博主简介
博主是一名大二学生,主攻人工智能研究。感谢让我们在CSDN相遇,博主致力于在这里分享关于人工智能,c++,Python,爬虫等方面知识的分享。 如果有需要的小伙伴可以关注博主,博主会继续更新的,如果有错误之处,大家可以指正。
专栏简介: 本专栏主要研究python在人工智能方面的应用,涉及算法,案例实践。包括一些常用的数据处理算法,也会介绍很多的Python第三方库。如果需要,点击这里 订阅专栏。
给大家分享一个我很喜欢的一句话:“每天多努力一点,不为别的,只为日后,能够多一些选择,选择舒心的日子,选择自己喜欢的人!”

目录
Tesseract OCR的安装与配置
基于Pytesseract的字符识别
条形码检测与识别
基于百度AI的智能图像识别
通用物体识别
车牌识别
文末寄语
Tesseract OCR的安装与配置
Tesseract OCR可以跨平台应用于Windows,Linux,macOS等不同操作系统。博主用的是windows10操作系统。
Tesseract OCR的官网:Tesseract OCR下载。
下载后的Tesseract OCR安装后,需要配置环境,具体的配置方法就和我们平时配置c++环境相似。复制好Tesseract OCR文件所在路径,添加到环境变量中就可以了。这里博主推荐一篇文章:http://t.csdn.cn/A5Hc7
配置好环境后,打开cmd控制台,输入命令“tesseract -v”,如果出现版本标识,则为配置成功。
Tesseract OCR是可以单独的使用取识别图片的,例如,在命令行中输入以下的命令:
tesserct test.jpg test.text -1 chi_sim
其中,test.jpg是包含字符的图片,test.text是输出结果文件。-1为语言包选项,默认为英语,chi_sim为中文识别包。
博主这里要介绍的是如何使用python来进行文本识别,在此之前,我们需要先下载Pytesseract库。
pip install pytesseract -i Simple Index
基于Pytesseract的字符识别
利用Pytesseract进行字符的识别,主要通过调用image_to_string()函数来实现。以下的代码可以进行简单的字符识别。
import pytesseract from PIL import Image image=Image.open('D:Image\test.png') result=pytesseract.image_to_string(image) print(result)
Output exceeds the size limit. Open the full output data in a text editor
11:03 352 Big “28110004, < fifiififii 1. They who cannot do as they would,must do as th ey can. $§E§DEfifiiiE3fi§73fifi7flo 2. When an opportunity is neglected,it never comes back to you. ?I‘J'L7FEJ9iE‘J‘7Ffifié; ?HLfi—iiiféfifi 3 What may be done at any time will be done at no time. EiEiTEJ‘iIEfiB—JME’JEEHEIE'EEEflBfl‘iIfiWF iflflg$ 1m 4. Tomorrow comes never. tflfifififififiio 5 ?til]flfl9€¥,ifl7i<§ EEEO We can be disappoin ted, but not blind. 6. He that thinks his business below him will alway s be above his business Eh“ p,fl<7_i'/JFfi EEEEF}? iEEo 7. One today is worth two tomorrows. —’IV7‘3EH$
...< E Q [E]

通过上面的运行结果和原图片的对比可以发现,对于英文的识别是可以比较准确地识别,而出现的乱码则是由于其中有中文,只需要转换一下即可。
result=pytesseract.image_to_string("D:/Image//test.jpg",lang='chi_sim')
对于颜色较深或者文本文字含有多种不同语言的图片,识别起来会出现乱码的情况,识别的精度也会降低。
条形码检测与识别
条形码(Barcode)也称条码,是将宽度不等的多个黑条和白条,按照一定的编码规则排列,用来表达一组星系的图形标识符。常见的条形码是由反射率想相差较大的黑条(简称条)和白条(简称空)排成的平行图案。 条形码可以标注处武平的生产国,制造产家,商品名称,生产日期,图书分类号等重要的信息。因而在商品流通中起到了广泛的应用,不仅仅在此领域有很大的发展,在其他领域也有很大的发展。
条形码一般有8个区域,:左侧空白区,起始符,左侧数据符,中间分隔符,右侧数据符,效验符,,终止符,右侧空白区。
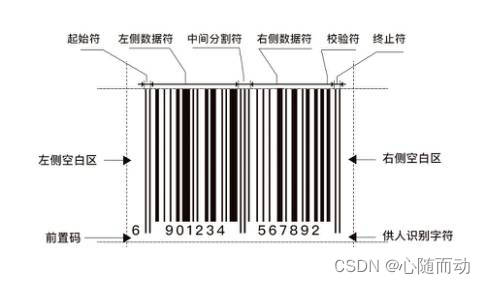
条形码有多种,在我国广泛的使用的是EAN13条形码(以下简称条形码)。该条形码一共有13位,前2~3位称为前缀,表示国家,地区或者某种特定的商品类型,例如,中国区条形码开头位690~699;前缀后的4~5位称为厂商代码,表示产品制造商;厂商代码后5位称为商品代码,表示具体的商品项目;最后一位是效验码,根据前12位计算而得,可以用来防伪或者识别效验。 如果按照一定步骤处识别出的前12位数据计算结果和识别出的效验码进行比对,如果结果相等,则正确,若不相等,则需重新识别,纠错再效验。
效验码的计算方法:
1.偶位数数值相加并称以3.
2不含效验位的奇位数数值相加。
3.前两步结果相加。
4用10减去上面相加结果的个位数。
5.最终结果即为效验码。

以下示例代码可用于检测一幅图像中是否有条形码:
import numpy as np
import argparse #解析命令行参数
import cv2
import imutils #opencv辅助工具包
'''
ap=argparse.ArgumentParser()
ap.add_argument('-i','--Testimage.jpg',required=True,help='path to the image file')
args=vars(ap.parse_args())
'''
#灰度化处理
image=cv2.imread('D:ImageTestimage.jpg')
gray=cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
#用sobel算子计算x,y方向上的梯度
ddepth=cv2.cv.CV_32F if imutils.is_cv2() else cv2.CV_32F
gradx=cv2.Sobel(gray,ddepth=ddepth,dx=1,dy=0,ksize=-1) #sobel算子横向边缘检测
grady=cv2.Sobel(gray,ddepth=ddepth,dx=0,dy=1,ksize=-1) #sobel算子纵向边缘检测
'''
从x-grdient中减去y-gradient的减法操作,
最终得到包含高水平和低垂直梯度的图像区域
'''
gradient=cv2.subtract(gradx,grady)
gradient=cv2.convertScaleAbs(gradient)
'''
利用9*9的内核对梯度图进行平均模糊处理
利用opencv中的threshold(src,threah,maxral,cv2.THRESH_BINARY)进行二值化处理。
第一个参数是图像,第二个参数是阈值,第三个是最大值,第四个是方法选择,默认为0,即cv2.THRESH_BINARY
'''
blurred=cv2.blur(gradient,(9,9))
(_,thresh)=cv2.threshold(blurred,225,255,cv2.THRESH_BINARY)
#消除间隙
kernel=cv2.getStructuringElement(cv2.MORPH_RECT,(21,7))
closed=cv2.morphologyEx(thresh,cv2.MORPH_CLOSE,kernel)
'''
进行4次腐蚀,然后进行4次膨胀
'''
closed=cv2.erode(closed,None,iterations=4)
closed=cv2.dilate(closed,None,iterations=4)
#找到图像中条形码的区域
cnts=cv2.findContours(closed.copy(),cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)
cnts=cnts[0] if imutils.is_cv2() else cnts[1]
c=sorted(cnts,key=cv2.contourArea,reverse=True)[0]
#为最大轮廓确定最小边框
rect=cv2.minAreaRect(c)
box=cv2.cv.BoxPoints(rect) if imutils.is_cv2() else cv2.boxPoints(rect)
box=np.int0(box)
#显示检测到的条形码
cv2.drawContours(image,[box],-1,(0,255,0),3)
cv2.imshow('Barcode Detection',image)
cv2.waitKey(0)
对于检测出的条形码就可以进行字符识别:
from PIL import Image import pytesseract import cv2 threshold=140 #采用阈值分割法进行二值化,threshold为分割点 table=[] for i in range(256): if i<threshold: table.append(0) else: table.append(1) rap={'O':'0','I':'1','L':'1', 'Z':'2','S':'8'}; def GetBarcode(name): im=Image.open(name) #im=cv2.imread(name) imgry=im.convert('L')#转换为灰度图像 #imgry.save(name+'g') #保存图像 out=imgry.point(table,'1') #图像二值化处理 #out.save(name+'b') text=pytesseract.image_to_string(out) #识别纠错处理 text=text.strip() text=text.upper() for r in rap: text=text.replace(r,rap[r]) return text barcode=GetBarcode('D:Image\test.png') print(barcode)结果:5 012345 67890

基于百度AI的智能图像识别
百度AI开放平台是一个面型第三方开发者的交互技术平台,该频台提供包括语音合成,文字识别,图像识别,身份验证那等诸多语言AI编程接口以及相应的说明文档。
这里,博主建议大家先注册账号百度AI开放平台-全球领先的人工智能服务平台 ,然后找到开放能力中你想要的功能,然后创建应用,获取个人唯一APIKey,Secret Key。

然后你就可以得到一个SDK文件。然后在setup.py文件的目录下执行“python setup.py install”命令即可。 也可以直接使用pip install baiidu-aip.
通用物体识别
通用物体识别要用到AipImageClassify,它是基于baiduAI图像识别引擎的API。利用该方法的代码如下:
这里需要用到自己获取的API_KEY,博主的代码不可以直接使用,需要你们自己去注册。
from aip import AipImageClassify #导入通用物体识别引擎 APP_ID='30428562' API_KEY='TNRLIT4ICRYFOcV0kewltQP7' SECRET_KEY='HjPMiCW9tpAuNdVeA2KP2KuXdyg3zKiy' client=AipImageClassify(APP_ID,API_KEY,SECRET_KEY) #构建识别与引擎对象 #读入图像 def get_file_content(filePath): with open(filePath,'rb') as fp: return fp.read() image=get_file_content('D:Imageinsert.jpg') ret=client.advancedGeneral(image) #调用通用物体识别接口并返回结果 print(ret)初次使用,可能会报错,这是由于你的API访问次数受限,用的是百度的,需要充会员,所以你懂的。
车牌识别
车牌识别与前面的通用物体识别流程基本相似,稍有不同的是,用AipOcr代替AipImageClassify对象。而车牌识别主要是对一个图像中的字符进行识别。
示例代码如下:
#车牌识别 from aip import AipOcr import cv2 as cv import numpy as np APP_ID='30429525' API_KEY='gk5YyWAxggZGPmFtqGLQraeF' SECRET_KEY='I0yINQbTicjmAWZDfA8mlFWbvGKMx5EX' client=AipOcr(APP_ID,API_KEY,SECRET_KEY) def get_file_content(filePath): with open(filePath,'rb') as fp: return fp.read() image=get_file_content('D:Image\test1.jpeg') options={} options['multi_detect']='true' #支持多车牌识别 ret=client.licensePlate(image,options) #调用API进行车牌识别 result=ret['words_result'] #将车牌识别结果保存在字典中 img=cv.imread('D:Image\test1.jpeg') for i in range(len(result)): plate_num=result[i]['number'] #显示被识别的车牌 loc_coordinates=result[i]['vertexes_location'] #显示出车牌坐标 print('Plate Number:',plate_num) print('Location',loc_coordinates) #用矩形来标记所识别的车牌的位置 cv.rectangle(img,(np.int(loc_coordinates[0]['x']),np.int(loc_coordinates[0]['y'])), (0,255,0),2,cv.LINE_8,0) cv.imshow('result',img) cv.waitKey(0) cv.destroyAllWindows()

文末寄语
很抱歉,由于我在使用一些库的时候出现了安装错误,一直没有解决,所以就减少了人脸识别的博客。这里就只介绍了文本识别。后续我会在OpenCV专栏中将人脸识别算法补充进去。最后,祝大家身体健康,万事如意,学习进步!

最后
以上就是陶醉世界最近收集整理的关于Tesseract OCR与文本智能识别Tesseract OCR的安装与配置基于Pytesseract的字符识别条形码检测与识别基于百度AI的智能图像识别 文末寄语的全部内容,更多相关Tesseract内容请搜索靠谱客的其他文章。








发表评论 取消回复