本文内容源自百度强化学习 7 日入门课程学习整理
感谢百度 PARL 团队李科浇老师的课程讲解
另外一位博主写的很精彩https://blog.csdn.net/qq_42067550/article/details/106871772
1.value-based 与policy-based
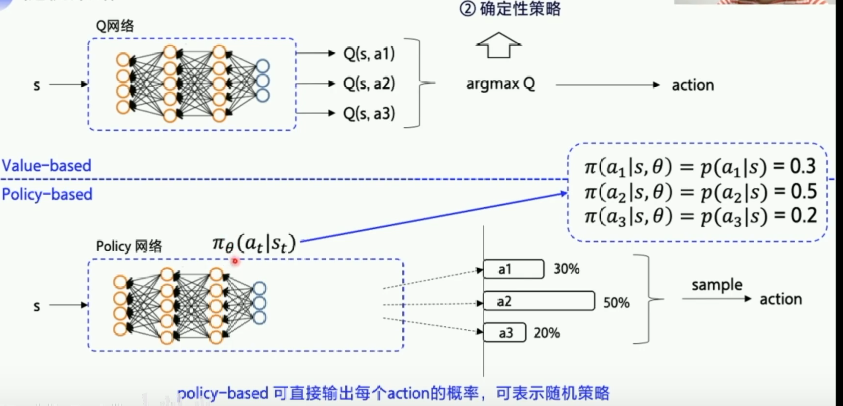
- value-based先学习动作价值函数,训练的目的让Q值迭代更新到最优,然后再根据动作价值选择最优的动作。
- policy-based直接输出动作概率,动作的选择不再依赖于价值函数,而是一条策略走到底,看这条策略的好坏。
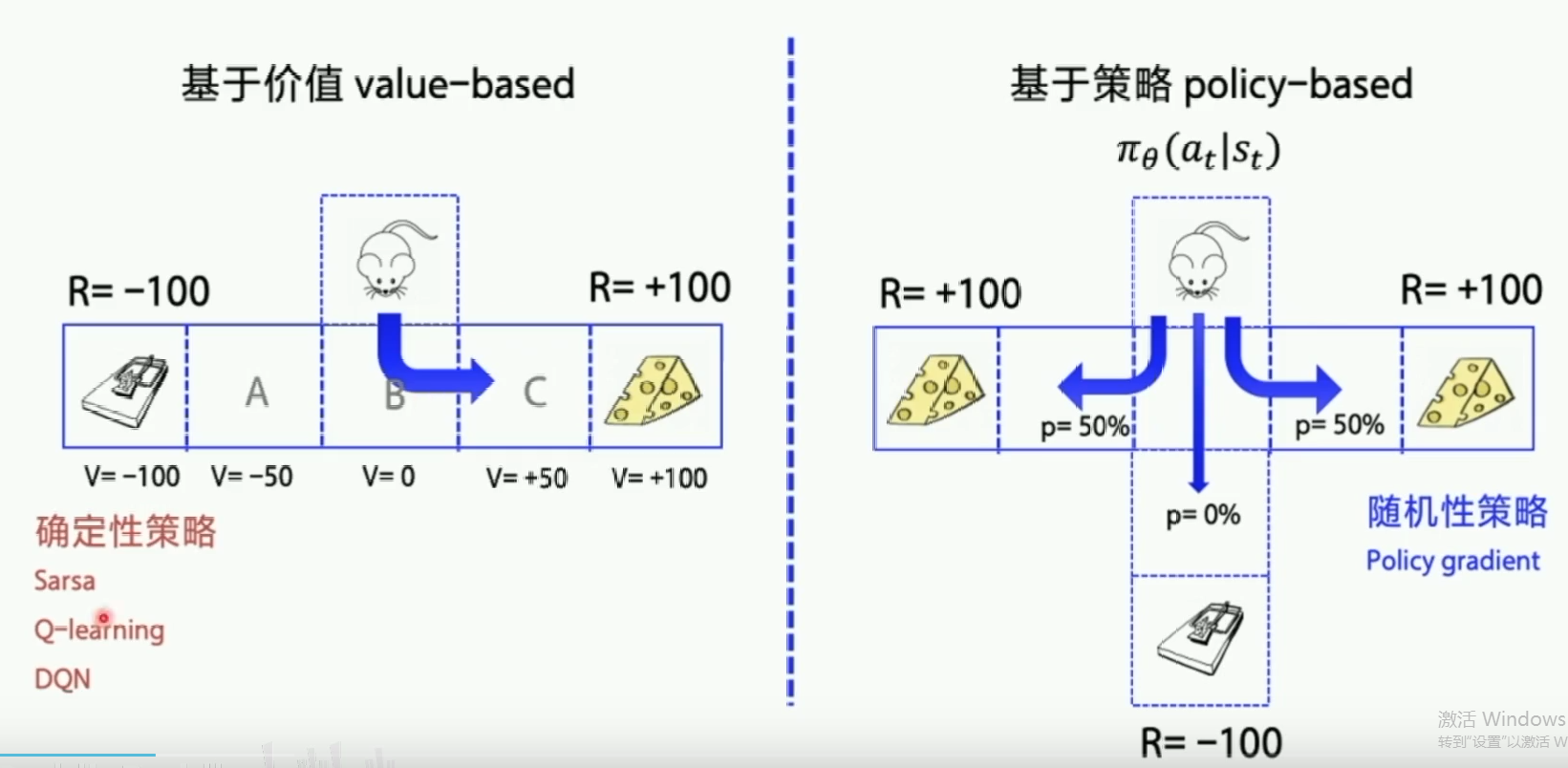
value-based
- 先求Q值,
- 然后优化的也是Q值,
- 将Q网络调到最优后
- ,输出Q值最大的动作。
- (确定性策略:优化最优后参数固定下来,输入同样的state后,输出同样的action)
policy-based
- 神经网络输入状态state,直接输出动作action
- (随机策略:输出的是动作的概率)
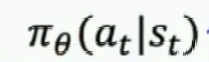 中
中是神经网络的参数:权重,偏置,
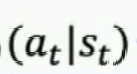 表示在st状态下输出at的概率,所有动作的概率相加为1,
表示在st状态下输出at的概率,所有动作的概率相加为1, - 概率越大的动作越容易采样到,适用剪刀石头布这种随机性比较大的游戏中,经过一段时间后可能发现,3个动作的概率为33%,
- 如果使用DQN,可能最后一直一个动作。
2.softmax函数
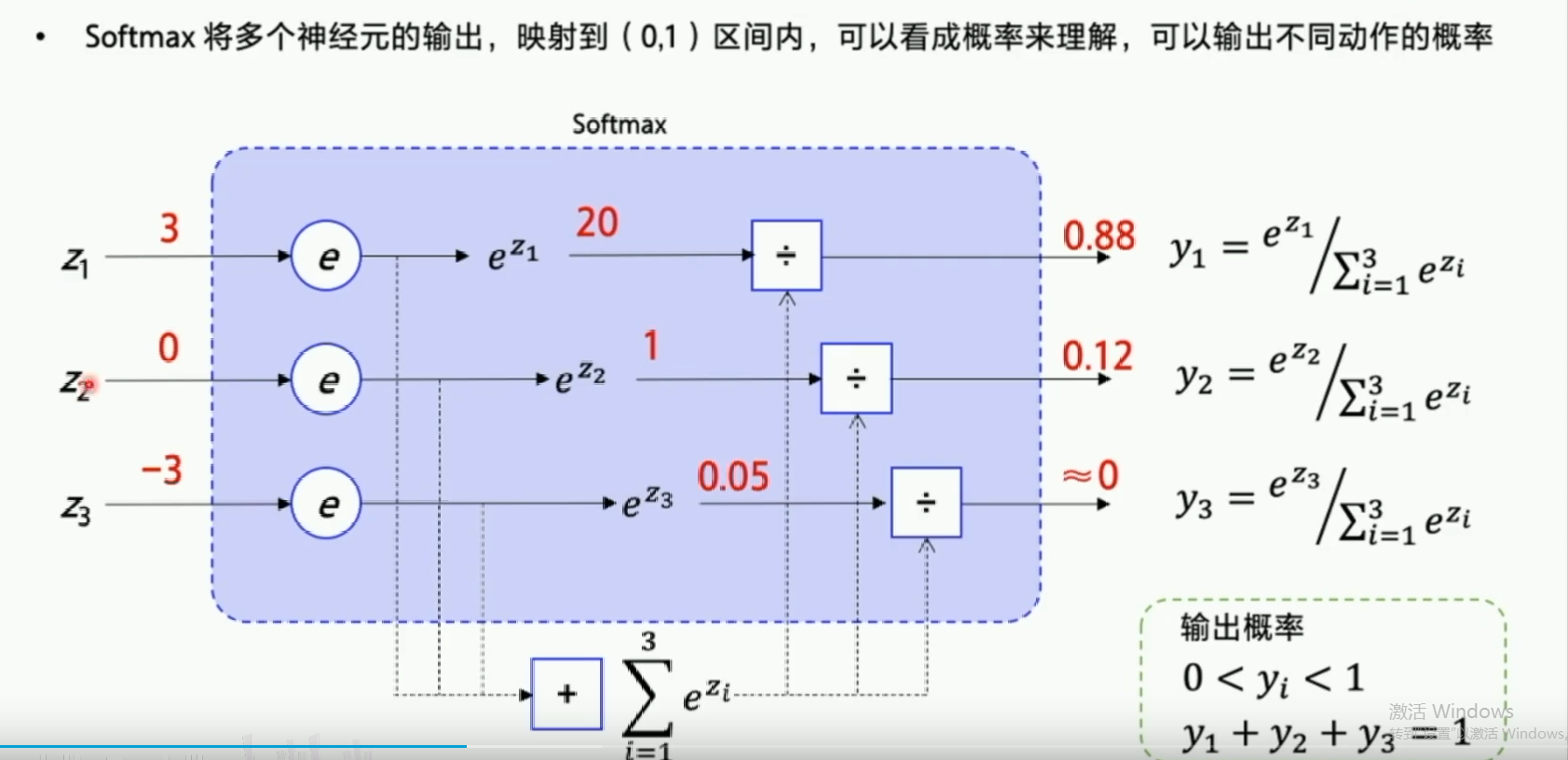
3.举例:策略网络输入的是整个图像(向量或矩阵),输出的是3个动作的概率(向量),然后根据这个概率随机挑选一个动作输出
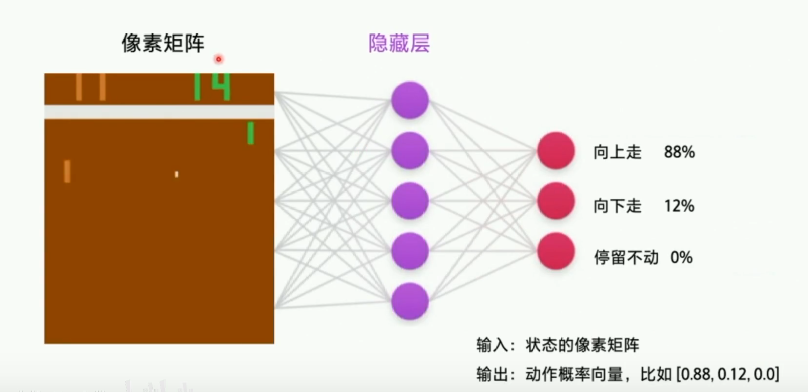
代表策略输出的概率,
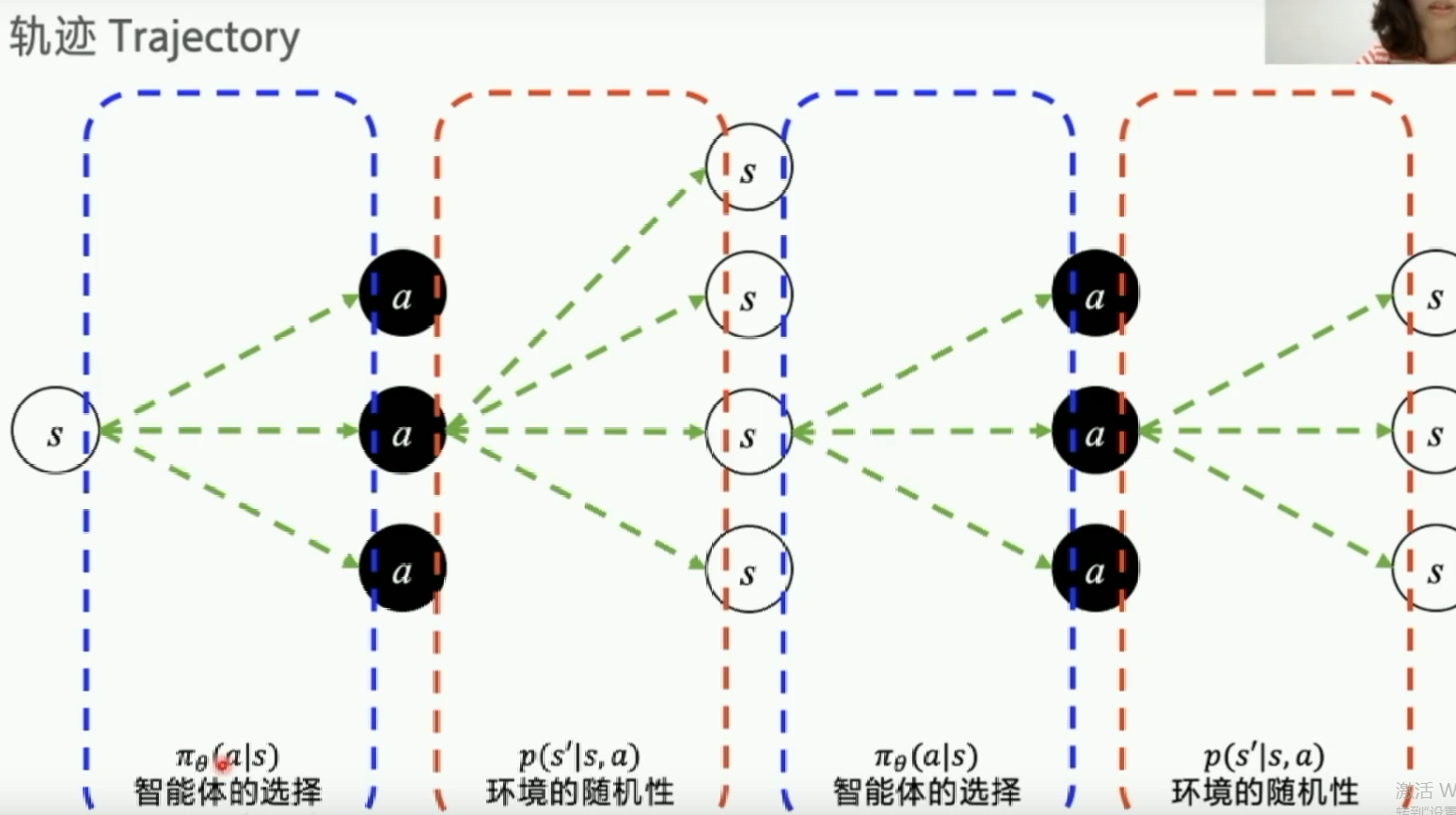
在状态s下选择a的概率,由于环境的随机性,不同的策略到不同
的环境,这个概率用p来表述,称作状态转移概率。代表智能体在环境s选择动作a后有
多少概率去s'(智能体的选择是可以优化的,环境的随机性是无法人为控制的)
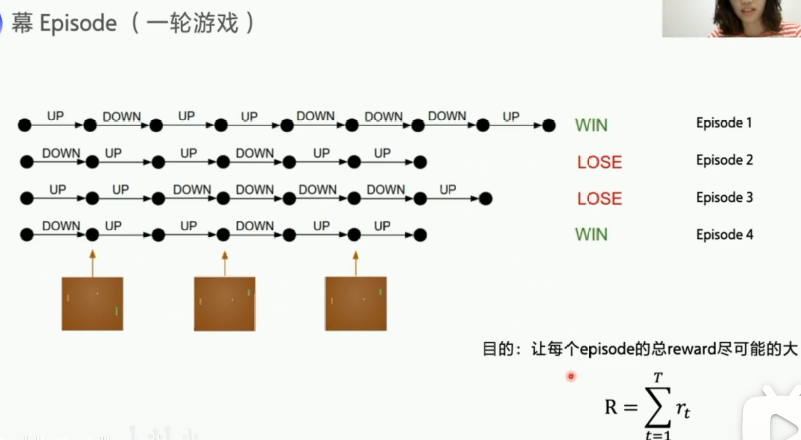
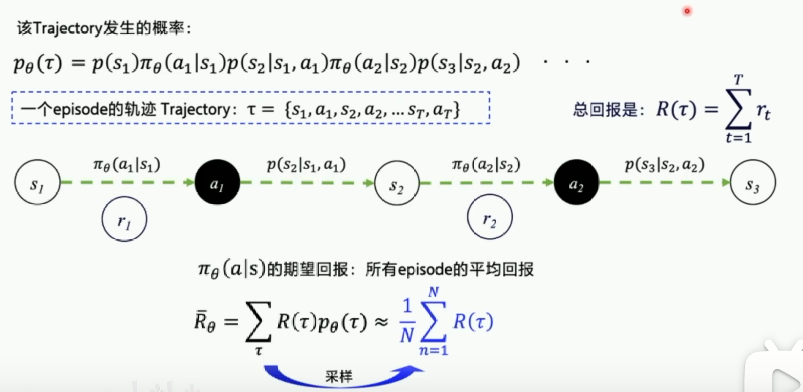
当我们选择一个动作以后,其实并不知道动作的优劣,而只有最终游戏结束得到结果的时候,我们才能反推之前的动作优劣每一个 episode 中,agent 不断和环境交互,输出动作,直到该 episode 结束,然后开启另一个 episode。
优化策略的目的:让 “每一个” episode 的 “总的” reward 尽可能大
- 单个 episode 有很多 step 组成,每个 step 会获得 reward
- 所有 episode 总的 reward 希望最大
- 所以怎么去量化我的优化目标就是个难点!
期望回报:
在正常的情况下不会穷举所有的轨迹,且环境转移概率也不易计算,所以当N足够大的时候,交互N个episode,拿到的分数求平均,近似拟合期望回报,这个过程称作采样。
4.策略梯度
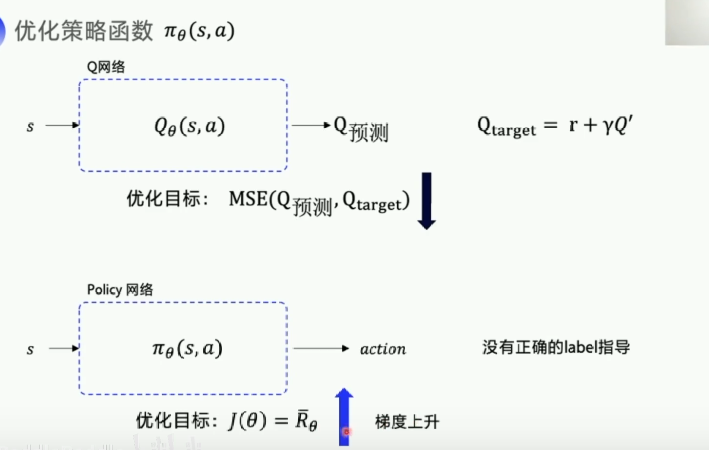
DQN优化Q网络构造一个Loss函数作为优化目标,拿Q预测逼近QtargetLoss函数越小越好,
Policy网络输入状态s,输出动作action,其没有正确的label指导,不知道该状态下什么action比较好,所以要采用期望回报来进行优化目标,其优化目标越大越好,这个操作叫做梯度上升,神经网络的参数更新需要根据梯度决定更新方向,所以需要求解对
的梯度来更新网络。
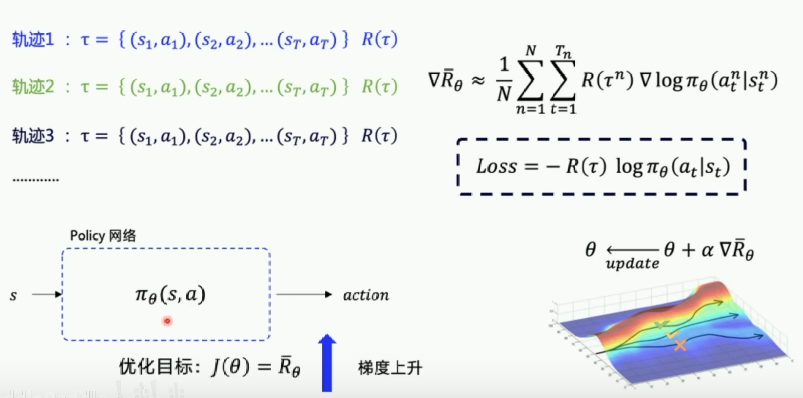
为了计算策略梯度,需要产生n条轨迹,每一条轨迹都可以求出一个和
(
的导数,求导的过程可以约去不可知的环境转移概率)
可通过多条轨迹,计算梯度,来更新网络,让分数高的轨迹对应的动作的概率更大一些,根据可以反推Loss函数,所以 loss 的公式前面要加上负号,这样就可以让梯度下降变成梯度上升。
最后
以上就是神勇烤鸡最近收集整理的关于强化学习——随机策略与策略梯度的全部内容,更多相关强化学习——随机策略与策略梯度内容请搜索靠谱客的其他文章。








发表评论 取消回复