-
启动hadoop集群,在其他节点用jps命令查看少了DataNode进程?
原因:当我们多次使用或在不同节点进行hadoop namenode -format格式化namenode时,会在namenode数据文件夹(这个文件夹为自己配置文件中dfs.name.dir的路径)中保存一个current/VERSION文件,记录clusterID,这样导致datanode和namenode之间的clusterID不一致 ,或者各个节点的datanode的clusterID不一致。
解决:如果没有重要数据,删除各个节点datanode,namenode下的version目录,然后在主节点重新格式化hadoop namenode -format,再将datanode,namenode下的version目录复制到其他节点。
-
写数据到hdfs时提示没有可用资源,hadoop进入安全模式,同时刷新hadoop UI界面在live nodes发现少了一个可用的节点,该怎么解决啊?错误如下:
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.hdfs.server.namenode.SafeModeException): Cannot add block to /user/hadoop_logs/cdh5.11.1-centos7.tar.gz._COPYING_. Name node is in safe mode. Resources are low on NN. Please add or free up more resources then turn off safe mode manually. NOTE: If you turn off safe mode before adding resources, the NN will immediately return to safe mode. Use "hdfs dfsadmin -safemode leave" to turn safe mode off. at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkNameNodeSafeMode(FSNamesystem.java:1327) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.analyzeFileState(FSNamesystem.java:3210) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getNewBlockTargets(FSNamesystem.java:3071) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:3031) at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:724) at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:492) at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java) at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:616)原因:由于hadoop有自动保护机制,在某个节点资源空间不足时,自动中断了数据的上传,进入保护模式。
解决:查看错误信息,定位是哪一个节点机器的磁盘空间不足,进行扩容。再次启动hadoop集群,看看live nodes是否正常,执行命令hadoop dfsadmin -safemode leave离开安全模式,再次进行数据的上传。
-
集群模式提交java spark分析任务时,如创建缓冲区,报错提示找不到com.supermap.bdt.geotool以及logger工具类,无法初始化,是什么问题啊?提交的分析如果不涉及udb,只是json或hdfs却又能成功。错误信息如截图:
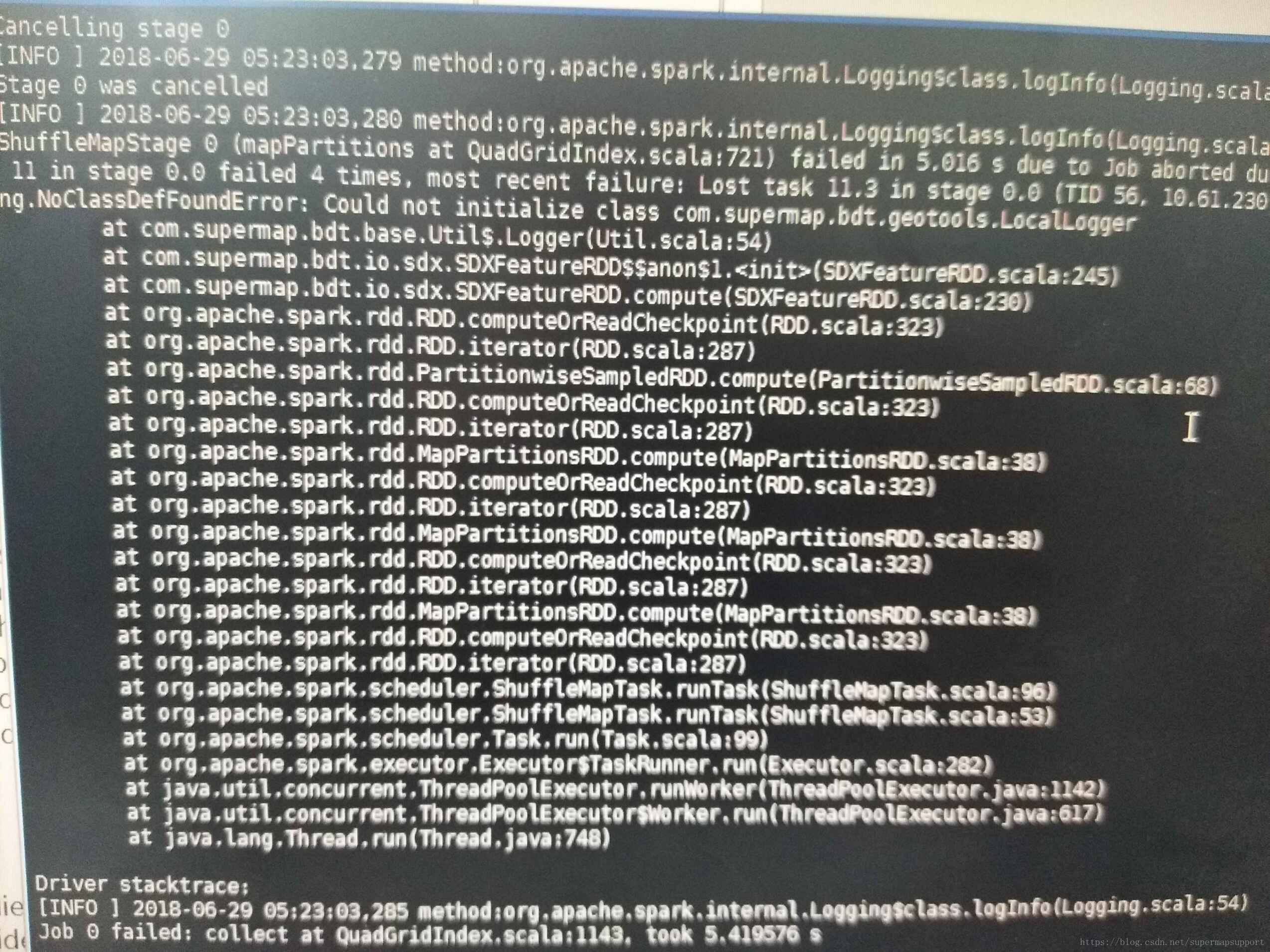
原因:任务执行时会动态修改log4j_geotools.properties 文件,如果任务异常终止,会导致 log4j_geotools.properties文件损坏或丢失。
解决:检查每个集群节点java组件bin目录下是否有该文件以及文件大小是否一致,将文件保持一致。 -
Idea工具里启动java spark程序创建缓冲区,报错Sink class org.apache.spark.metrics.sink.MetricsServlet cannot be instantialized初始化spark错误?错误截图如下:
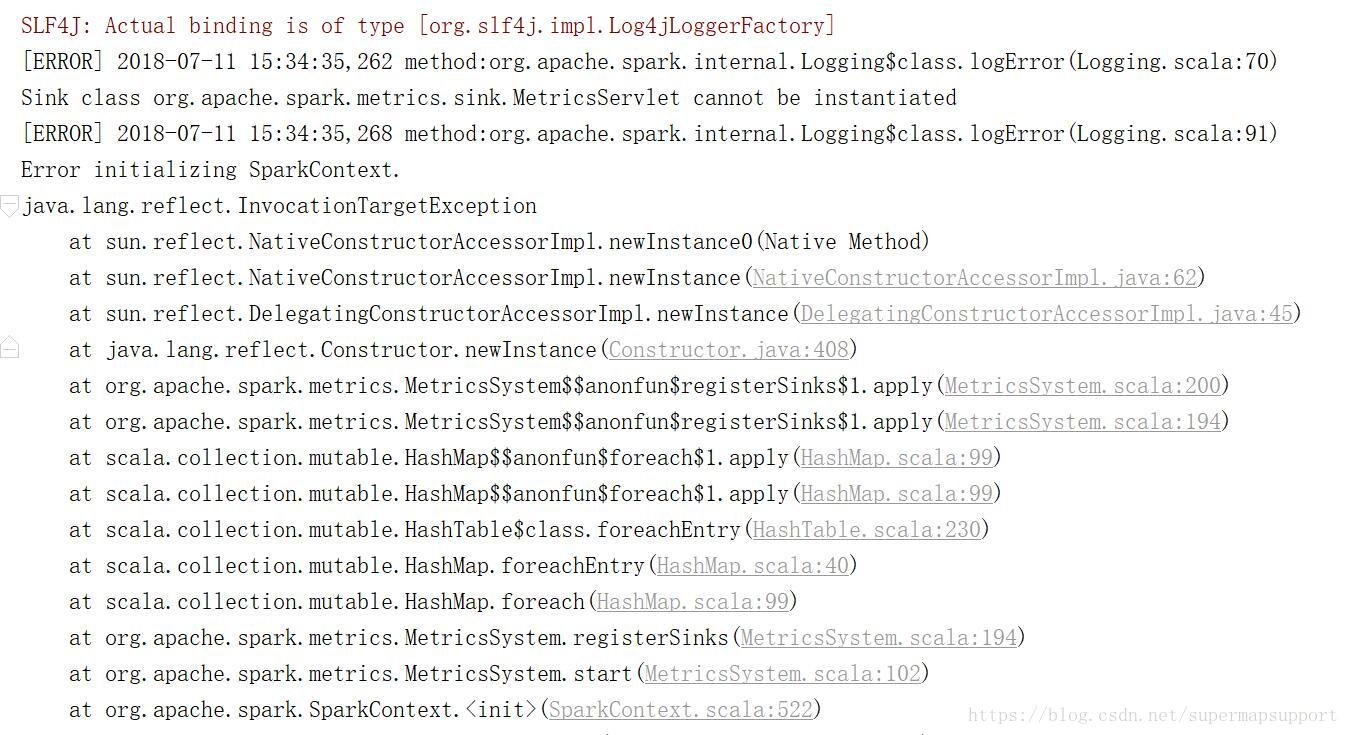
原因:引用的jar包顺序不对导致,由于java spark组件依赖于原生的spark组件包,故如果先引用的是java spark组件包,后引用spark原生包就会出现该问题。解决:先引用spark原生jar,再引用java spark组件的jar包。
-
集群模式提交java spark缓冲区任务时,报错提示链接不到依赖库java.lang.UnsatisfiedLinkError:
com.supermap.data.EnvironmentNative.jni_GetBasePath()Ljava/lang/String,是什么原因 啊?错误 如下截图:
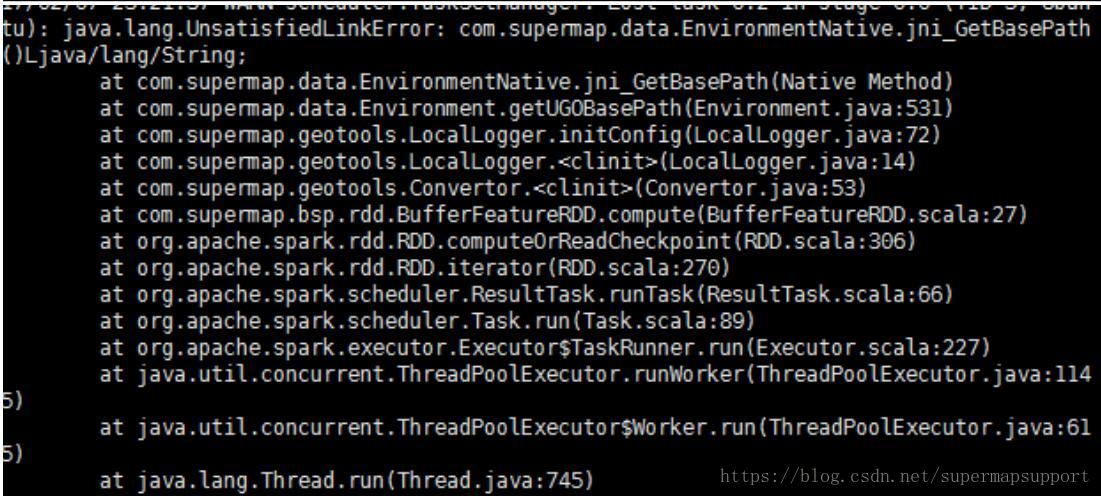
原因:可能是未安装x11等依赖库,也可能是jdk1.7的libmawt.so问题,也可能是java组件与java spark组件包版本不一致导致。解决:安装依赖库./dependencies_check_and_install.sh install -y ,使用 iObjects Java
中 libmawt.so 替换到 jdk1.7.0_80/jre/lib/amd64/headless 中的 libmawt.so , 确保java组件与java spark组件包版本一致,如都为901 。
最后
以上就是爱撒娇帽子最近收集整理的关于spark及hadoop常见问题集锦的全部内容,更多相关spark及hadoop常见问题集锦内容请搜索靠谱客的其他文章。








发表评论 取消回复