天池大赛产品关联性分析数据集:https://pan.baidu.com/s/1CFxIDu8enrCbj50JQlHiMg
提取码:1234
#首先进行数据预处理
import pandas as pd#读入所有数据
customer = pd.read_csv("D:/天池竞赛/产品关联分析/customer.csv",encoding="gbk")
date = pd.read_csv("D:/天池竞赛/产品关联分析/date.csv",encoding="gbk")
order = pd.read_csv("D:/天池竞赛/产品关联分析/order.csv",encoding="gbk")
product = pd.read_csv("D:/天池竞赛/产品关联分析/product.csv",encoding="gbk")#数据预处理——空值检测
pd.isnull(customer).sum()
pd.isnull(date).sum()
pd.isnull(order).sum()
pd.isnull(product).sum()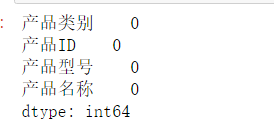
#数据预处理——重复值检测
customer.duplicated().sum()
date.duplicated().sum()
order.duplicated().sum()
product.duplicated().sum()

#对于订单表中完全重复数据进行删除,提高数据准确性
order.duplicated().sum()
order_1 = order.drop_duplicates()order_1.duplicated().sum() 
#直接提取相关数据
df1 = order_1[["订单日期","产品ID","客户ID","产品型号名称","产品名称"]]
df1 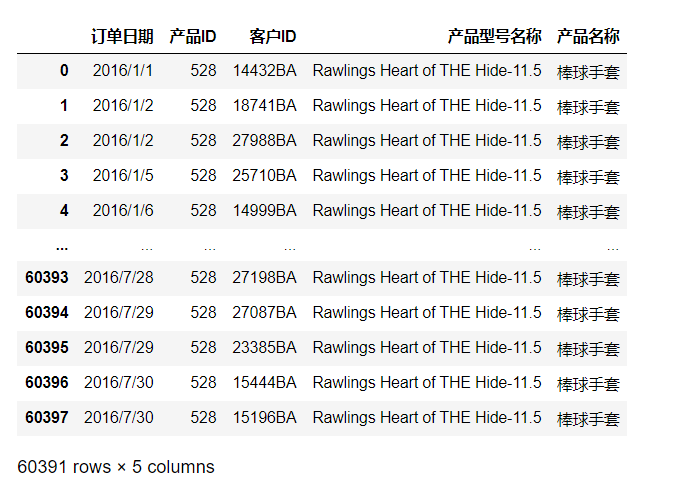
#关联规则中不考虑同一客户购买同样日期购买同样商品的数据
df1.drop_duplicates() 
#使用groupby语句筛选同一客户在同一日期下购买的产品名称
df2 = df1.groupby(["订单日期","客户ID"]).apply(lambda x:x["产品名称"].tolist())
product_list=[list(set(i)) for i in df2]
product_list 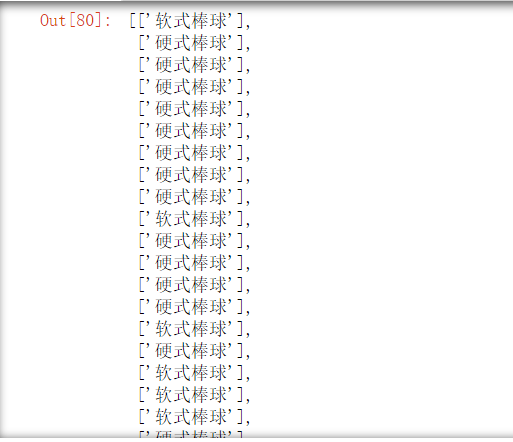
#apriori需要使用mlxtend库
pip install mlxtend -i https://pypi.tuna.tsinghua.edu.cn/simple some-package支持度(Support):支持度可以理解为物品当前流行程度。 支持度 = (包含物品A的记录数量) / (总的记录数量)
置信度(Confidence):置信度是指如果购买物品A,有较大可能购买物品B。 置信度( A -> B) = (包含物品A和B的记录数量) / (包含 A 的记录数量) 结果(>1,提升;=1没有关联;<1降低)
提升度(Lift):提升度指当销售一个物品时,另一个物品销售率会增加多少。 提升度( A -> B) = 置信度( A -> B) / (支持度 A)
#导入库文件
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori
te = TransactionEncoder()
one_hot = te.fit(product_list).transform(product_list)#apriori只支持特定格式数据,所以进行独热编码
data = pd.DataFrame(one_hot, columns=te.columns_)#用dataframe格式表示独热编码
#使用apriori频繁项集,后续关联规则使用
support = apriori(data,min_support=0.02,use_colnames=True)#min_support给定最小支持度为0.02
support.sort_values(by = "support")#查看支持度可以进行相关分析,当单个商品支持度大于组合商品支持度时,说明商品之间是排斥的 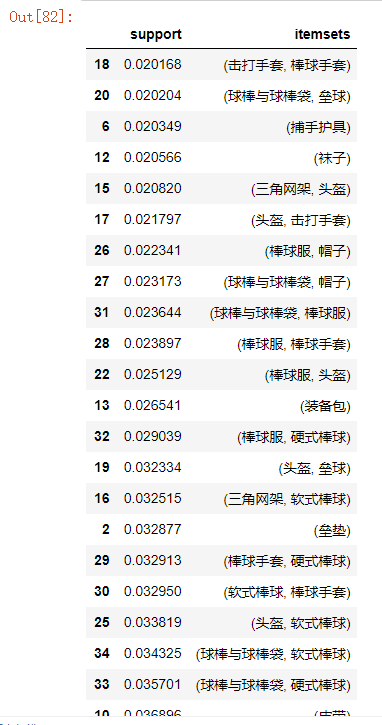
association_rules(df, metric="confidence", min_threshold=0.8, support_only=False):
参数介绍:
- df:是 Apriori 计算后的频繁项集。
- metric:可选值['support','confidence','lift','leverage','conviction']。 里面比较常用的就是置信度和支持度。这个参数和下面的min_threshold参数配合使用。
- min_threshold:参数类型是浮点型,根据 metric 不同可选值有不同的范围, metric = 'support' => 取值范围 [0,1] metric = 'confidence' => 取值范围 [0,1] metric = 'lift' => 取值范围 [0, inf] support_only:默认是 False。仅计算有支持度的项集,若缺失支持度则用 NaN填充。
confidence = association_rules(support,metric="confidence",min_threshold=0.15)
confidence
#support表示支持度,confidence表示置信度,lift表示提升度,通过以上指标即可判定商品之间的关联性,反映准确商品堆放规则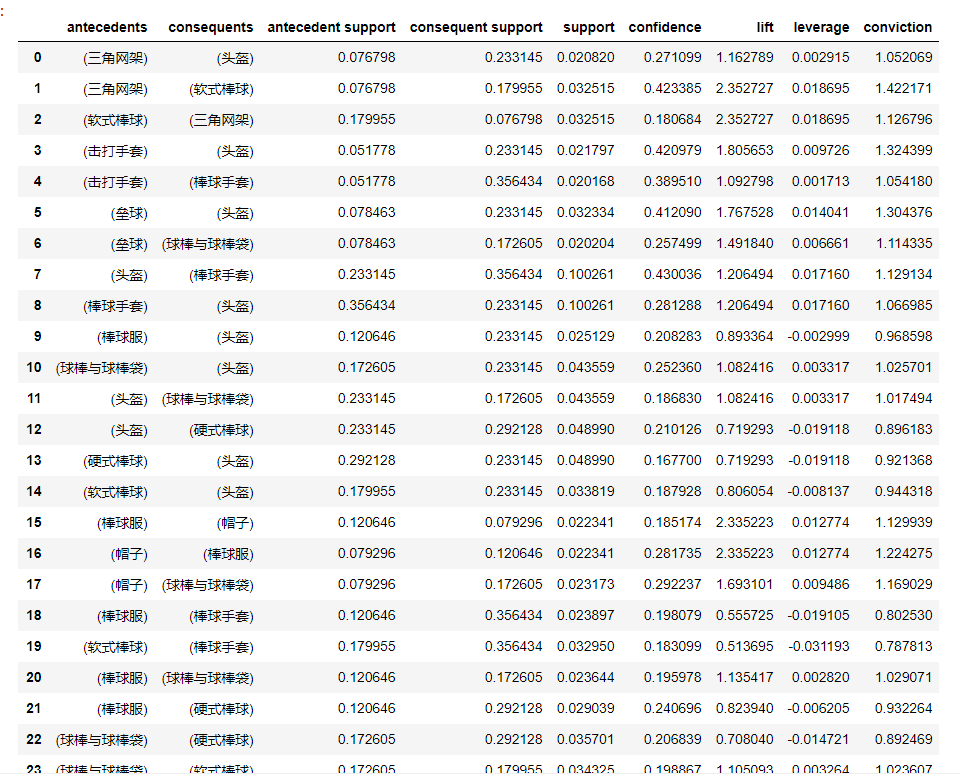
最后
以上就是害怕豆芽最近收集整理的关于超市产品关联性分析——天池竞赛的全部内容,更多相关超市产品关联性分析——天池竞赛内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复