强化学习当中策略可以分为随机策略和确定性策略两类。
1 确定性策略
确定性策略是输入一个状态s,策略会给出一个确定的动作a,可以用以下形式表示。u表示的是确定性策略。t时刻的状态写作st。t时刻在st状态下采取的动作为at。
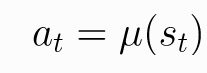
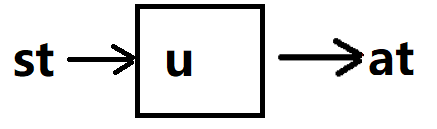
实现时,只需要建立一个神经网络,输入状态,输出一个确定的动作就行。
使用了确定性策略的算法有:DDPG、TD3。
DQN中的目标策略一般也是贪婪的确定性策略。
2 随机策略
随机策略是输入一个状态s,输出的是动作分布。随机策略通常用π表示。对于st条件下,每一个动作都是以概率被选取。
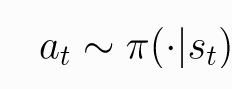
随即策略可以根据动作是连续的还是离散的进行分类。连续动作是指动作可以连续取值,比如说,动作可以是力,力的数值可以去连续的数值,一般连续动作的取值是无法穷举的。而离散的动作比如在玩打飞机的时候,动作是上,下,左,右这种可以穷举的值。
离散动作对应的随机策略称为分类策略。
连续动作对应的随机策略称为对角高斯策略。
2.1 分类策略
分类策略由于动作是离散的,可以穷举,因此我们可以直接定义一个输出所有动作概率的神经网络。
构建神经网络。
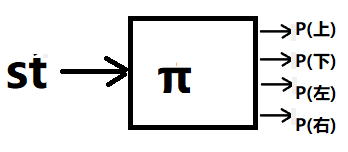
比如离散动作是上、下、左、右。于是,可以建立如下神经网络。输入状态,输出4个动作对应的概率。
其中P(上)+P(下)+P(左)+P(右)= 1
2.2 对角高斯策略
假如我们动作的是力。那么就无法按上述神经网络一样构造了。因为动作无法列举出来。因此,通常我们会使用高斯分布。因为只需要均值和标准差就能确定一个高斯分布。因此,我们可以利用神经网络输出均值。我们又可以根据标准差如何获取分成以下两种情况。
(1)标准差不使用关于状态s的函数,而是独立的参数。(TRPO 和 PPO采样的是这种实现方式)
(2)标准差是关于状态s的函数,这时,我们可以在输出均值的神经网络的输出层,增加一个输出值,输出标准差。
我们需要注意的是,无论上面那种方法,虽然我们表述的时候说的是输出标准差,实际操作的时候,我们输出的是标准差的对数值。因为标准差一定是正数,对于神经网络网络来说,要去保证输出的标准差是正数就需要增加额外的约束条件,但是假如我们输出的是log标准差,那么神经网络输出的就可以是任意实数了,输出之后,我们只需要去一个e的指数,就能还原标准差。
下面假设一个一维动作的情况下,构建的神经网络如下。(对于多维,就是一堆均值,以及协方差矩阵的值)
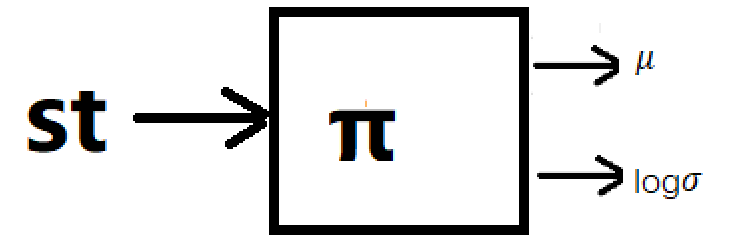
最后
以上就是专注发卡最近收集整理的关于强化学习之确定性策略网络和随机策略网络1 确定性策略2 随机策略2.1 分类策略2.2 对角高斯策略的全部内容,更多相关强化学习之确定性策略网络和随机策略网络1内容请搜索靠谱客的其他文章。








发表评论 取消回复