
本篇文章我们从网易云音乐的推荐功能出发,结合我的实习工作,聊一聊互联网的常用推荐策略。
首先来回顾一下云音乐的推荐功能。
网易云音乐推荐
音乐推荐是创始人丁磊先生愿景最直接的体现,也是网易云音乐的主推功能和核心竞争力所在,备受用户推崇。
推荐算法简单说就是在海量的用户数据(行为记录等)中对用户进行划分,对同一群体的用户推荐其他用户喜欢的音乐。
这其中需要给音乐分类并建立评分细则、建立用户模型、寻找相似用户,基于用户的行为数据将歌曲分类匹配——实现“盲听”。
网易云将音乐推荐分成三个部分:私人FM、每日歌曲推荐、推荐歌单。
1. 从准确性、多样性角度分析
私人FM
准确性低、多样性高
多样性高能为用户带来新鲜感,如果发现了一首从未听过但特别喜欢的歌,会带来惊喜感,调动用户正面情绪。
可是由于准确性低,很可能新歌很不被用户喜欢,所以在私人FM在播放界面设置“删除”、“下一首”两个按键便于用户切换歌曲。
每日歌曲推荐
准确性高、多样性低
准确性高使得每日推荐的20首歌曲比较好的满足用户口味,但是存在音乐类型单一化的问题,因此设置了播放列表以提供用户浏览、操作的权利,弥补曲目单一化带给用户的失望。
推荐歌单
准确性中、多样性中
推荐歌单有别于其他两个个性化推荐功能,它准确性多样性的阈值不只是由算法决定的,更多的是它功能形式所决定的。
首先把功能的面向对象分为两类,一类是用户,一类是UGC歌单,系统分别为歌单和用户加标签以提高准确度,由于UGC歌单是由很多用户创建,所以UGC歌单就具有多样性,两者糅合从而保证了准确度和多样性共存。
2. 从操作流程上分析
三个功能从看见功能按键到最终获得推荐曲目的步骤:
-
看见私人FM>点击私人FM>获取音乐
-
看见每日歌曲推荐>点击每日歌曲推荐>看见推荐列表>筛选喜欢曲目>点击喜欢曲目>获取音乐
-
看见推荐歌单>点击推荐歌单>跳转歌单页面>发现类型标签>筛选类型标签>点击类型标签>看见标签下的推荐歌单>筛选歌单>点击歌单>浏览歌单列表>筛选喜欢歌曲>点击喜欢歌曲>获取音乐
可以发现三种方式获取推荐音乐的操作流程由简入繁。
3. 从用户使用阶段分析
三个功能对应着三种用户阶段:
私人FM-新用户:
私人FM位于首页黄金位置,新用户初次体验的产品功能时大概率点击这个按键,所以要简化用户使用流程,用户在快速感受产品个性化推荐的魅力后才产生继续了解其他功能的欲望。
每日歌曲推荐-普通用户:
新用户使用私人FM过后需要不一样的体验来满足个性化需求。
每日20首歌曲推荐对用户来说是可预知的,20首上限的设定给用户物以稀为贵的感觉,会珍惜每日的推荐,而每日更新无法回看以往推荐的设定,会让用户觉得一天不看就错过了什么的紧迫感。
推荐算法设定了基于不同用户行为的权重,“下载”最高,收藏、搜索、分享其次,此外你也可以点击“不感兴趣”,或许会避开这类歌。

推荐歌单-深度用户:
歌单是云音乐连接个性化推荐和社交的重要桥梁,推荐歌单是个性化推荐功能最后一环。
在深度体验了推荐歌单之后,用户会得到歌单可被分享和推荐的认识,很可能会产生自建歌单的冲动。
而歌单在云音乐中具有社交属性,用户可以互相收藏、评论、分享歌单,而且歌单在个人主页中也反映了个人音乐风格,让用户能够更好地展现自己给他人。
4. 从参与元素分析
-
私人FM:系统
-
每日歌曲推荐:系统+自己
-
推荐歌单:系统+自己+其他用户
欧氏距离vs余弦相似度
在线下导购时代,导购员会通过系统的话术掌握消费者的情况,来推荐商品。
类比导购员推销时的思维逻辑,我们可以得到音乐推荐算法需要解决的三个核心问题:
-
将用户信息转化为用户类型;
-
了解曲目的归属类型;
-
将不同类型的用户与不同类型的曲目对应;
我们怎么量化两个事物之间的相似度呢?常见的方法是利用欧式距离和余弦相似度。
以A、B用户间相似度为例:

利用欧式距离时,我们把A、B用户看做两点,用两点间距离表示二者相似度。
使用余弦相似度时,则把二者看成同一坐标系下的两个向量。两个向量间夹角大小反应出他们的相似度,夹角越小则相似度越大。二维空间向量表示为r(x1,x2),多维空间向量表示为r(x1,x2…,xn)
比如,假设用户有5个维度
对流行的喜欢程度(1~5分),对摇滚的喜欢程度(1~5分),对民谣的喜欢程度(1~5分),对说唱的喜欢程度(1~5分),对爵士的喜欢程度(1~5分)。
用户A:对流行的喜欢程度3,对摇滚的喜欢程度1,对民谣的喜欢程度4,对说唱的喜欢程度5,对爵士的喜欢程度0,用户A可以用向量表示为r_A (3,1,4,5,0)
一个用户B:对服装的喜欢程度3,对家居的喜欢程度4,对3C的喜欢程度5,对图书的喜欢程度0,对化妆品的喜欢程度2,用户B可以用向量表示为r_B (3,4,5,0,2)
对于向量A和B而言,他们的在多维空间的夹角可以用向量余弦公式计算:

余弦相似度取值在0到1之间,0代表完全蒸饺,1代表完全一致。那么用户A和B的相似度计算:
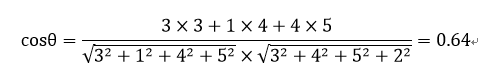
即代表了两个用户音乐偏好的相似程度。
余弦相似度是一种很好的数据策略,对计算用户类型是很好的解决方法,我们来对比分析它和欧式距离。
上图中,我们反方向延长点A,很明显向量A和B之间夹角余弦值不变,但欧式距离发生改变。也就是说,利用欧式距离更能突出数值绝对差异,因此常用于歌曲间相似度的计算。
例如,喜欢A歌曲的用户数量是10000,喜欢B歌曲的用户数是20000,因为样本足够大,我们认为用户对歌曲喜爱的程度相同,也就是相同的分数,那么直接通过数量上的差异来计算相似程度即可。
由此可见,小到一个数学公式,大到一个数据模型甚至是推荐系统,都没有单纯的对错之分,只有是否适合产品需求,能在有限的计算量内结合情景满足预期。先入为主的方法论是数据策略工作中的大忌。
常见推荐方法
推荐和搜索本质有相似的地方:
-
搜索满足用户从海量数据中迅速找到自己感兴趣内容的需求,属于用户主动获取。
-
推荐则是系统从海量数据中根据获取到的用户数据,猜测用户感兴趣的内容并推荐给用户,属于系统推荐给用户。
本质上都是为了在这个信息过载的时代,帮助用户找到自己感兴趣的东西。
这里我们介绍四种常见的推荐方法:
-
基于歌曲的推荐
-
基于歌曲的协同过滤
-
基于用户的协同过滤
-
基于标签的推荐
1. 基于歌曲的推荐
基于歌曲的推荐是比较基础的推荐方法,根据我们播放收藏或下载的某类型的歌曲,推荐这种类型下的其他歌曲。
这种方式很容易被理解,但是比较依赖内部曲库完善的分类体系,且需要用户有一定的数据积累,不适用于冷启动。
2. 基于歌曲的协同过滤
协同过滤与传统的基于内容分析直接进行推荐不同,协同过滤会分析系统已有数据,并结合用户表现的数据,对该指定用户对此信息的喜好程度预测。
基于歌曲的协同过滤,通过用户对不同歌曲的评分(下载收藏评论分享对应不同分数)来评测歌曲之间的相似性。
基于歌曲之间的相似性做出推荐,一个典型的例子是著名的“啤酒加尿布”,就是通过分析知道啤酒和尿布经常被美国爸爸们一起购买,于是在尿布边上推荐啤酒,增加了啤酒销量。
计算用户u对歌曲j的喜爱程度:

N(u)表示与用户有关联的歌曲歌单等集合,w_ji表示歌曲/歌单j和i的相似度,r_ui表示用户对i的打分。

推荐时也要综合考虑其他业务数据,比如两首歌曲越多的被加入两个歌单,则认为两首歌越相似。
3. 基于用户的协同过滤
基于用户的协同过滤是通过用户对不同歌曲/单的行为,来评测用户之间的相似性,基于用户之间的相似性做出推荐。
这部分推荐本质上是给相似的用户推荐其他用户喜欢的歌曲,一句话概括就是:和你类似的人还喜欢下列歌曲。
计算用户u对歌曲i的喜爱程度:
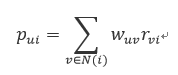
N(i)表示对歌曲/单i有过行为的用户集合,w_uv是用户u和用户v之间的相似度,r_vi表示用户v对歌曲/单i的打分。

4. 基于标签的推荐
歌曲有标签,用户也会基于行为被打上标签,系统通过标签将二者关联。

根据标签进行推荐需要产品在初期就有标签概念,网易云音乐不同的曲目类型是天然的素材标签,通过对UGC内容的处理和对用户行为的数据分析则可以得到用户标签。
总结
在广场舞大妈都在谈论AI的时代,基于机器学习的推荐算法实在算不上风口。但是没有任何一种推荐方法或系统能适用全部的情形,在真正实现过程中一定要对算法有熟悉的掌握,另外和一些前辈的交流让我认识到,一个优秀的pm必备的素养之一就是对每一条业务线深刻的理解。
在构建一个推荐方法时,我们一般会用到加权、降权、屏蔽。一个方法是否能支持灵活调节权重,后期是否能持续迭代,都是要通过不断的测试验证,最终让数据说话。
根据一些用户反馈和我自身的使用感受,提一些建议:
-
网易云音乐推荐算法把用户最近的行为权重置高,因此系统容易大量推荐相似类型的歌曲,使用户审美疲劳、兴奋度降低。建议在算法中加入用户使用场景的分析,并对同类型歌曲出现的次数、位置加以限制;
-
针对长尾冷门歌曲,由于数据量相对较少,更要重视效果反馈;深度挖掘数据,丰富推荐元素,比如根据某位用户喜爱歌手的创作/成长背景,推荐影响该歌手的音乐、专辑、歌手;
网易云的情怀令人欢喜,在商业化的今天弥足珍贵。祝越来越好。
最后,万望不吝赐教。
最后
以上就是暴躁滑板最近收集整理的关于网易云音乐 推荐算法的全部内容,更多相关网易云音乐内容请搜索靠谱客的其他文章。







![未来网站策划呈现5大趋势 [网摘]](https://www.shuijiaxian.com/files_image/reation/bcimg27.png)
发表评论 取消回复