关注公众号,发现CV技术之美
0
写在前面
Transformer是一个强大的文本理解模型。然而,由于其对输入序列长度呈二次计算复杂度,Transformer是效率是比较低下的。虽然Transformer加速有很多方法,但在长序列上要么效率低下,要么不够有效。
本文提出了一种基于加性注意的Fastformer模型。在Fastformer中,作者首先使用加性注意机制来建模全局上下文,然后根据每个token表示与全局上下文表示的交互作用,进一步转换token的表示。
这样,Fastformer可以实现具有线性复杂度的上下文建模的方式。在5个数据集上进行的大量实验表明,Fastformer比许多现有的Transformer模型要高效得多,同时可以实现类似甚至更好的长文本建模性能。
1
论文和代码地址

Fastformer: Additive Attention Can Be All You Need
论文:https://arxiv.org/abs/2108.09084
代码:https://github.com/wuch15/Fastformer
2
Motivation
Transformer及其变体在许多领域都取得了巨大的成功。例如,Transformer是NLP中许多SOTA的预训练语言模型的主干网络,如BERT和GPT。Transformer在CV任务中也展现了非常好的性能,如:ViT。Transformer模型的核心是自注意机制,它允许Transformer对输入序列中的上下文进行建模。
然而,由于自注意计算每对位置的输入表示之间的点积,它的复杂度与输入序列长度是二次相关的。因此,标准的Transformer模型很难有效地处理长输入序列。
在本文中,作者提出了Fastformer,这是一种基于加性注意的Transformer,可以在线性复杂度下实现有效的上下文建模。在Fastformer中,作者首先使用加性注意机制将输入query矩阵总结为一个全局query向量。
接下来,通过元素级乘积对key与全局query向量之间的交互作用进行建模,以学习全局上下文key矩阵,并通过加性注意将其进一步总结为全局key向量。
然后利用元素级乘积对全局key向量和value矩阵进行聚合,通过线性变换进一步处理,计算全局上下文感知的value。
最后,将原始query和全局上下文感知value相加,形成最终输出。作者在五个数据集上证明了Fastformer的有效性。结果表明,Fastformer比许多Transformer模型要有效得多,并且在长文本建模中可以取得相当有竞争力的结果。
3
方法
3.1 Self-Attention
Transformer模型建立在Multi-head Self-Attention的基础上,通过捕获每对位置的输入之间的交互作用,有效地建模序列内的上下文。一个有h个head的Self-Attention机制可以表示如下:
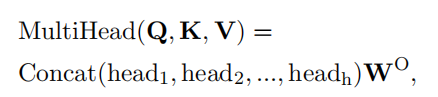
每个注意力head学习到的表征表述如下:
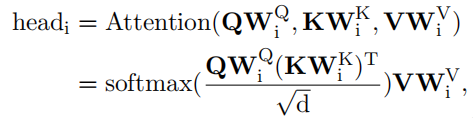
从这个公式可以看出,Self-Attention的计算复杂度与序列长度N呈二次关系。它成为了Transformer处理长序列的瓶颈。
3.2 Architecture
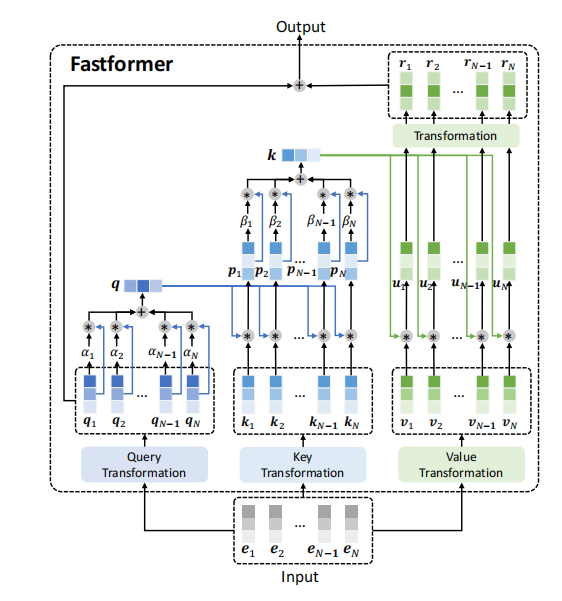
Fastformer结构如上图所示,Fastformer首先将输入的嵌入矩阵转换为query、key和value序列。输入矩阵记为 ,其中N为序列长度,d为通道维数,可以记为一系列向量的组合 。
与Transformer一样,Fastformer首先用三个参数不共享的线性层将输入矩阵转换为query、key和value矩阵
,也可以记为一系列向量的组合。
接下来,基于query、key和value之间的交互作用对输入序列的上下文信息进行建模是类Transformer架构的一个关键问题。在普通Transformer中,使用点积注意机制对query与key之间的交互进行充分建模。
然而,Transformer的二次复杂度使其在长序列建模中效率低下。降低计算复杂度的一种潜在方法是在建模注意矩阵的交互作用之前,对输入矩阵(query、key和value)进行特征的总结。加性注意是一种注意机制的形式,它可以在线性复杂度下有效地总结序列中的重要信息。
因此,作者首先使用加性注意将query矩阵汇总为一个全局query向量 ,它将query的全局上下文信息进行压缩。更具体地说,第i个query向量的注意权值 计算如下:
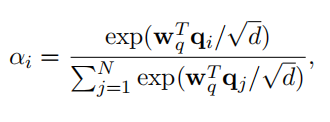
其中
是一个可学习的参数向量。
全局query向量的计算方法如下:
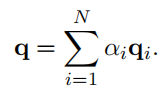
然后,Fastformer的一个核心问题是如何建模全局query向量与key矩阵之间的交互作用。有几个直观的选择,例如将全局query向量add或concat到key矩阵中的每个向量中。但是,这些方法不能区分全局query对不同key的影响,这对上下文理解是没有好处的。元素乘积是模拟两个向量之间非线性关系的有效方法。
因此,在本文中,作者使用全局query向量和每个key向量之间的元素级乘积来建模它们的交互,并将它们组合成一个全局上下文感知的key矩阵。我们将这个矩阵中的第i个向量表示为
,它被表示为
(∗是指元素级乘积)。同样地,作者也使用了加性注意来总结具有全局上下文感知的key矩阵。其第i个向量的加性注意权重计算如下:
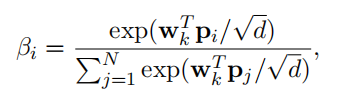
其中,
为注意参数向量。全局key向量
的进一步计算如下:
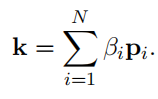
最后,作者对value矩阵与全局key向量之间的交互作用进行了建模,以实现更好的上下文建模。与query-key交互建模类似,作者在全局key和每个value向量之间执行元素乘积,计算key-value交互向量 ,表示为 。
与Transformer相似,作者对每个key-value交互向量应用一个线性变换层来学习其隐藏表示。该层的输出矩阵表示为
。将该矩阵与query矩阵进一步相加,形成Fastformer的最终输出。
综上所述,在Fastformer中,每个key和value向量都可以与全局query和key向量交互来学习上下文表示。通过堆叠多个Fastformer层,可以完全建模上下文信息。在具体实现上,作者共享了value和query的转换矩阵来减少额外的开销。此外,作者在不同的Fastformer层之间共享参数,以进一步减少参数量,减少过拟合的风险。
3.3 Complexity Analysis
对于学习全局query和key向量的加性注意网络,其时间和内存成本均为 ,其参数量为 (h为注意头数)。此外,元素级乘积的时间成本和内存成本也为 ,比Transformer的 的复杂度要高效的多。如果参数共享,每层Fastformer的总参数为 ,而Transformer至少需要 的参数量,因此Fastformer的参数量也更少。
4
实验
4.1 Datasets
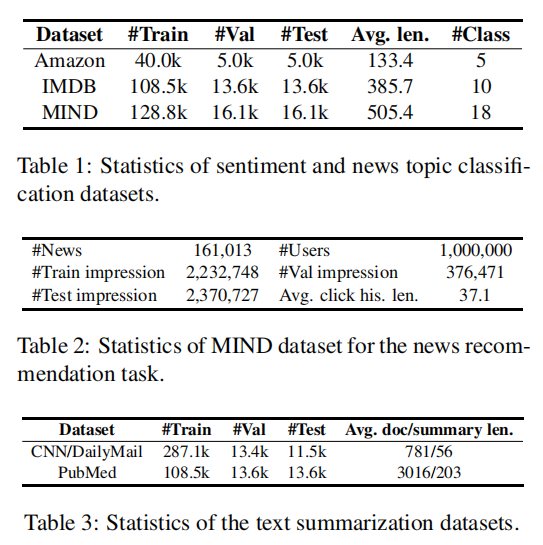
为了证明本文方法在多个任务上都是有用的,作者在5个数据集上进行了实验,数据集的细节如上表所示。
4.2 Effectiveness Comparison
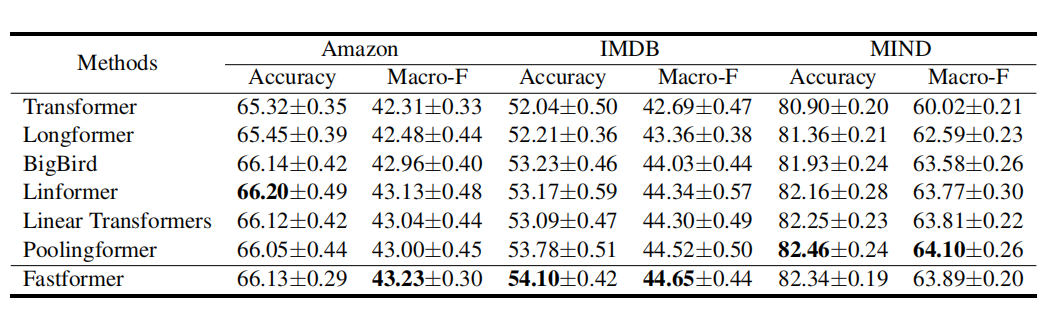
上表比较了Fastformer和一些针对Transformer改进方法在三个分类数据集上的性能。根据结果,我们发现高效的Transformer变体通常优于标准的Transformer模型。在长文本和短文本建模中,Fastformer可以实现比其他高效Transformer变体具有竞争力或更好的性能。
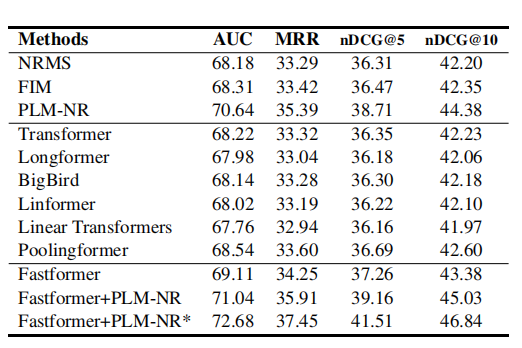
上表比较了不同方法在新闻推荐任务中的性能。我们可以看到,在不同的Transformer架构中,Fastformer取得了最好的性能。
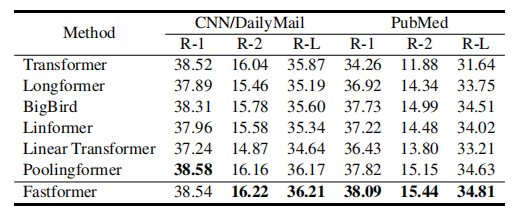
上表展示了 自然语言生成任务上不同方法的性能,Fastformer在大多数指标中都能达到最好的性能,这显示了Fastformer在自然语言生成中的优势。
4.3 Efficiency Comparison
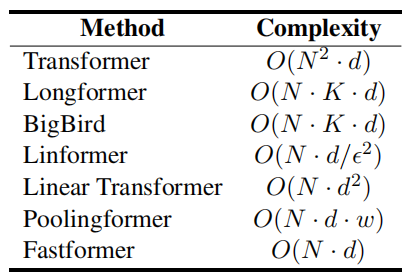
上表比较了不同方法的理论计算复杂度。可以看出,Fastformer实现了最低的理论计算复杂度。
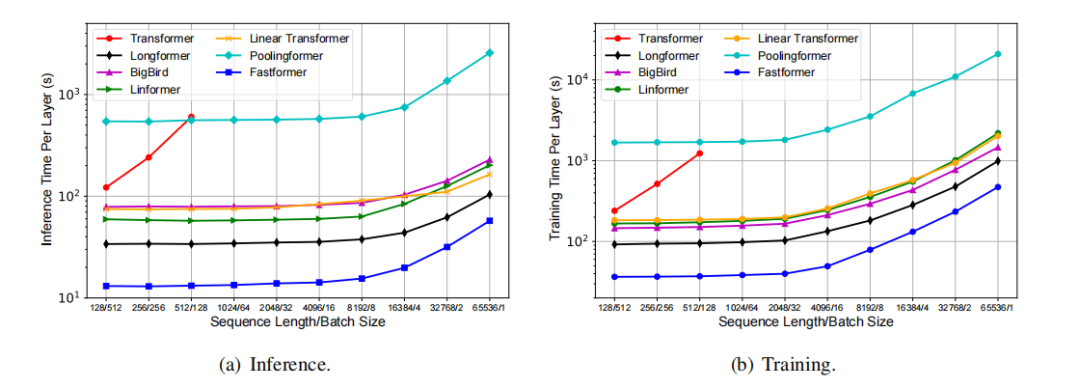
从上图中,我们可以看到当序列长度相对较长时,Transformer效率低下。在训练和推理时间方面,Fastformer比其他线性复杂度Transformer效率要高得多。
4.4 Influence of Interaction Function
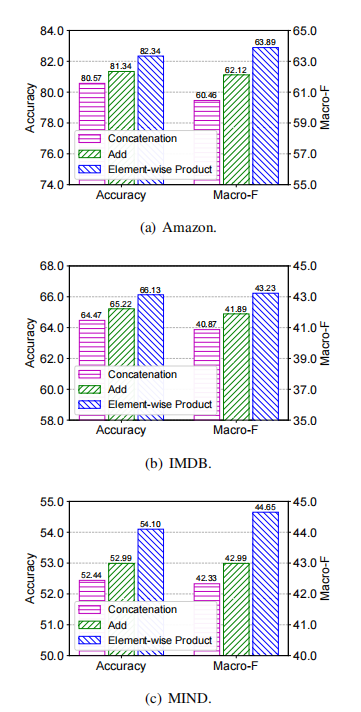
上表比较使用不同函数建模query、key和value之间交互的影响。可以看出,元素级乘积是相对来说最好的一种交互方式。
4.5 Influence of Parameter Sharing
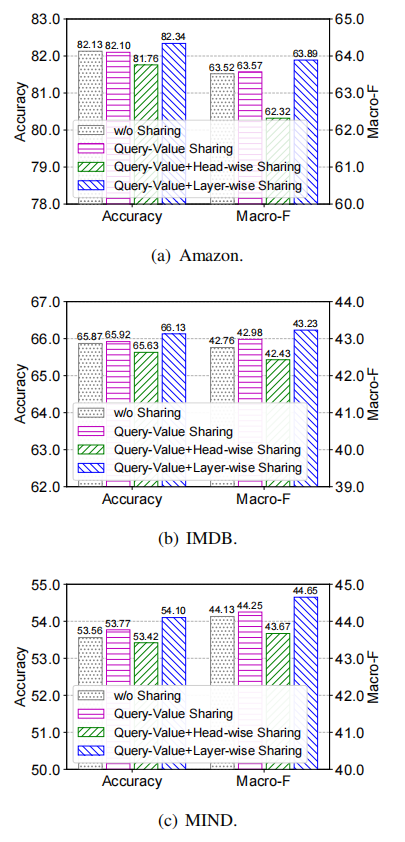
上图展示了参数共享对模型性能的影响,结果表明,参数共享能够进一步提升性能。
5
总结
本文提出了Fastformer,它是一种基于加性注意的Transformer变体,可以在线性复杂度下有效地处理长序列。在Fastformer中,首先使用加性注意将query矩阵总结为一个全局query向量。接下来,通过元素级乘积将其与每个key向量相结合,学习全局上下文感知key矩阵,并通过加性注意将其进一步总结为一个全局key向量。
然后,将全局上下文感知的key与value之间的交互进行建模,以学习全局上下文感知的value,并将其进一步与query结合,形成最终输出。在5个基准数据集上进行的大量实验表明,Fastformer比许多现有的Transformer模型更高效,同时可以在长文本建模中实现具有了竞争力甚至更好的性能。
▊ 作者简介
研究领域:FightingCV公众号运营者,研究方向为多模态内容理解,专注于解决视觉模态和语言模态相结合的任务,促进Vision-Language模型的实地应用。
知乎/公众号:FightingCV

END
欢迎加入「Transformer」交流群????备注:TFM

最后
以上就是谦让身影最近收集整理的关于Fastformer:简单又好用的Transformer变体!清华&MSRA开源线性复杂度的Fastformer!的全部内容,更多相关Fastformer:简单又好用内容请搜索靠谱客的其他文章。







![[李宏毅老师深度学习视频] 自注意力机制 self-attention【手写笔记】](https://www.shuijiaxian.com/files_image/reation/bcimg22.png)
发表评论 取消回复