参考链接:
tensorflow官方:对服装图像进行分类
tensorflow官方:图像分类
前言:网上的机器学习的例子大多数是数据量比较小的并且多是官方处理好的,这让小白体验通过自己本地的图片数据进行学习的过程就比较困难,本文主要是对参考链接2进行小的修改,让我们可以通过简单的修改就去训练我们本地的数据。
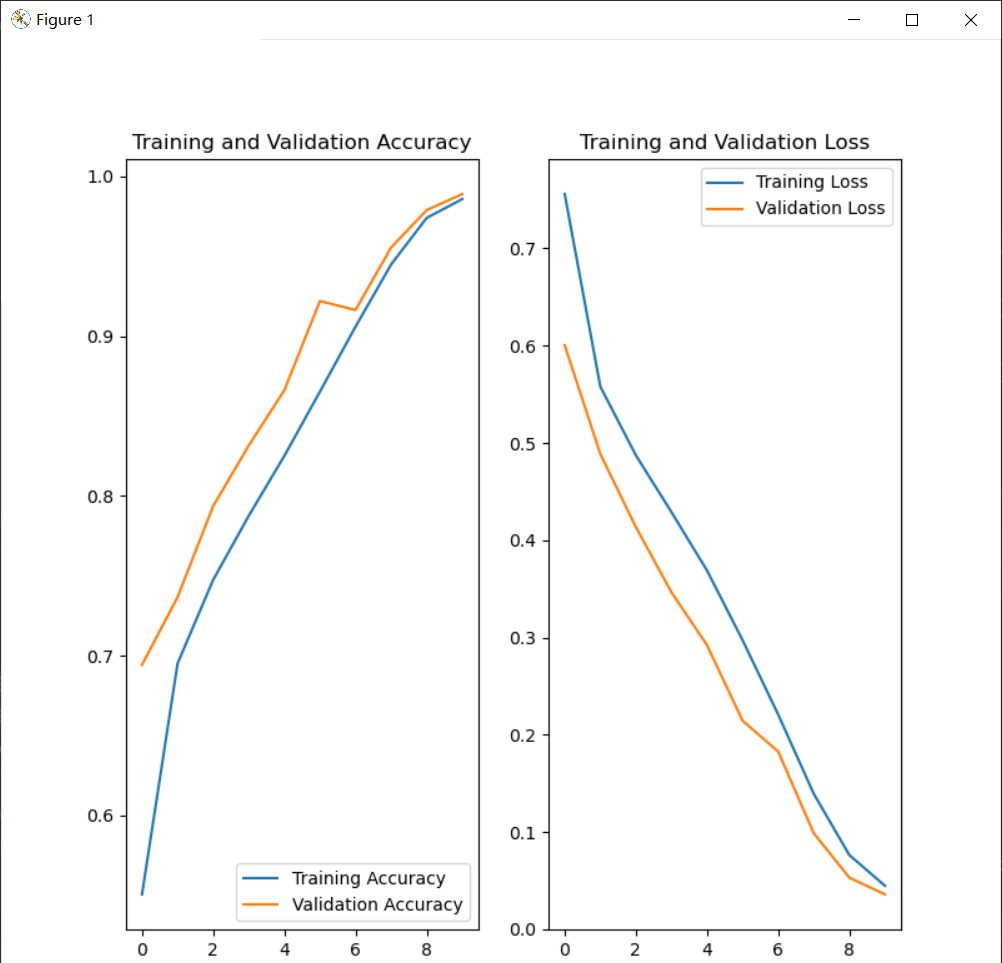
训练结果
猫狗大战Demo
- 整体流程
- 依赖包导入
- 设置目录路径
- 模型参数设置
- 建立图片数据通道
- 创建模型
- 编译模型
- 训练模型
- 可视化训练结果
- 遇到的问题
- 显卡内存不足
- 代码的复用
整体流程
依赖包导入
# 导入包
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Conv2D, Flatten, Dropout, MaxPooling2D
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import os
import numpy as np
import matplotlib.pyplot as plt
设置目录路径
这里主要是设置一下机器学习的文件(本文主要是图片)的路径,然后统计一下数量
# 设置目录路径
PATH = os.path.join('F:/datasets/catdog') # 图片数据集的根目录
# 将目录区分位猫狗训练集和验证集
train_dir = os.path.join(PATH, 'train') # train数据集 相对于根目录
validation_dir = os.path.join(PATH, 'validation') # validation数据集 相对于根目录
train_cats_dir = os.path.join(train_dir, 'cats') # train目录下的文件夹 每个会在之后分为一类
train_dogs_dir = os.path.join(train_dir, 'dogs')
validation_cats_dir = os.path.join(validation_dir, 'cats') # validation目录下的文件夹 每个会在之后分为一类
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
num_cats_tr = len(os.listdir(train_cats_dir))
num_dogs_tr = len(os.listdir(train_dogs_dir))
num_cats_val = len(os.listdir(validation_cats_dir))
num_dogs_val = len(os.listdir(validation_dogs_dir))
total_train = num_cats_tr + num_dogs_tr # 文件数量求和 方便 后续处理和代码复用
total_val = num_cats_val + num_dogs_val
模型参数设置
我们将一些总是需要修改的参数提出来,设置成变量,这样可以方便我们后期修改和代码复用
# 为方便起见,设置变量以在预处理数据集和训练网络时使用
batch_size = 64
epochs = 10
IMG_HEIGHT = 200
IMG_WIDTH = 200
建立图片数据通道
这里大概有两个东西一个是数据增强,另一个是通道。
数据增强:emmm
通道:这是为了解决在深度学习中训练数据过多无法一次加载到内存的问题,通道可以进行动态的加载,并且通道的建立对文件夹目录有一定要求,比如我们为train文件夹建立一个通道,那么它会自动的按照文件夹进行分类,这也是为什么在进行fit时我们只传了一个参数,而不是x,y两个参数
# 使用实时数据增强生成一批张量图像数据。 通过通道方式获取图片
train_image_generator = ImageDataGenerator(rescale=1./255)
validation_image_generator = ImageDataGenerator(rescale=1./255)
train_data_gen = train_image_generator.flow_from_directory(
batch_size=batch_size, directory=train_dir, shuffle=True,
target_size=(IMG_HEIGHT, IMG_WIDTH), class_mode='binary')
val_data_gen = validation_image_generator.flow_from_directory(
batch_size=batch_size, directory=validation_dir,
target_size=(IMG_HEIGHT, IMG_WIDTH), class_mode='binary')
创建模型
这里还需要补课的…
不过对于一个小白来说,个人觉得先能弄起来才是最重要的(原理什么的后期在补),看不见结果是会让人失去动力的
# 创建模型
model = Sequential([
Conv2D(16, 3, padding='same', activation='relu', input_shape=(IMG_HEIGHT, IMG_WIDTH, 3)),
MaxPooling2D(),
Conv2D(32, 3, padding='same', activation='relu'),
MaxPooling2D(),
Conv2D(64, 3, padding='same', activation='relu'),
MaxPooling2D(),
Flatten(),
Dense(512, activation='relu'),
Dense(1)
])
编译模型
# 编译模型
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
# 输出模型信息
model.summary()
训练模型
这里的参数都是动态设置的基本上是不需要改变的。
另外就是:fit已经支持generator了fit_generator要废弃了
# 训练模型
history = model.fit(
train_data_gen,
steps_per_epoch=total_train // batch_size,
epochs=epochs,
validation_data=val_data_gen,
validation_steps=total_val // batch_size,
)
# 保存训练结果
model.save('day_model5.h5')
可视化训练结果
# 可视化培训结果
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
遇到的问题
显卡内存不足
这个问题吧,我百度之后最大的感触就是:换显卡、换电脑…
比较有效的方法就是降低下面的三项数值
batch_size = 64
IMG_HEIGHT = 200
IMG_WIDTH = 200
百度上面的方法:https://blog.csdn.net/liulina603/article/details/80180355 等
自我感觉在硬件不行的设备上作用不大
代码的复用
这个代码其实在图像分类上还是可以复用的,主要的思路就是修改目录路径、模型参数设置。
最后
以上就是眯眯眼宝马最近收集整理的关于tensorflow2 小白的猫狗大战实现整体流程遇到的问题代码的复用的全部内容,更多相关tensorflow2内容请搜索靠谱客的其他文章。








发表评论 取消回复