 请求图片并写进去到本地文件
jpg.write(requests.get(rootrurl + href).content)
image_cache.add(href)
print("正在抓取第%s条数据" % index)
index += 1
def findNextPage(self, html):
nextBtn = html.find('div', {'class': 'page'}).find_all('a') # 找到next按钮,获得下一个连接网页的位置
for link in nextBtn:
if link.string == '下一页':
return link.get('href')[1:]
return no_more_pages
if __name__ == '__main__':
i = 0
thread_list = []
for key ,value in tag_list.items():
thread1 = myThread(i, key ,value[1:]) # 创建多个线程去分别爬取各个标签页的数据
thread_list.append(thread1)
i=i+1
for t in thread_list:
# t.setDaemon(True) # 设置为守护线程,不会因主线程结束而中断
t.start()
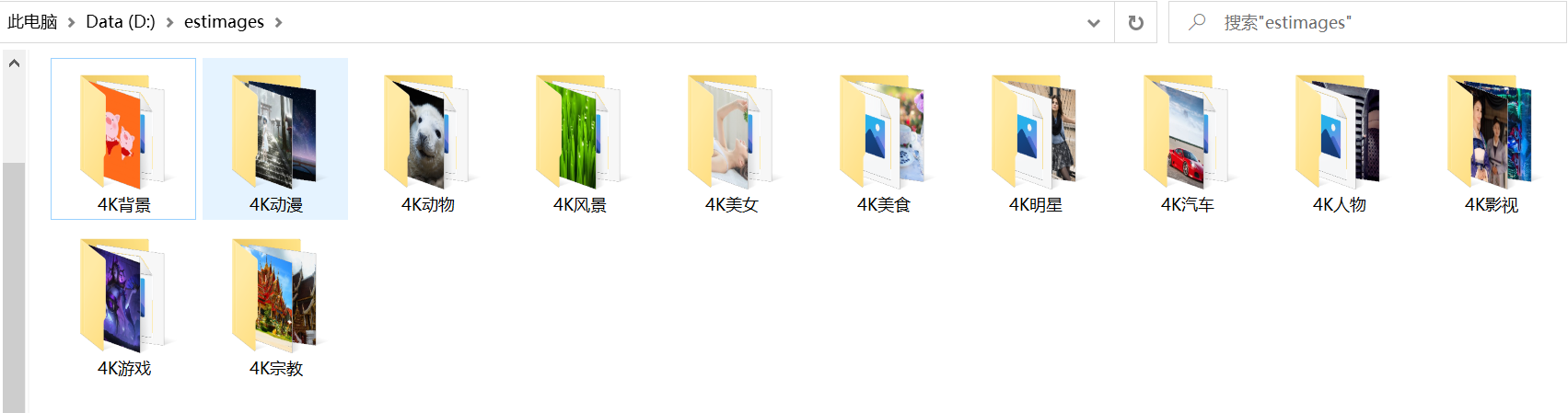
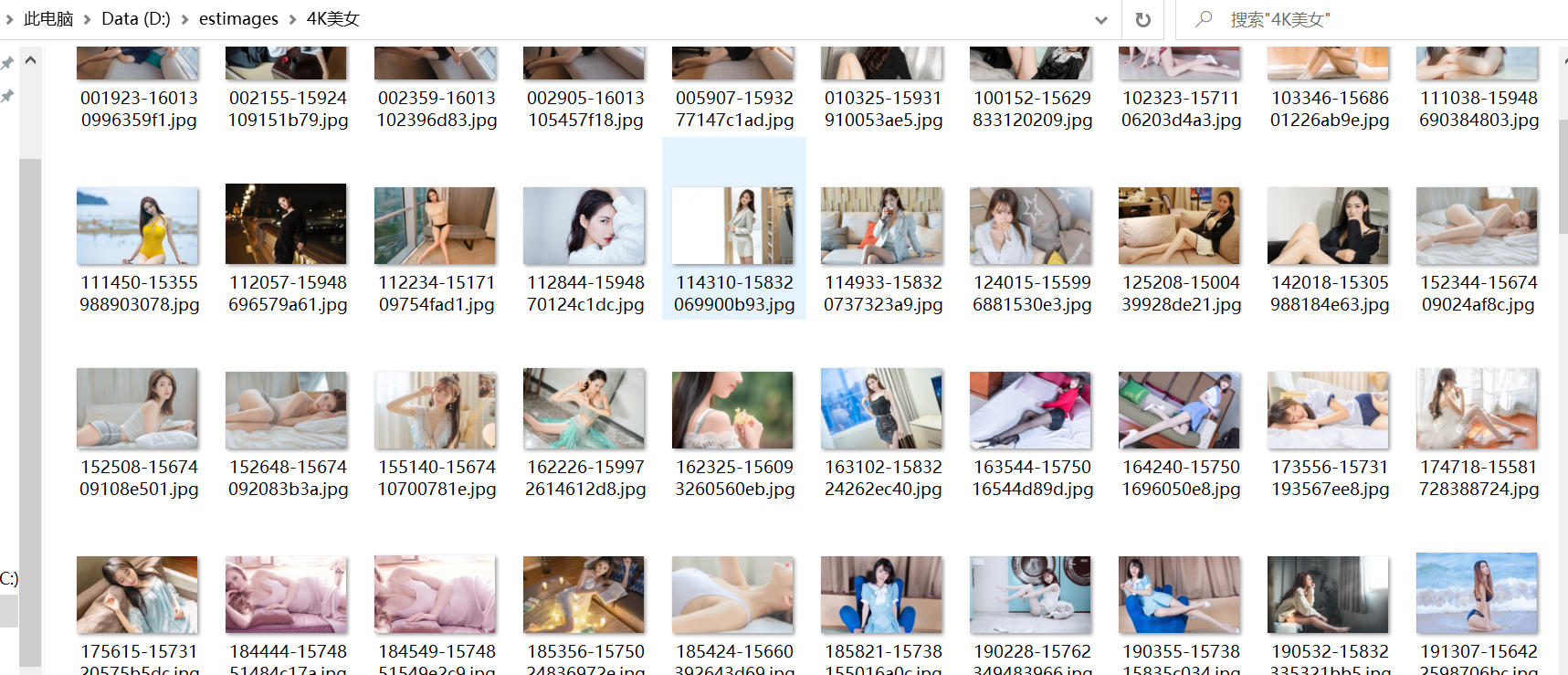
效果如下:
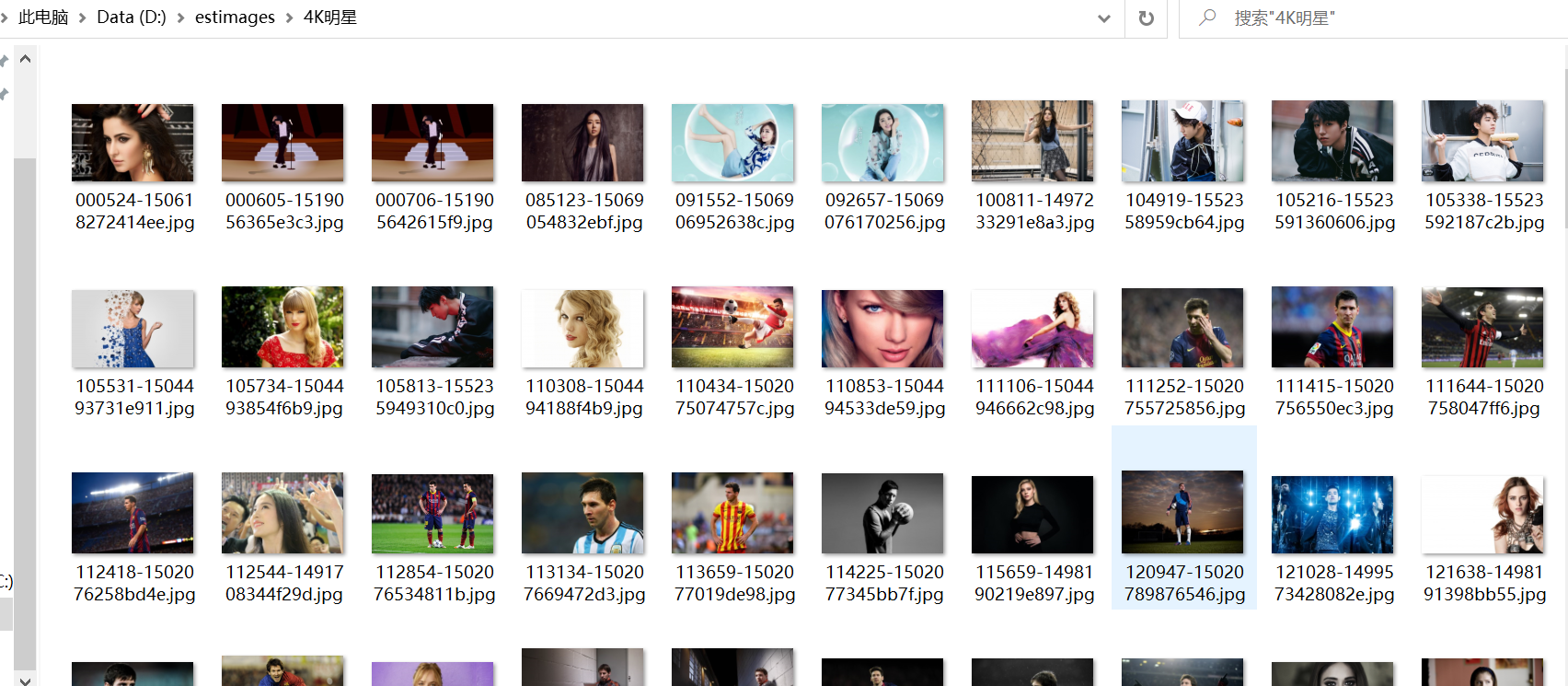

最后
以上就是健忘糖豆最近收集整理的关于Python《多线程并发爬虫》的全部内容,更多相关Python《多线程并发爬虫》内容请搜索靠谱客的其他文章。








发表评论 取消回复