以下是关于我个人对libfacedetection(人脸检测-pytorch)的所有见解,如有错误欢迎大家在评论区指出,我将会第一时间纠正。据说,人脸检测速度可以达到1000FPS,到底结果如何,我们来一探究竟。
libfacedetection
github链接: https://github.com/ShiqiYu/libfacedetection
github(train)链接: https://github.com/ShiqiYu/libfacedetection.train
这里我们下载train的就行
训练数据集下载
链接: http://shuoyang1213.me/WIDERFACE/
这里我们还需要下载一个evaluation tools的工具,在github(train)里面有,大家可以打开里面进行下载。
数据集存放位置
$ tree data/widerface
data/widerface
├── wider_face_split
├── WIDER_test
├── WIDER_train
├── WIDER_val
└── trainset.j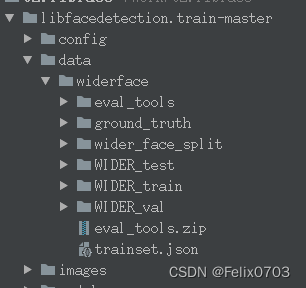
环境搭建
1、首先我们在docker里面创建一个环境
conda create -n 03.libface-pytorch-1.7-python-3.8 -y python=3.8
-n 后面写的是创建的这个环境的名字,根据个人习惯而定,-y 后面写的则是该环境需要安装的python版本是多少。
2、查看创建好的环境
conda env list
3、进入环境
conda activate 03.libface-pytorch-1.7-python-3.8
4、根据自己所需版本安装对应的pytorch版本
pip install torch==1.7.0+cu110 torchvision==0.8.1+cu110 -f https://download.pytorch.org/whl/torch_stable.html
5、现在我们要根据github里面的requirements进行安装
pip install -r requirements.txt
重点(本人亲踩坑):这里很多小伙伴可能安装不了nvidia-dlia这个库,这里提供安装命令。
Install via pip for CUDA 10.2:
pip install --extra-index-url https://developer.download.nvidia.com/compute/redist/ nvidia-dali-cuda102==1.6.0
pip install --extra-index-url https://developer.download.nvidia.com/compute/redist/ nvidia-dali-tf-plugin-cuda102==1.6.0
or for CUDA 11:
pip install --extra-index-url https://developer.download.nvidia.com/compute/redist/ nvidia-dali-cuda110==1.6.0
pip install --extra-index-url https://developer.download.nvidia.com/compute/redist/ nvidia-dali-tf-plugin-cuda110==1.6.0
6、最重要的一点来了,我们在训练前,一定要先创建NMS MODEL,要不然各种报错,命令如下:
cd tools/widerface_eval
python setup.py build_ext --inplace
在这里环境的搭建也就结束了,过程有几个坑,希望为给的命令能帮助到大家。
模型训练
我们根据训练脚本里面所需要给的参数进行填写,一般只需要填写–config就行。
如果训练途中中断了,在重新训练前加入–resume 接着训即可。
--resume ./weights/last.pth
parser = argparse.ArgumentParser(description='Yunet Training')
parser.add_argument('--config', '-c', default='./config/yufacedet.yaml', type=str, help='config to train')
parser.add_argument('--tag', '-t', default=None, type=str, help='tag to mark train process')
parser.add_argument('--resume', type=int, default=0, help='resume epoch to start')
参数填写后,执行train.py:
python train.py -c ./config/yufacedet.yaml
看到如下图所示,训练成功!

模型保存位置:
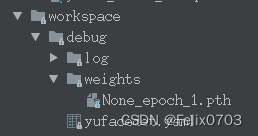
如果我们想改变模型存放位置,在配置文件中改变train下面的workspace参数即可。
模型测试
现在我们用训练好的模型进行图片测试和视频测试。
python detect.py -c ./config/myfacedet.yaml -m weights/final.pth --target ./image/filename.jpg
python detect.py -c ./config/yufacedet.yaml -m weights/yunet_final.pth --target ./video/111.mp4

本章节在这里就告一段落,接下来的第二章,我会分享Yunet网络的个人看法,感谢阅读,如果觉得还可以的话给博主一个赞就是对博主最大的支持~
最后
以上就是眯眯眼宝马最近收集整理的关于人脸检测:史上最详细人脸检测libfacedetection讲解-模型训练--第一节本章节在这里就告一段落,接下来的第二章,我会分享Yunet网络的个人看法,感谢阅读,如果觉得还可以的话给博主一个赞就是对博主最大的支持~的全部内容,更多相关人脸检测:史上最详细人脸检测libfacedetection讲解-模型训练--第一节本章节在这里就告一段落,接下来内容请搜索靠谱客的其他文章。








发表评论 取消回复