目录
负载均衡:
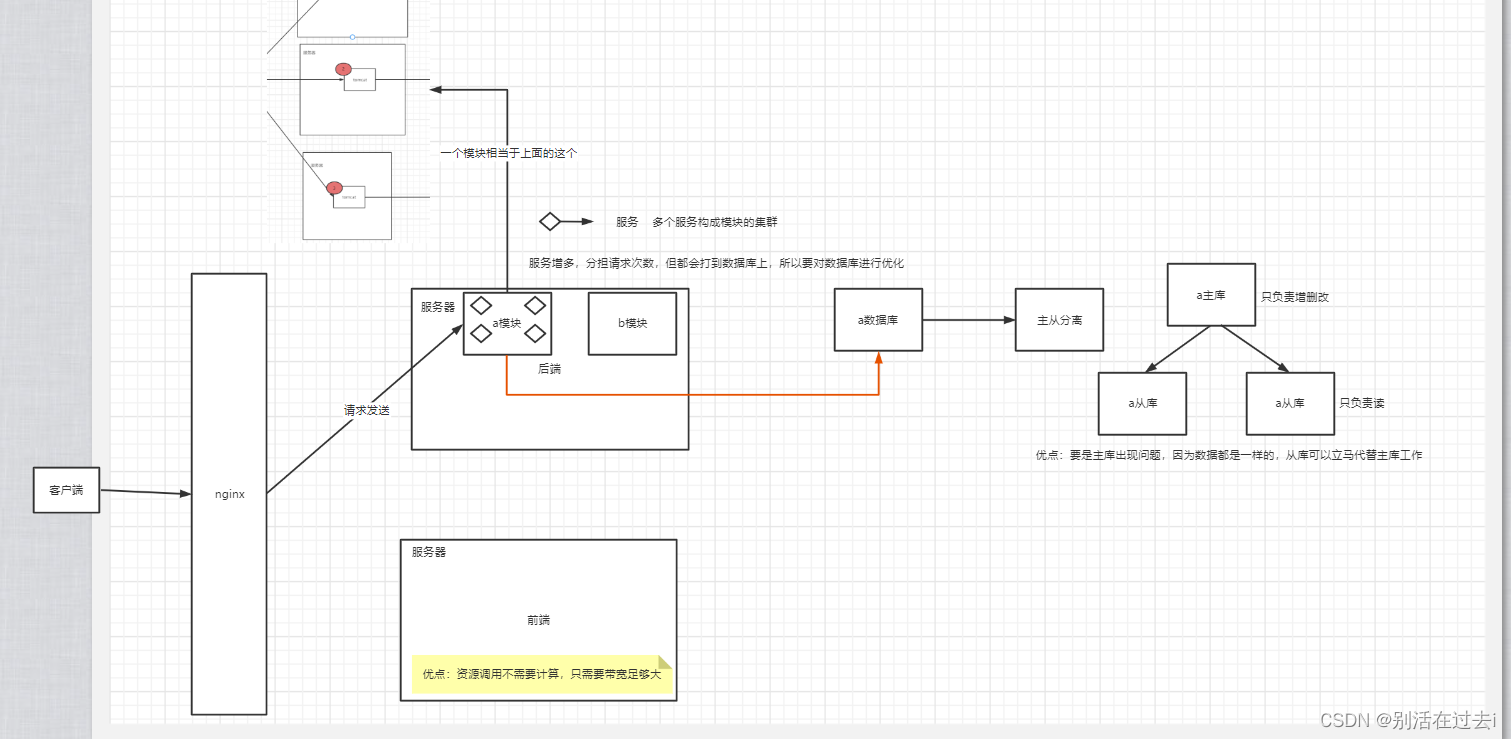
1,nginx来做负载均衡
如何实现负载均衡
nginx的负载均衡有4种模式:
负载均衡配置方法
数据库层面优化:
带来的问题:
2,选择同步器(自己程序)
(1) OGG
(2) Canal
(3) otter
(4) DataX
(5) kettle
(6) FlinkX
(7) Porter
负载均衡:
1,nginx来做负载均衡
如何实现负载均衡
在nginx里面配置一个upstream,然后把相关的服务器ip都配置进去。然后采用轮询的方案,然后在nginx里面的配置项里,proxy-pass指向这个upstream,这样就能实现负载均衡。
nginx的负载均衡有4种模式:
1)、轮询(默认)
每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。
2)、weight
指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况。
3)、ip_hash
每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题。
4)、fair , url_hash(第三方)
按后端服务器的响应时间来分配请求,响应时间短的优先分配。
负载均衡配置方法
打开nginx.conf文件,在http节点下添加upstream节点:
upstream webname { server 192.168.0.1:8080; server 192.168.0.2:8080; }
其中webname是自己取的名字,最后会通过这个名字在url里访问的,像上面这个例子一样什么都不加就是默认的轮询,第一个请求过来访问第一个server,第二个请求来访问第二个server。依次轮着来。
upstream webname { server 192.168.0.1:8080 weight 2; server 192.168.0.2:8080 weight 1; }
这个weight也很好理解,权重大的被访问的概率就大,上面这个例子的话,访问2次server1,访问一次server2
upstream webname { ip_hash; server 192.168.0.1:8080; server 192.168.0.2:8080; }
p_hash的配置也很简单,直接加一行就可以了,这样只要是同一个ip过来的都会到同一台server上
然后在server节点下进行配置:
location /name { proxy_pass http://webname/name/; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "upgrade"; }
proxy_pass里面用上面配的webname代替了原来的ip地址。
这样就基本完成了负载均衡的配置。
下面是主备的配置:
还是在upstream里面
upstream webname {
server 192.168.0.1:8080;
server 192.168.0.2:8080 backup;
}设置某一个节点为backup,那么一般情况下所有请求都访问server1,当server1挂掉或者忙的的时候才会访问server2
upstream webname {
server 192.168.0.1:8080;
server 192.168.0.2:8080 down;
} 设置某个节点为down,那么这个server不参与负载。
2,k8s+docker(运维团队)
3,zookeeper
前端资源主要是一些静态资源。
数据库层面优化:
1,并发(怎么满足一秒钟1000万)
2,数据量(表里有上亿的数据)
保证主库和从库之间数据同步
1,mysql支持,mysql内部有个配置,监听binlog(原理)
2,靠java程序来做,每次发生增删改,所有库都执行一遍。(都不会用,要是并发高,主从数据同步时间不一致导致出错)
3,依靠框架
带来的问题:
1,主库和从库之间同步是需要时间的(没有解决方法),强制读取主库数据(通过程序控制的)。
2,主库和缓存怎么保证数据一致性。:
1,双删策略(用的最多的)
1、在谈延时双删之前我们先来了解一下一般场景下数据库和redis的同步机制
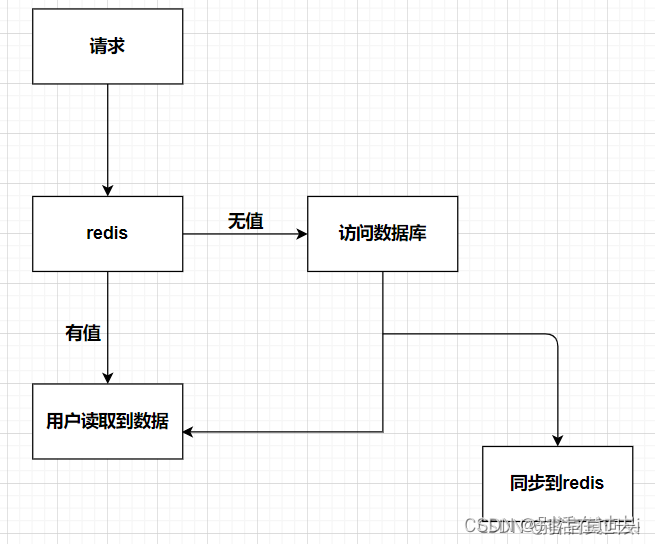
2、上面这种同步机制会有什么问题?
在我们访问redis时,redis中的数据可能不是热点数据,即此时数据库的更新操作已经完成,但是还没有同步到redis中。
3、解决方案,延时双删
延时双删方案执行步骤
- 删除redis
- 更新数据库
- 延时500毫秒
- 删除redis
问题一:为何要延时500毫秒?
这是为了我们在第二次删除redis之前能完成数据库的更新操作。
假象一下,如果没有第三步操作时,有很大概率,在两次删除redis操作执行完毕之后,数据库的数据还没有更新,此时若有请求访问数据,便会出现我们一开始提到的那个问题。
问题二: 为何要两次删除redis?
如果我们没有第二次删除操作,此时有请求访问数据,有可能是访问的之前未做修改的redis数据,删除操作执行后,redis为空,有请求进来时,便会去访问数据库,此时数据库中的数据已是更新后的数据,保证了数据的一致性。
2,选择同步器(自己程序)
(1) OGG
Oracle GoldenGate 是一款实时访问、基于日志变化捕捉数据,并且在异构平台之间迚行数据传输的产品。GoldenGate TDM是一种基于软件的数据复制方式,它从数据库的日志解析数据的变化(数据量只有日志的四分之一左右)。GoldenGate TDM将数据变化转化为自己的格式,直接通过TCP/IP网络传输,无需依赖于数据库自身的传递方式,而且可以通过高达10:1的压缩率对数据迚行压缩,可以大大降低带宽需求。在目标端,GoldenGate TDM可以通过交易重组,分批加载等技术手段大大加快数据投递的速度和效率,降低目标系统的资源占用,可以在亚秒级实现大量数据的复制,并且目标端数据库是活动的。
优点:牛逼
缺点:好像不开源;
(2) Canal
canal是由Alibaba开源的一个基于binlog的增量日志组件,其核心原理是canal伪装成Mysql的slave,发送dump协议获取binlog,解析并存储起来给客户端消费。
优点:可以同步任何非查询类操作。DDL和DML语句(除了数据查询语句select)。增量+全量都可以
缺点:数据源只支持MySQL,因为利用了MySQL的binlog特性
项目地址:https://github.com/alibaba/canal
(3) otter
otter是一款基于Java且免费、开源基于数据库增量日志解析,准实时同步到本机房或异地机房的mysql/oracle数据库的解决方案
优点:
- 单向同步, mysql –> oracle互相同步
- 双向同步,无冲突变更
- 文件同步,本地/aranda文件
- 双A同步,冲突检测&冲突补救
- 数据迁移,中间表/行记录同步
缺点:同canal,因其是利用canal来进行同步的,canal作为其数据源组件
项目地址:https://github.com/alibaba/otter
(4) DataX
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
优点:支持非常多数据库同步,原理是通过查询语句select同步的
缺点:不支持ddl同步
项目地址:https://github.com/alibaba/DataX
(5) kettle
Kettle是一款国外开源的ETL工具,用java编写,可以在视窗、Linux和Unix上运行,数据抽取高效稳定,中文称水壶。这个项目的主要程序员MATT想把各种数据放进一个水壶,然后以指定的格式流出。它是一个ETL工具集,允许你管理来自不同数据库的数据,并通过提供一个图形用户环境来描述你想做什么,而不是你想怎么做。Kettle中有两个脚本文件,转换和作业。转换完成了数据的基本转换,而作业完成了对整个工作流的控制。
优点:功能强大,支持几乎所有数据库;
缺点: 需要用户自己一步步配置,学习成本高;通过查询语句select同步的;
项目地址:https://github.com/pentaho/pentaho-kettle
(6) FlinkX
FlinkX是在是袋鼠云内部广泛使用的基于flink的分布式离线和实时的数据同步框架,实现了多种异构数据源之间高效的数据迁移。FlinkX是一个基于Flink的批流统一的数据同步工具,既可以采集静态的数据,比如MySQL,HDFS等,也可以采集实时变化的数据,比如MySQL binlog,Kafka等。
项目地址:https://github.com/DTStack/flinkx
缺点: 通过查询语句select同步的
(7) Porter
Porter是一款随行付开源的数据同步中间件,主要用于解决同构/异构数据库之间的表级别数据同步问题。
项目地址:https://github.com/sxfad/porter
3,监听binlog

最后
以上就是会撒娇汽车最近收集整理的关于负载均衡相关问题的全部内容,更多相关负载均衡相关问题内容请搜索靠谱客的其他文章。








发表评论 取消回复