感觉这一讲的内容大多都在复习之前我在RL里学过的内容,而且我发现,相比于David Silver 的强化学习内容,这个伯克利的DRL课程顺序刚好相反。RL是由表格型开始,讲了V(s) 和 Q(s, a),之后再讲的Function approximator,而DRL是先Policy Gradient 然后才提到Q Function。
虽然内容都差不多,但是我还没明白不同的顺序是否侧重点不同,而两者的侧重点又分别是什么。感觉自己对于强化学习的脉络还是没有很好的理清楚。希望之后慢慢会有更深刻的理解吧。
还有,最近跑了一下DQN的代码(基于Pytorch),我却觉得它的学习并不高效。而Actor Critic的方法就像老师说的那样,很大可能不收敛。我跑了几个程序,包括MountainCar、Cartpole 的DQN算法、AC算法,有些学着学着就不动弹了,尤其是MountainCar,还不是很清楚……
其实学了这么久,还是感觉毫无进展……真的有点难啊
概括
这一讲主要是在讲Value Based 方法,就是使用 Q Function 和 V Function。
前面的章节一直在讲policy based方法,就是根据既定的或者是随机的策略,不断优化策略,而这一讲讲述了不根据策略,而是根据Value Function的值来产生策略,这个策略可以是基于Value贪心的:
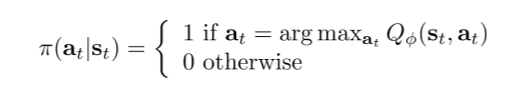
也可以是 Epsilon greedy 的(利用 ε):
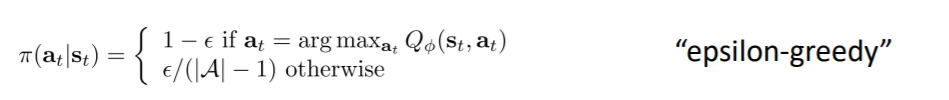
还有一种叫做Boltzmann Exploration:

从policy gradient 过渡到了 policy iteration,其中穿插了Dynamic Programming,Fitted Value Iteration, 最终到了 Fitted Q Iteration,这个Fitted Q Iteration 不需要知道状态转移概率(transition probabilities)。
break前总结,Value-Based Methods 就是,不需要去得到一个确切的策略,只需要获得Value Function:If we have Value Function, we have a policy.
从 Fitted Value Iteration 到 Fitted Q Iteration
先看看Fitted Value Iteration,是这样的:

但是第一步需要知道状态间的转移概率:也就是说需要知道采取了某个action之后下一个状态的概率
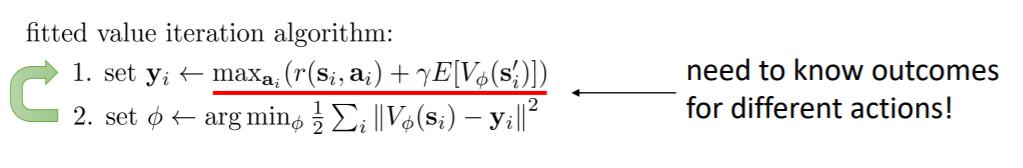
这样的话,如果我们不知道环境的模型,model-free 情况下,就不是很适合了,所以就需要使用Q():

直接让下一状态的 Value期望值 等于最大的 Q 值,这样就不需要去模拟不同action产生的value,因为实际情况中我们不太可能一个状态下使用多个action来看看不同的结果,更可能的情况是某一个state可能只经历一次。所以使用Q就更加有优势了。

众所周知 fitted Q-iteration 是离轨的
为什么呢?感觉这个问题我已经听不同的老师讲过一遍了,这个问题是每个老师都会提及的。
因为使用Q Function中,不同状态采取不同action得到的下一个状态这之间的transition都是与当前的 policy Π 独立的:
个人感觉这没有说的很清楚,于是又看了别人的理解,
- 书上的解释:In this case, the learned action-value function, Q, directly approximates q*, the optimal action-value function, independent of the policy being followed.
- 理解:在式子中用于更新的
arg
m
a
x
Q
(
S
′
,
a
′
)
arg~max~Q(S',a')
arg max Q(S′,a′),下一步真正执行的动作却不一定是
arg
m
a
x
Q
(
S
′
,
a
′
)
arg~max~Q(S',a')
arg max Q(S′,a′)里面的
a
′
a'
a′,所以说是离轨。
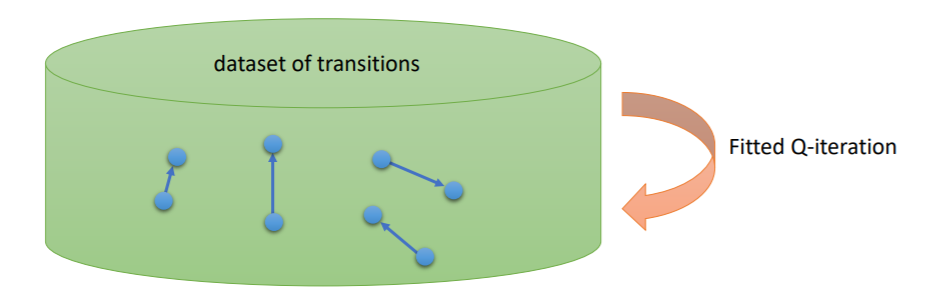
我们之前在RL里面学习的 Q Learning 其实就是下面的这个 online Q Learning: (由 Watkins提出)
它们之间的区别就在于online Q 没有小的K次循环,每一次只采取一个动作a,得到一个transition(si, ai, si’, ri),然后利用这一个transition去得到目标值(yi),然后用这个目标值和预测值去计算梯度(step 3)。在这里K=1, S=1, N=1。
也就是说,online Q Learning 其实就是fitted 的一种特殊情况。

那么,fitted Q-iteration 在优化什么呢?

在表格的情况下,我们通过迭代能够得到最优的策略,当error ε == 0 的时候,就得到了最优的Q function,因为所有的值已经达到了最大,已经没有误差了,而这时的策略就是最优策略了。
而就像我在概括里提到的三种方法,上面一直用的是greedy,就是不管什么时候只选择最大值,但这样是有弊端的——会导致发现不了新的情况,而这些新的情况可能是非常好的。所以使用ε-greedy 或者 Boltzmann Exploreation 会更好。
Q Learning的问题(以下是下一讲的内容)
online Q learning 和 fitted Q Iteration 的问题有两个:
-
样本之间是相关的。因为连续的states是互相关联的,采集样本也是按照顺序采集的。
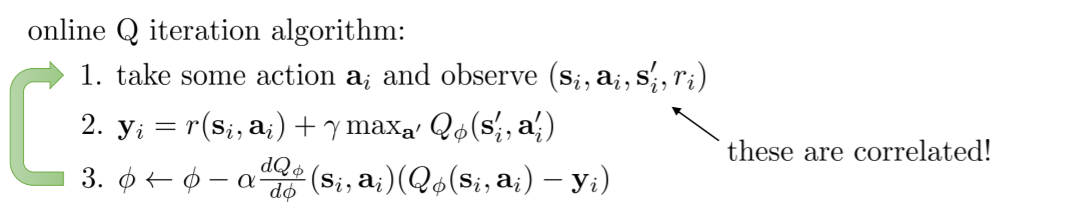
-
Q Learning 里使用的并不是gradient descent,也就是下图的部分并没有使用梯度下降。

1. replay buffer
对于第一个问题,我们可以采用一个replay buffer 来加以改善:也就是说,相比于之前亲自采集样本,(采取一个action然后得到transition),我们使用一个buffer B,每次从B中采样一个batch,然后用这个batch中的数据进行学习,不断优化参数Φ。需要periodically feed the buffer。
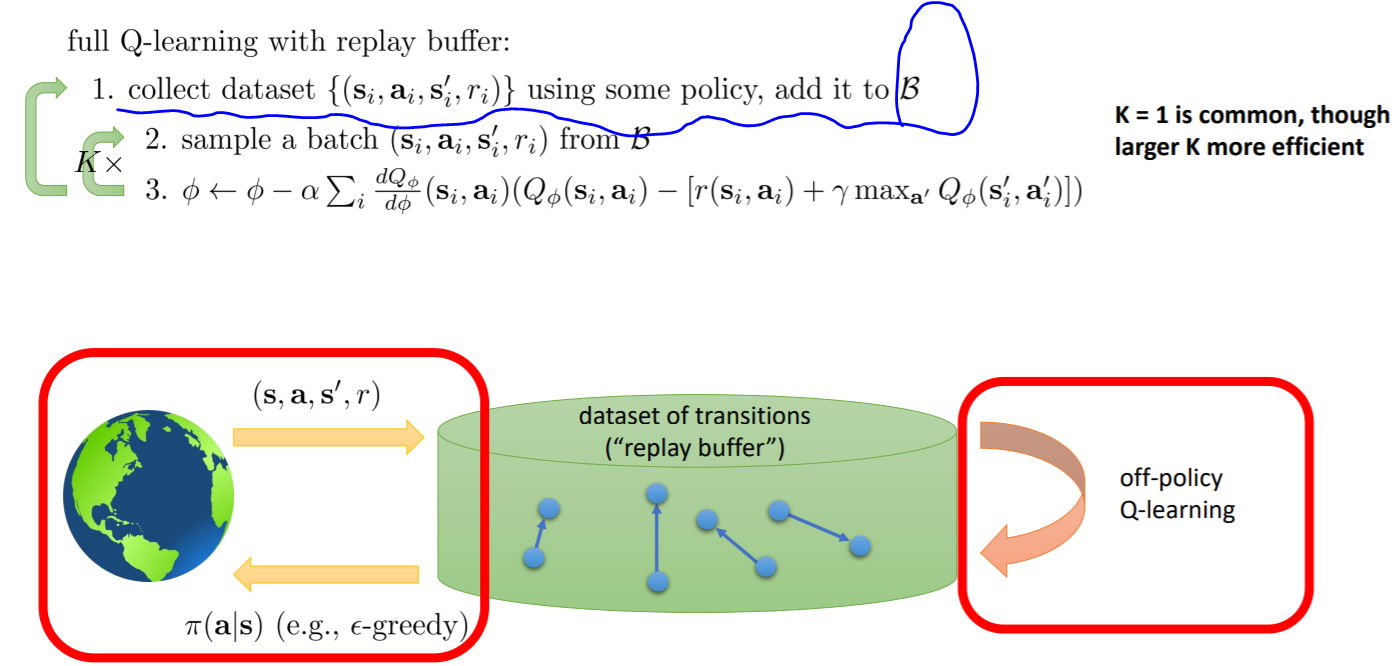
2. make an outer loop
为什么说原来的优化参数不算是 gradient descent 呢?
因为你看,原来的target是
r
(
s
i
,
a
i
)
+
γ
m
a
x
a
Q
Φ
(
s
i
′
,
a
i
′
)
r(s_i,a_i)~+~γmax_aQ_Φ(s_i',a_i')
r(si,ai) + γmaxaQΦ(si′,ai′),这个里面的第二部分max的时候一直在取当前更新的Φ作为参数时的最大值,这样就会导致不稳定。
所以我们做了改变,让target的值还是使用最老的Φ,在inner loop里面循环(优化Φ)的时候一直都是使用相同的、没有更新的Φ,直到最外侧的循环才更新Φ的值。
如下图:

another solution
在更新Φ的时候,有可能这次的Φ’ 和 新的Φ相差太大了,导致一些不好的结果,我们可以更为缓慢的更新,update softly。
在更新的时候,我们可以增加权重,在原来的Φ乘以一个较大的权重,而在新的权重很小(0.001),这样,我们可以让它朝着新Φ的方向缓慢的更新而不会过于冒进。
u
p
d
a
t
e
Φ
′
:
Φ
′
←
τ
Φ
′
+
(
1
−
τ
)
Φ
τ
=
0.999
w
o
r
k
s
w
e
l
l
update~varPhi':~varPhi'larr~tauvarPhi'~+~(1-tau)varPhi~~~~~~~~~tau=0.999~~works~well
update Φ′: Φ′← τΦ′ + (1−τ)Φ τ=0.999 works well
A genral view
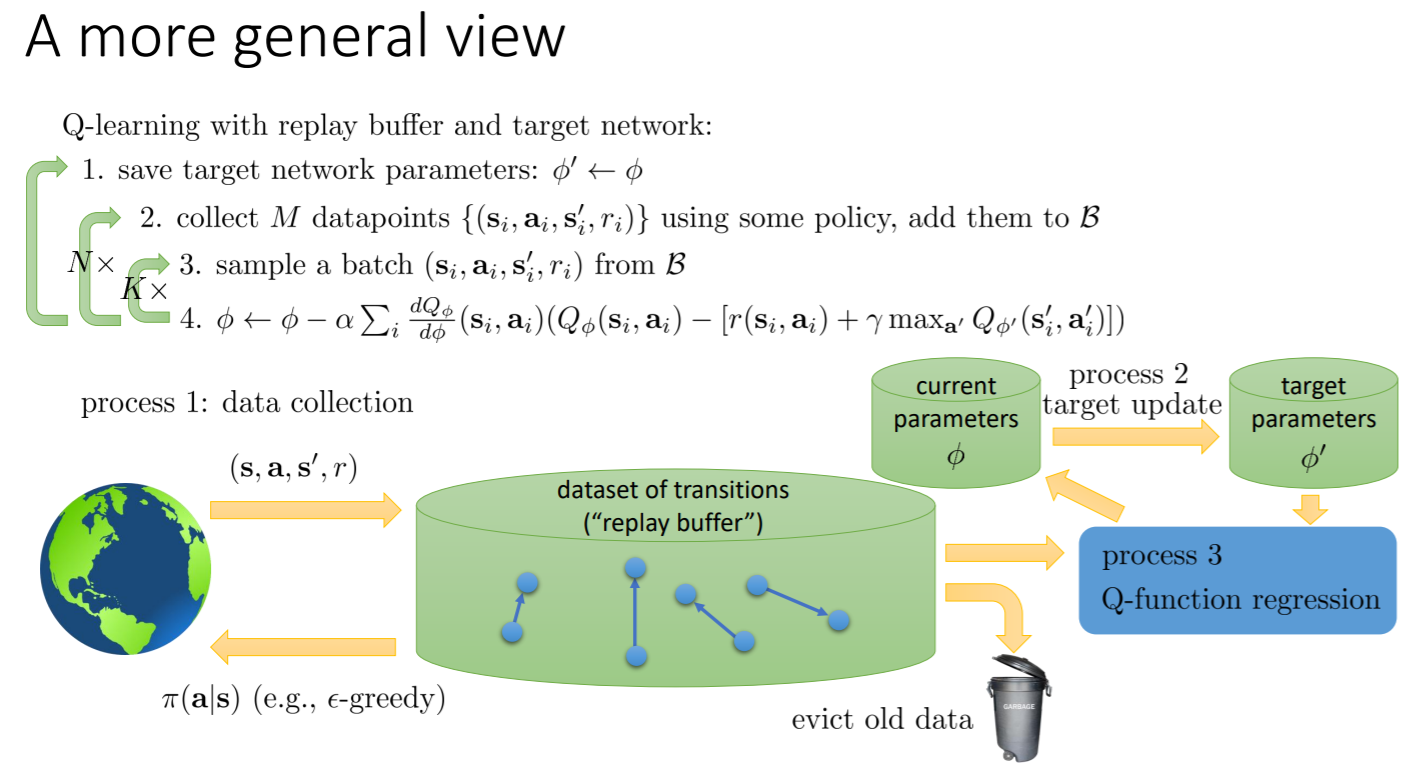

这里还有一部分是将旧的data丢弃。这里说的旧的data,不包括那些less rewarding 的数据,因为其实一些reward很少的数据(比如说掉下悬崖)其实可以帮助智能体避开掉下悬崖这个动作,让智能体记住一些不好的动作有助于更好的执行。
说实话上面这些让我感觉很熟悉啊,这些考虑在RL里面都接触过,只不过是在RL里面是提到用两个网络(ACTOR CRITIC)。上面用的是function approximator。这可能就是共通之处吧。
复制一个前段时间看的DQN,没想到这里就有讲。下面是K=1的情况。这个算法只需要一个network。

Q values are not so accurate
事实是,我们的Q值并不是非常准确,而且总是过于乐观,比实际得到的reward总是要多。这是因为我们在算法中用到了max,问题就出在这个max上:
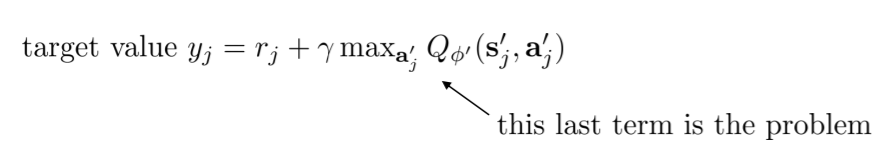
为什么呢?具体来分析,就是比方说假设有两个变量X1, X2,总有:
E [ m a x ( X 1 , X 2 ) ] > = m a x ( E ( X 1 ) , E ( X 2 ) ) E[max(X_1,X_2)]~>=~max(E(X_1),E(X_2)) E[max(X1,X2)] >= max(E(X1),E(X2))
thus,
m
a
x
a
Q
Φ
(
s
i
′
,
a
i
′
)
max_aQ_Φ(s_i',a_i')
maxaQΦ(si′,ai′) overestimates the next state

所以,要想解决这种问题,就需要使用两个network,选择下一个动作的时候用一个,进行评估价值的时候用另一个。
但是两个网络是有些复杂的,能不能简化呢? 当然能!
于是我们在实际中实际上是这么操作的:
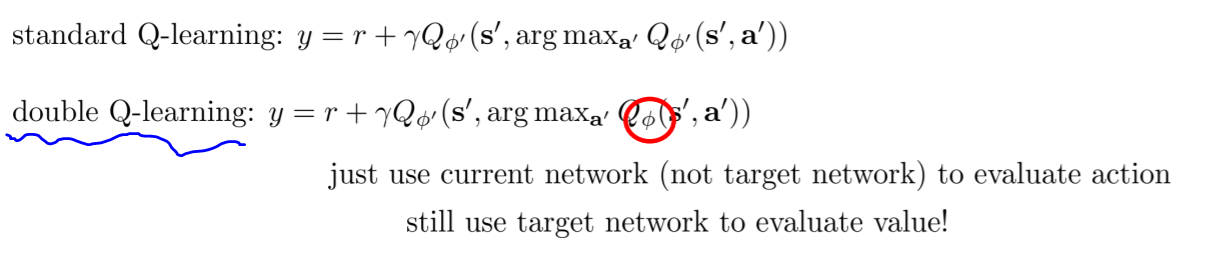
这样,就简单多了,还是一个network,但是实现了我们的要求。这种方法就是DDQN。
Q Learning with n-step returns
为什么要提出这个呢?因为当我们的Q值并不是很好的时候,我们可以通过 n steps 的真实值来挽回一下误差。这时target就变成了下面这样:
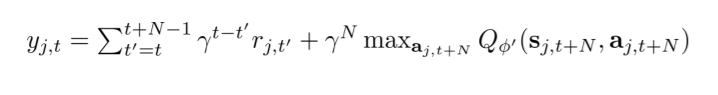
但是因为Q Learning是离轨的,所以,我们在前半部分的n步reward相加,这些reward可能是来自不同的policy得到的data,然而我们需要这些reward都来自我们想要estimate的policy。这就存在问题了。(这个问题在N = 1的时候不存在)
那么,解决的办法:
- ignore. 这很像是开玩笑,但是确实可以忽略。我们可以选择比较小的n,比如4,这样的话就算是不同的policy在较小的n时产生的transition可能是比较相似的,误差也是比较小的,而且比n=1的时候学习更快,有很多优点。
- cut the trace. 就是说,N是不确定的,但是只要某一步采取的action不是当前的policy会采取的,在buffer里面没有,就停止。这种方法在action space比较小的时候是比较好的。
- importance sampling.
最后
以上就是温暖酸奶最近收集整理的关于DRL(四)——Value Function的全部内容,更多相关DRL(四)——Value内容请搜索靠谱客的其他文章。








发表评论 取消回复