1.基本思想
先来个CNN得到各Patch作为输入,再使用transformer做编码和解码
编码方式跟VIT基本一样,重在在解码,Detr假设一张图片中最多有100个物体,直接预测100个坐标框

2.整体网络架构
-
backbone:首先通过卷积得到图片的patch向量,加入位置编码,输入到encoder中
- encoder对backbone的输入进行特征提取,得到K,V(与VIT一样)
- decoder:对输入的100个向量(object queries)根据ecoder提取到的特征进行重构,object queries是核心,让它学会怎么从ecoder提取到的原始特征找到是物体的位置
- prediction heads:对重构后的object queries进行分类和回归
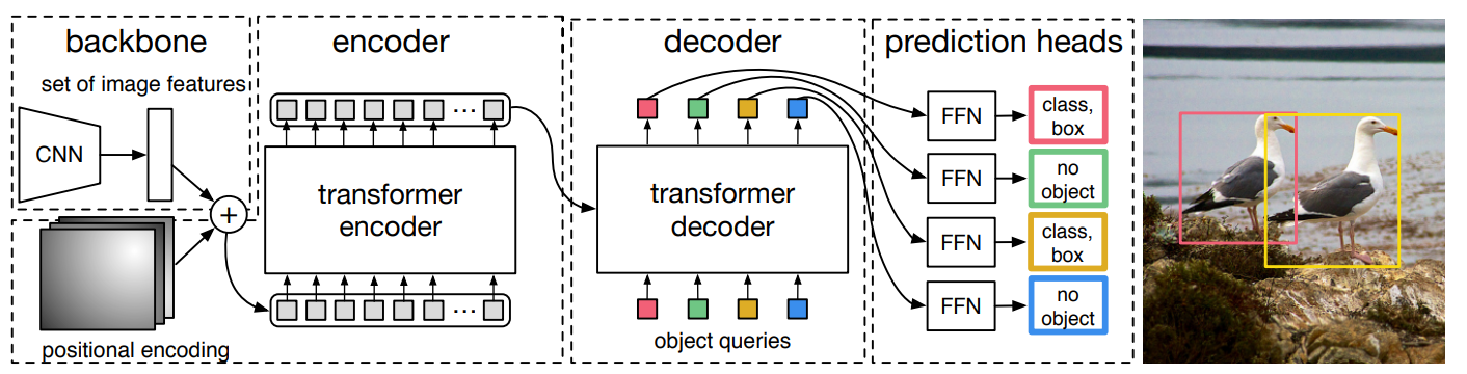
transformer整体架构
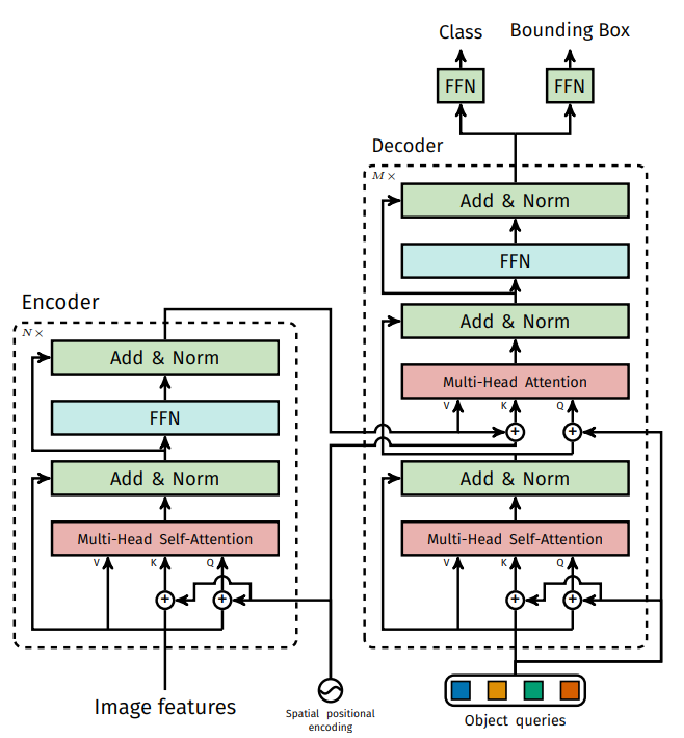
- Encoder与VIT一样,主要任务为得到各个目标的注意力结果,准备好特征
- 解码器首先随机初始化object queries(0+位置编码),然后经过多头自注意力机制,可以理解为首先划分不同的区域以及找出不同区域的关系,然后自注意力结果为queries,encoder输出结果为keys,vakues,做特征的提取
- 解码器通过多层让其学习如何利用输入特征
- 输出层就是100个object queries预测
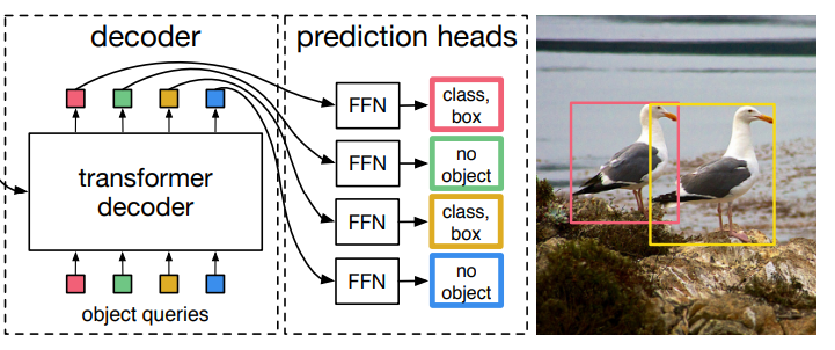
 输出的匹配:
输出的匹配:
对于下面两个图,匈牙利匹配完成,按照LOSS最小的组合,两个为前景,剩下98个都是背景
注意力起到的作用
如下图所示,即使图片有所遮挡,注意力机制依旧能够提取到关注的点

训练的细节
为了使decoder每一层都学习到比较优的参数,decoder每一层都计算损失
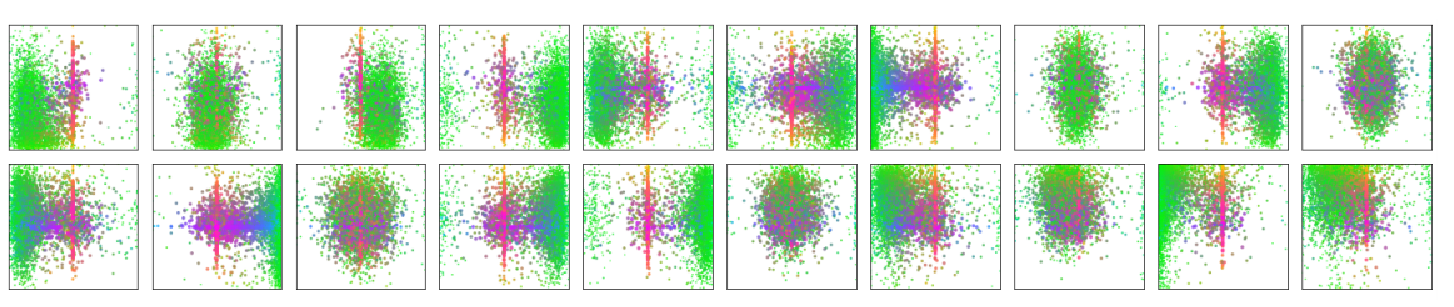
100个queries的作用:
论文中可视化了其中20个,绿色是小物体,红蓝是大物体
基本描述了各个位置都需要关注,而且它们还是各不相同的
最后
以上就是秀丽眼睛最近收集整理的关于transformer系列——detr详解1.基本思想2.整体网络架构 的全部内容,更多相关transformer系列——detr详解1.基本思想2.整体网络架构 内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复