python并发编程分为三个方向,分别是 多进程,多线程,多协程 。根据具体情况选择具体的方式,能提高程序的速度。
三种类别的对比
-
多进程
- 优点:可以利用多个CPU并行运算(多核计算机)
- 缺点:占用的资源最多,可启动的数目比线程少
- 适用于:CPU密集型计算(使用CPU较多,IO较少)
-
多线程
- 优点:相比进程,更轻量级,占用资源少
- 缺点:
- 相比进程:多线程只能并发执行,不能利用多个CPU (GIL)
- 相比协程:启动数目有限制,占用内存资源,有线程切换的开销
- 适用于:IO密集型计算,同事运行的任务数目要求不多
-
多协程:
- 优点:内存开销最小,启动的协程数目最多
- 缺点:支持的库有限制(aiohttp ),代码实现复杂
- 适用于:IO密集型计算,需要超多任务运行,但有现成的库支持的场景
-
三种方式的理解:
有一个老板想要开个工厂进行生产口罩
他需要花一些财力物力制作一条生产线,这个生产线上有很多的器件以及材料这些所有的 为了能够生产口罩而准备的资源称之为:进程
只有生产线是不能够进行生产的,所以老板的找个工人来进行生产,这个工人能够利用这些材料最终一步步的将口罩做出来,这个来做事情的工人称之为:线程
这个老板为了提高生产率,想到3种办法:
在这条生产线上多招些工人,一起来做口罩,这样效率是成倍増长,即单进程 多线程方式
老板发现这条生产线上的工人不是越多越好,因为一条生产线的资源以及材料毕竟有限,所以老板又花了些财力物力购置了另外一条生产线,然后再招些工人这样效率又再一步提高了,即多进程 多线程方式
老板发现,现在已经有了很多条生产线,并且每条生产线上已经有很多工人了(即程序是多进程的,每个进程中又有多个线程),为了再次提高效率,老板想了个损招,规定:如果某个员工在上班时临时没事或者再等待某些条件(比如等待另一个工人生产完谋道工序 之后他才能再次工作) ,那么这个员工就利用这个时间去做其它的事情,那么也就是说:如果一个线程等待某些条件,可以充分利用这个时间去做其它事情,其实这就是:协程方式
多线程实例
使用模块 threading
import threading
import requests
import time
urls = [
f"https://www.cnblogs.com/#p{page}" for page in range(1, 50)
]
def spider(url):
response = requests.get(url).text
print(url, len(response))
def sign_threading():
print("sign_threading start")
for url in urls:
spider(url)
print("sign_threading end")
def multi_threading():
print("multi_threading start")
threadings = []
for url in urls:
threadings.append(threading.Thread(target=spider, args=(url,)))
for thread in threadings:
thread.start()
for thread in threadings:
thread.join()
print("multi_threading")
if __name__ == '__main__':
start_time = time.time()
sign_threading()
end_time = time.time()
print("sign_threading cost:", end_time-start_time)
start_time = time.time()
multi_threading()
end_time = time.time()
print("multi_threading cose:", end_time-start_time)
生产者消费者模式
队列的使用,队列保证了多个线程之间的数据通信
- 导入类 ,
import queue - 创建队列,
q = queue.Queue() - 添加元素,
q.put(item) - 获取元素,
item = q.get() - 查看状态
- 查看元素的个数,
q.qsize() - 判断是否为空,
q.empty() - 判断是否为满,
q.full()
- 查看元素的个数,
# 生产者消费者模式
import requests
from lxml import etree
import time
import queue
import threading
import random
data_queue = queue.Queue()
def spider(url):
response = requests.get(url).text
return (url, response)
# 生产者: 目的在于请求到html网页, 并存入队列
def producer(url_queue, data_queue):
while True:
url = url_queue.get()
data_queue.put(spider(url))
print(threading.current_thread().name, f"data_queue.size", data_queue.qsize())
time.sleep(random.randint(1, 2))
# 消费者: 目的在于解析html网页数据,并写入文件
def consumer(data_queue, fq):
while True:
data = data_queue.get()
html = etree.HTML(data[1])
titles = html.xpath("//a[@class='post-item-title']/text()")
url = data[0]
for title in titles:
fq.write(url + ", " + title + "n")
print(threading.current_thread().name, f"data_queue.size", data_queue.qsize())
time.sleep(random.randint(1, 2))
if __name__ == '__main__':
url_queue = queue.Queue()
data_queue = queue.Queue()
for i in range(1, 201):
url_queue.put(f"https://www.cnblogs.com/#p{str(i)}")
fq = open("text2_data.txt", "w", encoding="utf8")
# 创建生产者线程
for ids in range(5):
t = threading.Thread(target=producer, args=(url_queue, data_queue), name=f"producer {ids}")
t.start()
# 创建消费者线程
for ids in range(2):
t = threading.Thread(target=consumer, args=(data_queue, fq), name=f"consumer {ids}")
t.start()
Lock用于解决线程安全问题
用法一:
import threading
lock = threading.Lock()
lock.acquire() ## 获得锁
try:
# do something
finally:
lock.release() # 释放锁
用法二:
import threading
lock = threading.Lock()
with lock:
# do something
银行取钱的问题
# lock锁机制,保护线程的数据安全
import threading
import time
lock = threading.Lock()
class Acount:
def __init__(self, monney):
self.monney = monney
def get_money(acount, monney):
with lock:
if acount.monney >= monney:
print("取钱成功!")
acount.monney -= monney
print(f"余额为: {acount.monney}")
else:
print("取钱失败!")
if __name__ == '__main__':
acount = Acount(1000)
t1 = threading.Thread(target=get_money, args=(acount, 800))
t2 = threading.Thread(target=get_money, args=(acount, 800))
t1.start()
t2.start()
线程池的使用
我们知道在在使用多线程时,会不断新建和销毁线程,这会造成一定的开销,线程池的目的就是不会销毁线程,直接供给下一个线程使用,这样可减少一定的开销。
-
语法
-
方式一:使用map函数,简单
from concurrent.futures import ThreadPoolExecute with ThreadPoolExecutor() as pool: results = pool.map(craw, urls) # craw为线程需要执行的函数,urls为所有的线程参数, 返回值是每个线程返回值组合成的列表 for results in results: print(result) -
方式二:futrue模式,更强大
from concurrent.futures import ThreadPoolExecutor, as_completed with ThreadPoolExecutor() as pool: futures = [pool.submit(craw, url) for url in urls] for future in futures: print(future.result()) # 相对于前面,as_completed顺序是不定的 for future in as_completed(futures): print(future.result())实例
-
-
实例
# 线程池的使用 import requests from concurrent.futures import ThreadPoolExecutor, as_completed import time urls = [ f"https://www.cnblogs.com/#p{page}" for page in range(1, 50) ] def spider(url): response = requests.get(url).text return url, len(response) # 第一种方式 start_time = time.time() with ThreadPoolExecutor() as pool: results = pool.map(spider, urls) for result in results: print(result) end_time = time.time() print("使用map方式所需时间: ", end_time-start_time) # 第二种方式 start_time = time.time() with ThreadPoolExecutor() as pool: futures = [ pool.submit(spider, url) for url in urls] # for future in futures: # print(future.result()) for future in as_completed(futures): print(future.result()) end_time = time.time() print("使用submit所需时间: ", end_time-start_time)
多进程
多进程和多线程使用方式是差不多的,如下表:
| 语法条目 | 多线程 | 多进程 |
|---|---|---|
| 引入模块 | from threading import Thread | from multiprocessing import Process |
| 新建 启动 等待结束 | t = Thread(target=func, args=(100,)) t.start() t.join() | t = Process(target=func, args=(100, )) t.start() t.join() |
| 数据通信 | import queue q = queue.Queue() item = q.get() | from multiprocessing import Queue q = Queue() item = q.get() |
| 安全加锁 | from threading import Lock lock = Lock() with lock: # do something | from multiprocessing import Lock() lock = Lock() with lock: # do somethin |
| 池化技术 | from concurrent.futures import ThreadPoolExecutor with ThreadPoolExecutor() as pool: # 方法1 results = pool.map(func, [1,2,3]) # 方法2 futures = pool.submit(func, 1) result = future.result() | from concurrent.futures import ProcessPoolExecutor with ProcessPoolExecutor() as pool: # 方法1 results = pool.map(func, [1,2,3]) # 方法2 futures = pool.submit(func, 1) result = future.result() |
多协程
协程是python个中另外一种实现多任务的方式,只不过比线程更小占用更小执行单元(理解为需要的资源)。 为啥说它是一个执行单元,因为它自带CPU上下文。这样只要在合适的时机, 我们可以把一个协程切换到另一个协程。 只要这个过程中保存或恢复 CPU上下文那么程序还是可以运行的。
-
单线程:
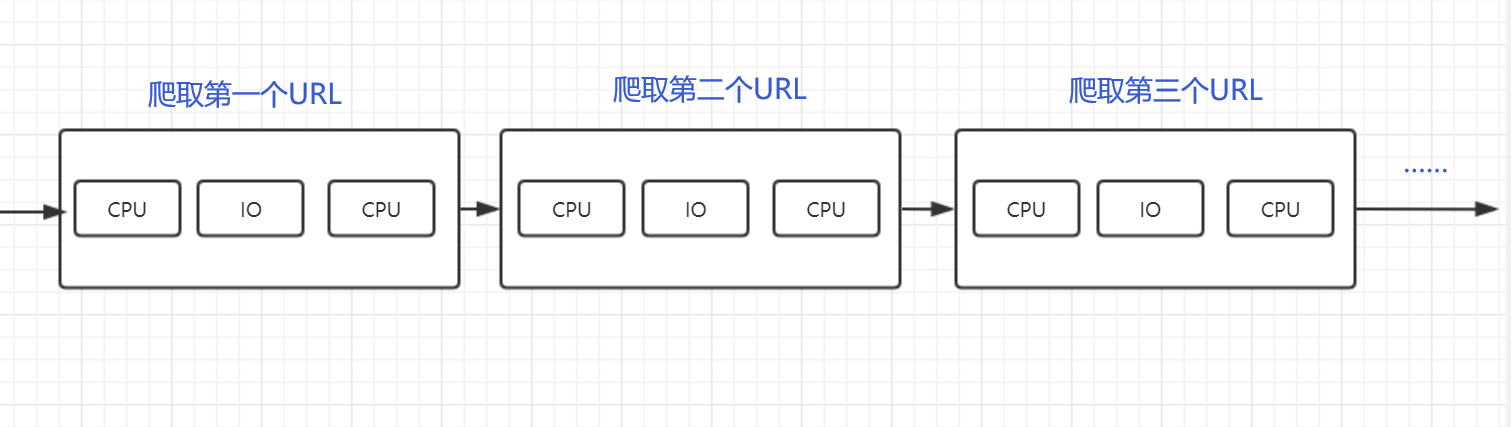
-
多协程:就是在单线程内实现并发
核心原理:用一个超级循环(其实就是while true)循环,配合IO多路复用原理(IO是CPU可以干其他事情)
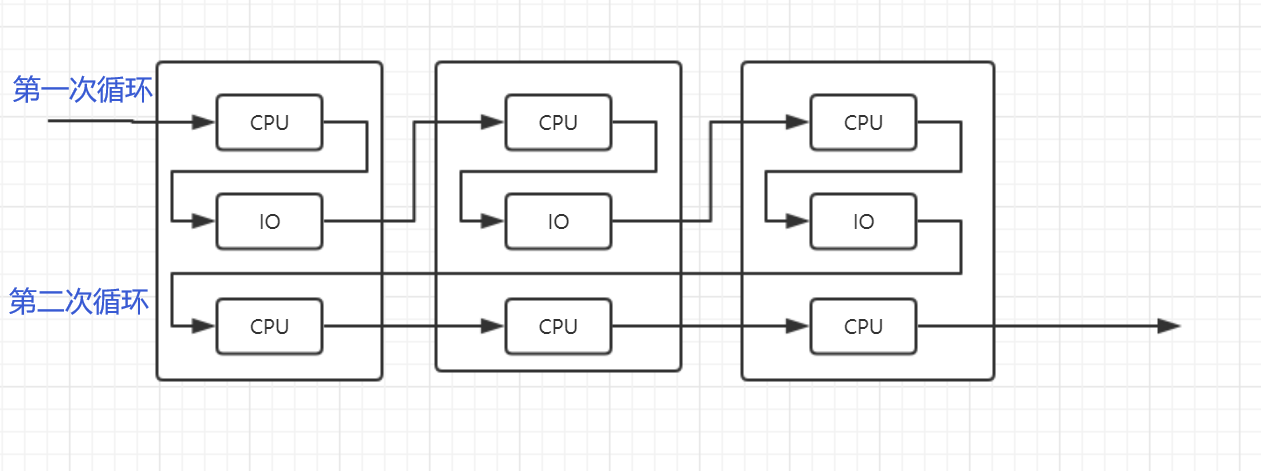
-
异步IO库:asyncio
注意:
- 要用在异步IO编程中,依赖的库不许支持异步IO特性
- requests不支持异步,但aiohttp支持异步
import asyncio # 获取时间循环 loop = asyncio.get_event_loop() # 定义协程 async def myfunc(url): await get_url(url) # 创建task列表 tasks = [loop.create_task(myfunc(ulr) for url in urls)] # 执行爬虫时间列表 loop.run_until_complete(asyncio.wait(tasks))
最后
以上就是爱听歌灰狼最近收集整理的关于提高爬虫效率之python并发编程的全部内容,更多相关提高爬虫效率之python并发编程内容请搜索靠谱客的其他文章。








发表评论 取消回复