该系列主要是听李宏毅老师的《深度强化学习》过程中记下的一些听课心得,除了李宏毅老师的强化学习课程之外,为保证内容的完整性,我还参考了一些其他的课程,包括周博磊老师的《强化学习纲要》、李科浇老师的《百度强化学习》以及多个强化学习的经典资料作为补充。
使用说明
笔记【4】到笔记【11】为李宏毅《深度强化学习》的部分;
笔记 【1】和笔记 【2】根据《强化学习纲要》整理而来;
笔记 【3】 和笔记 【12】根据《百度强化学习》 整理而来。
Q-learning是基于价值的强化学习方法,我们要学习的不是策略而是评论家critic,critic用来评价这个行为的好坏程度。至于怎么评价,比如使用状态价值函数Vπ(s)或者状态动作价值函数Q(s,a)等。
今天我们重点来看Q-learning里面的评论家怎么构造。
一、State Value Function状态价值函数
State Value Function状态价值函数是其中一种评论家。
(1)基于MC
那么怎么去求这个状态价值函数V π (s)呢?可以利用基于MC和基于TD这两种方法。
如果按照传统思路,直接让演员去跟环境互动,然后给评论家看,评论家统计之后会评价演员的表现如何——看到状态Sa,接下来的累计奖励会是多少,看到状态Sb,接下来的累计奖励会是多少…但是如果用Q-table的形式直接统计,把所有可能的情况全部统计几乎是不可能的,比如星球大战游戏当中,要把每一帧图像统统扫过,这个数据体量相当大,很难实现。所以,实际上要用一个网络来拟合V π (s),也就是说,V π (s)这个函数,其实是一个网络,该网络的功能就是做一个评论家。——这样就引入了深度学习的内容,将单纯的强化学习与深度学习结合了起来。
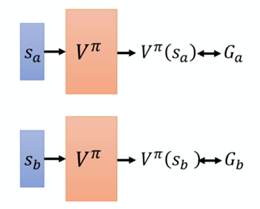
那这个网络怎么训练?就是一个回归问题,让网络输出的Ga尽量与真实值靠近,输出的Ga尽量与真实值靠近。跟深度学习CNN等的训练方法相同,这里不再多说。
(2)基于TD
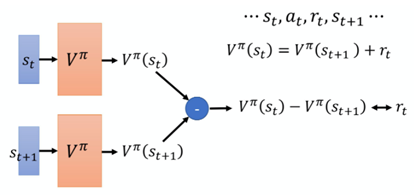
基于TD的网络训练时主要依据:
![]()
也就是说,给网络输入St,输出V(St),再网络输入St+1,输出V(St+1),两者应该满足上述等式,换句话说,两者的差应该等于rt。所以,该网络训练的目标就是通过优化V函数的参数,让输出的这两者的差值尽量逼近真正的rt。
今天其实 TD 的方法是比较常见的,MC 的方法其实是比较少用的。
二、state-action value function(状态-动作价值函数)/ Q-function
这是另一种评论家,同样的,如果要求Q-function,可以采用传统的Q-table方式,也可以引入深度学习网络。显然,传统Q-table容易引发维度灾难,我们重点关注深度学习网络拟合Q-function的方式。
首先,在连续的状态与动作空间中,如果使用原始的Q函数容易产生维度灾难,但是值函数近似利用函数直接拟合状态值函数或状态动作值函数,减少了对存储空间的要求,有效地解决了这个问题。因此,用价值函数近似(Value Function Approximation)来代替原始的Q函数:
![]()
其中,函数 Qϕ(s,a) 通常是一个参数为ϕ的函数,比如神经网络,输出为一个实数,称为Q 网络(Q-network)。
要训练这个网络,跟一、State Value Function状态价值函数相同,可以基于MC或者基于TD,最终训练出来Q-function,这个就不再详细说了,但是训练过程中的一些重要细节需要详细说明:
(1)目标网络(target network)
![]()
根据上式可知,在训练过程中,如果采用上式作为依据,那么等式左右两侧都有Q,两侧的值都是动态变化的。什么意思呢?也就是说,猫抓老鼠,但是猫和老鼠都是时刻在动的,所以优化轨迹会十分杂乱,这会导致训练过程很不稳定。但是如果我们让老鼠每5步才移动一次,而猫一直移动,这样猫就有足够时间去靠近老鼠,这样它们之间的距离就会随着优化过程越来越小,训练过程就会比较稳定,最终能够拟合出一个比较好的Q-function。
所以,我们人为将上式右边的部分固定,作为target network,通过改变左侧部分的参数来进行优化,这样就变成了回归问题。
(2)探索(Exploration)
为了避免探索-利用窘境(Exploration-Exploitation dilemma),可以有两个方法:
①Epsilon Greedy。Epsilon Greedy(ε-greedy) 的意思是说,我们有1−ε的概率会按照 Q-function 来决定动作,通常ε就设一个很小的值,1−ε可能是90%,也就是90%的概率会按照 Q-function 来决定动作,但是你有 10% 的机率是随机的。通常在实现ε会随着时间递减。在最开始的时候。因为还不知道那个动作是比较好的,所以你会花比较大的力气在做探索。接下来随着训练的次数越来越多。已经比较确定说哪一个 Q 是比较好的。你就会减少你的探索,你会把ε的值变小,主要根据 Q-function 来决定你的动作,比较少随机决定动作,这是 Epsilon Greedy。
②Boltzmann Exploration,这个方法就比较像是策略梯度。在策略梯度里面,网络的输出是一个期望的动作空间上面的一个的概率分布,再根据概率分布去做采样。那其实你也可以根据 Q 值去定一个概率分布,假设某一个动作的 Q 值越大,代表它越好,我们采取这个动作的机率就越高。但是某一个动作的 Q 值小,不代表我们不能尝试。
(3)Experience Replay(经验回放)
就是说,在实际训练过程中,会构建一个Replay Buffer(Replay Memory),用来保存许多data,每一个data的形式如下:在某一个 state,采取某一个action,得到reward,然后跳到 st+1。我们使用π去跟环境互动很多次,把收集到的数据都放到这个 replay buffer 中。当我们的buffer“装满”后,就会自动删去最早进入buffer的data。在训练时,对于每一轮迭代都有相对应的batch(与我们训练普通的Network一样通过sample得到),然后用这个batch中的data去update我们的Q-function。综上,Q-function再sample和训练的时候,会用到过去的经验数据,所以这里称这个方法为Experience Replay,其也是DQN中比较重要的tip。
要注意的是, replay buffer 里面的经验可能是来自于不同的策略。你每次拿π去跟环境互动的时候,你可能只互动 10000 次,然后接下来就更新你的π了。但是这个 buffer 里面可能可以放5万笔资料,所以5万笔资料可能是来自于不同的策略。Buffer只有在它装满的时候,才会把旧的资料丢掉。所以这个buffer 里面它其实装了很多不同的策略的经验。
三、DQN
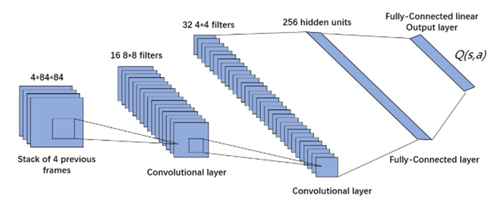
图1.DQN使用深度卷积神经网络近似拟合状态动作值函数 Q(s,a)
DQN其实就是用深度学习结合了Q-learning,之前的Q-learning方法是使用传统的Q-table的方式来构造评论家,但是这种方式数据量大且不适用于连续的状态动作,因此DQN利用深度学习网络的方法来构造评论家,该网络相当于评价函数。此外,DQN还采用了经验回放的训练方法,Q-learning是直接利用下一个状态的数据进行学习。
最后
以上就是甜甜心情最近收集整理的关于强化学习笔记【6】DQN基本概念的全部内容,更多相关强化学习笔记【6】DQN基本概念内容请搜索靠谱客的其他文章。








发表评论 取消回复