- 本篇译文为方便自己再次阅读而记录,源自Google翻译和CNKI翻译助手。
- 习惯用语保持英文(例:agent),一些细微之处结合自己理解稍加修改,为方便阅读,译文删除了参考文献相关部分。
- 才疏学浅,未读懂或不确定处在
[ ]内附英文原文,欢迎大家指正,有任何侵权或者不妥之处请及时告知,将尽快处理。
安全强化学习综合调查
- 摘要
- 关键字
- 1. 引言
- 2. 安全强化学习概述
- 3. 修改优化标准
- 4. 改进探索过程
- 4.1 合并外部知识
- 4.1.1 提供初始知识
- 4.1.2 从有限演示集中选取策略
- 4.1.3 使用示教者建议
- 4.1.3.1 学习者agent寻求建议
- 4.1.3.2 示教者提供建议
- 4.1.3.3 其他方法
摘要
安全强化学习可以定义为在学习和/或部署过程中确保合理的系统性能和/或尊重安全约束很重要的问题的回报期望最大化的学习策略的过程。 我们对安全强化学习的两种方法进行分类和分析。 第一个是基于优化标准的修改,使经典的带折扣的有限/无限视界具有安全系数。第二种是基于通过结合外部知识或风险指标的指导来修改探索过程。 我们使用提议的分类来调查现有文献,并建议安全强化学习的未来方向。
关键字
强化学习, 风险敏感, 安全探索, 指导建议 [teacher advice]
1. 引言
在强化学习 (RL) 任务中,agent感知环境状态,并基于真实有价值的奖励信号采取最大化长期回报的行动。然而,在agent的安全性特别重要的某些情况下,例如在昂贵的机器人平台中,研究人员不仅越来越关注长期奖励最大化,而且越来越关注避免机器人受到损害。
安全概念,或者它的对立面,风险,在 RL 文献中有多种形式,它不一定是指物理问题。 在许多工作中,风险与环境的随机性有关,并且在这些环境中,即使是(关于回报的)最佳策略在某些情况下也可能表现不佳。 在这些方法中,风险概念与环境的固有不确定性(即具有随机性)有关。由于最大化长期回报并不一定能避免罕见的大的负面结果,我们需要其他标准来评估风险。在这种情况下,长期回报最大化被转换为包括一些与回报方差或其最坏结果相关的风险概念。在其他工作中,优化标准[optimization criterion]被转换为包括访问错误状态的概率,或将时间差异转换为出乎意料的坏的更重的加权事件。
其他工作不改变优化标准,而是直接改变探索过程。 在学习过程中,agent决定选择哪个动作,或者是了解更多关于环境的信息,或者是向目标更近一步。在 RL 中,在学习阶段选择动作的技术称为探索/利用策略。大多数探索方法基于启发式,依赖于从环境采样中收集的统计数据,或者具有随机的探索性成分(例如 ε-greedy)。他们的目标是有效地探索状态空间。然而,这些探索方法中的大多数都对行动的风险视而不见。 为避免出现危险情况,通常会通过包含任务的先验知识来修改探索过程。这种先验知识可用于为 RL 算法提供初始信息,以偏向后续探索过程,或提供有关任务的有限演示集,或提供指导。 基于先验知识的方法最初并不是为了处理风险领域而构建的,但根据它们的设计方式,它们已被证明特别适合此类问题。例如,2009 年 RL 竞赛直升机控制任务的获胜者使用初始知识来引导进化方法。在这种方法中,几个克隆了无错误指导策略[clone error-free teacher policies]的神经网络被添加到初始群体中(促进算法快速收敛到接近最优的策略,并间接地减少agent损坏或伤害)。事实上,由于直升机领域的获胜者是累积奖励最高的agent,获胜者还必须间接减少直升机坠毁,因为这些会导致巨大的灾难性负奖励。 尽管比赛是基于学习阶段之后的表现,但这些方法表明,在学习阶段减少灾难性情况的数量,特别有益于以在线方式而不是通过模拟器执行的真实机器人中。 相反,Abbeel 和 Ng (2005);Abbeel 等人 (2010) 使用教师[teacher]的一组有限演示来推导出直升机控制任务的安全策略,同时最大限度地减少直升机坠毁。 最后,教师在探索过程中提供的指导也被证明是避免危险或灾难性状态的有效方法。在另一条研究线中, 探索过程是使用某种形式的风险度量进行的,这种度量基于熵度量和预期回报的加权和的时间差异。
在这份手稿中,我们对工作进行了全面调查,其中考虑了 RL 社区内的安全和/或风险概念。我们将 RL 中的这个子领域称为安全强化学习。 安全强化学习可以定义为一种学习最大化回报期望的策略的过程,在学习和(或)部署过程中,该过程十分重视确保合理的系统性能和(或)尊重安全约束。[Safe RL can be defined as the process of learning policies that maximize the expectation of the return in problems in which it is important to ensure reasonable system performance and/or respect safety constraints during the learning and/or deployment processes.] 安全强化学习算法缺乏用于组织现有方法的既定分类法。 在本次调查中,我们通过安全强化学习算法的分类贡献了这样一个结构。 我们将安全强化学习算法分为两种基本的大类[two fundamental tendencies]。 第一类包括转换优化标准[transforming the optimization criterion]。第二类包括以两种方式修改探索过程[modifying the exploration process]:(i)通过整合外部知识,以及(ii)通过使用风险度量。 在这一类别中,我们专注于那些在风险领域中测试的 RL 方法,这些方法通过修改探索过程来减少或防止不良情况。 这样做的目的是成为开始在安全强化学习中努力的研究人员的起点。 重要的是要注意,第二类包括第一类,因为修改优化标准也会修改探索过程。 然而,在第一类中,我们考虑以某种方式转换优化标准以包含某种形式的风险的方法。 另一方面,第二类中的优化标准仍然存在,而探索过程被修改以考虑某种形式的风险。
基于这些考虑,本文的其余部分组织如下。第 2 节介绍了文献中现有的安全强化学习算法的概述和分类。第 3 节调查基于优化标准转换的方法。第 4 节考虑通过使用先验知识或风险度量来修改探索过程的方法。第 5 节我们讨论调查的方法并确定未来工作的开放研究领域[open areas of research]。 最后,我们以第 6 节结束。
2. 安全强化学习概述
我们考虑在由元组 < S, A,T, R > 正式描述的马尔可夫决策过程 (MDP) 中学习,其中 S 是状态空间,A 是动作空间,T : S × A → S 是转换函数, R : S × A → R 是奖励函数。 在本次调查中,我们考虑了安全强化学习(表 1)在 MDP 中学习的两个主要趋势。 第一个是基于对最优性标准的修改,引入了风险的概念(第 3 节)。第二个是基于探索过程的修改,以避免可能导致学习系统出现不良或灾难性情况的探索性行为(第 4 节)。
优化标准[Optimization Criterion]。 关于第一点,传统强化学习算法的目标是找到最优控制策略;也就是说,找到一个函数,该函数为系统的某些状态指定了一个动作或策略,以优化一个标准。 该优化标准可以是最小化时间或任何其他成本指标,或最大化奖励等。 RL 中的优化标准由已发表文献中的各种术语描述,包括预期回报、预期奖励总和、累积奖励,累计打折奖励或返回值[return]。在本文中,为避免术语误解,我们使用术语return。
定义 1 Return。术语return用于指预期的带折扣的未来累积奖励 R = ∑ t = 0 ∞ γ t r t R = sum_{t=0}^∞ γ^t r_{t} R=∑t=0∞γtrt ,其中 r t r_{t} rt 表示一个用于评估选择特定状态下动作的实数(即奖励), γ ∈ [ 0 , 1 ] γ ∈ [0, 1] γ∈[0,1] 是折扣因子,可以控制未来奖励的影响。
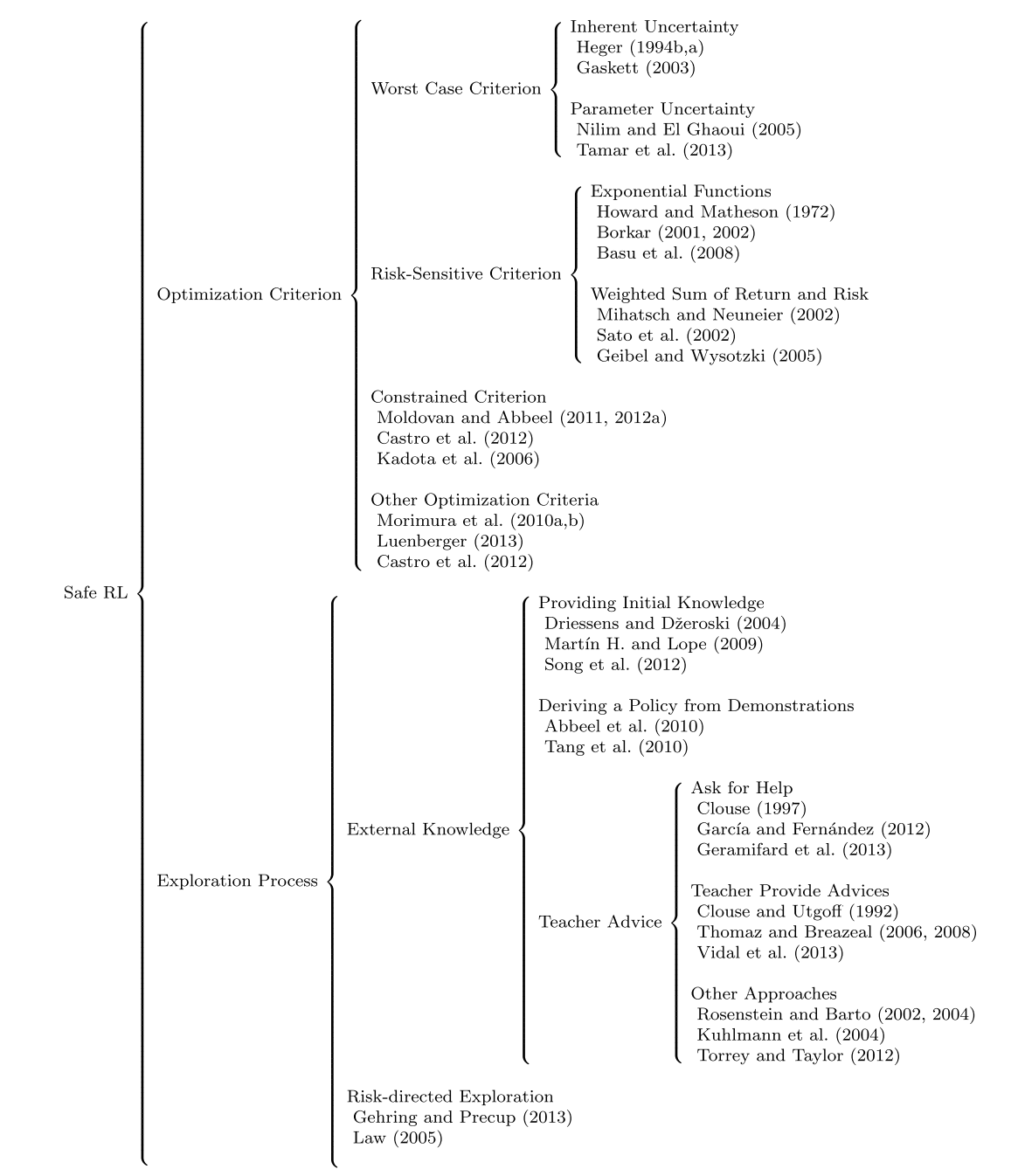
表 1:本调查中考虑的安全强化学习方法概述。
在危险或有风险的任务中,此优化标准并不总是最合适的。 为了考虑风险,此优化标准有多种替代方案。 在本次调查中,我们将这些优化标准分为四组:(i) 最坏情况标准[the worst-case criterion],(ii) 风险敏感标准[the risk-sensitive criterion],(iii) 约束标准[the constrained criterion],以及 (iv) 其他优化标准[the constrained criterion]。
- 最坏情况标准: 第一个标准基于最坏情况标准,如果策略具有最大的最坏情况回报,则该策略被认为是最佳的(第 3.1 节)。该标准用于减轻给定策略引起的可变性的影响,因为这种可变性可能导致风险或不良情况。这种可变性可能是由于两种类型的不确定性造成的:与系统随机性相关的固有不确定性,以及与 MDP 的某些不确定参数相关的参数不确定性。
- 风险敏感标准: 在其他方法中,优化标准被转换以反映平衡收益和风险的主观度量。这些方法被称为风险敏感方法,其特点是存在允许控制风险敏感性的参数(第 3.2 节)。在这些情况下,优化标准被转换为指数效用函数,或收益和风险的线性组合,其中风险可以定义为收益的方差,或进入错误状态的概率。
- 约束条件: 这个目标的目的是在一个或多个约束条件下最大化回报,从而产生约束优化标准(第 3.3 节)。在这种情况下,我们希望在保持其他类型的预期度量高于(或低于)某些给定界限的同时最大化回报。
- 其他优化标准: 最后,其他方法基于使用属于金融工程领域的优化标准,例如 r 平方
[r-squared]、风险价值[value-at-risk](VaR) 或回报密度[the density of the return](第 3.4 节)。
探索过程[Exploration Process]。 对于探索过程的修改,也有几种方法可以克服探索行为可能产生严重后果的问题。大多数 RL 算法在没有外部知识的情况下开始学习。在这种情况下,使用诸如 ε−greedy 之类的探索策略。这种策略的应用导致对状态和动作空间的随机探索,以收集有关任务的知识。只有当从环境中发现足够的信息时,算法的行为才会改善。然而,随机探索策略浪费了大量时间探索状态和动作空间的不相关区域,或者导致智能体进入可能对智能体、学习系统或外部实体造成损害或伤害的不良状态。 在本次调查中,我们考虑了两种修改探索过程以避免风险的方法:(i) 通过结合外部知识[through the incorporation of external knowledge],以及 (ii) 通过使用风险导向探索[risk-directed exploration]。
- 外部知识。 我们通过以下方式区分将先验知识纳入探索过程(第 4.1 节)的三种方式:(i) 提供先验知识
[providing initial knowledge],(ii) 从有限的演示集得出策略[deriving a policy from a finite set of demonstrations],以及 (iii) 提供示教建议[providing teach advice]。- 提供先验知识。 为了减轻上述探索困难,可以使用从示教者
[teacher]那里收集的示例或任务的先前信息来为学习算法提供初始知识(第 4.1.1 节)。该知识可用于引导学习算法(即一种初始化过程)。在此初始化之后,系统可以根据初始训练阶段预测的值切换到玻尔兹曼机[Boltzmann]或完全贪婪策略的探索[fully greedy exploration]。通过这种方式,学习算法从学习过程的最早阶段就接触到状态和动作空间中最相关的区域,从而消除了随机探索发现这些区域所需的时间。 - 有限的演示集中得出策略。 以类似的方式,示教者提供的一组示例可用于从演示中导出策略(第 4.1.2 节)。在这种情况下,随机探索策略提供的示例被示教者提供的示例替换。与前一类别相比,这种外部知识不用于引导学习算法,而是用于学习一个模型,从该模型以离线且因此安全的方式导出策略。
- 提供教学建议。 其他基于示教者建议的方法有助于学习过程中的探索(第 4.1.3 节)。他们假设正在学习的agent有老师。示教者可以是人类或简单的控制者,但在这两种情况下,它都不需要是任务的专家。每一步中,agent观察状态,选择一个动作,并以最大化回报或其他优化标准为目的接收奖励。示教者共享此目标,并向学习agent提供操作或信息。agent和示教者都可以在学习过程中发起这种交互。在寻求帮助的方法中(第 4.1.3.1 节),正在学习的agent在认为有必要时会向示教者请求建议。换句话说,示教者仅在明确要求时才向正在学习的agent提供建议。在其他方法中(第 4.1.3.2 节),示教者在认为有必要时提供行动。在另一组方法(第 4.1.3.3 节)中,这种交互中的主要作用不是很清楚。
- 提供先验知识。 为了减轻上述探索困难,可以使用从示教者
- 风险导向的探索。 在这些方法中,风险度量用于确定在探索过程中选择不同动作的概率(第 4.2 节),同时保留经典的优化标准。
3. 修改优化标准
4. 改进探索过程
4.1 合并外部知识
4.1.1 提供初始知识
4.1.2 从有限演示集中选取策略
4.1.3 使用示教者建议
当Agent在一个坏的决策会引发危险的环境下学习时,避免其在探索环境时陷入危机状态是至关重要的。在这些领域,不同的示教者建议[teacher advice]方式在强化学习中已被提出作为一种安全探索形式。示教者提供的指导从两个方面支持安全探索。首先,示教者可以在其设计的策略空间中指导学习者,该指导降低了学习技术的样本复杂性,这在处理危险或高风险领域时很重要。其次,当学习者或示教者认为有必要时,示教者能够向学习者提供建议(例如,安全的动作)以防止灾难性情况发生。
从外部建议中学习程序的想法是由 John McCarthy 于 1959 年首次提出的。示教者的建议基于两个基本的训练信息来源:根据给定状态的给定策略采取行动所获得的未来回报(源自强化学习中的经典探索),以及示教者关于下一步采取何种行动的建议。此处考虑的方法的目标是将这两种培训信息来源结合起来。在这些方法中,学习者代理根据信息(即建议)改进其策略。
定义 7 Teacher Advising。 能够为控制算法提供输入的任何外部实体,该输入可被Agent用于做出决策和修改其探索进程。
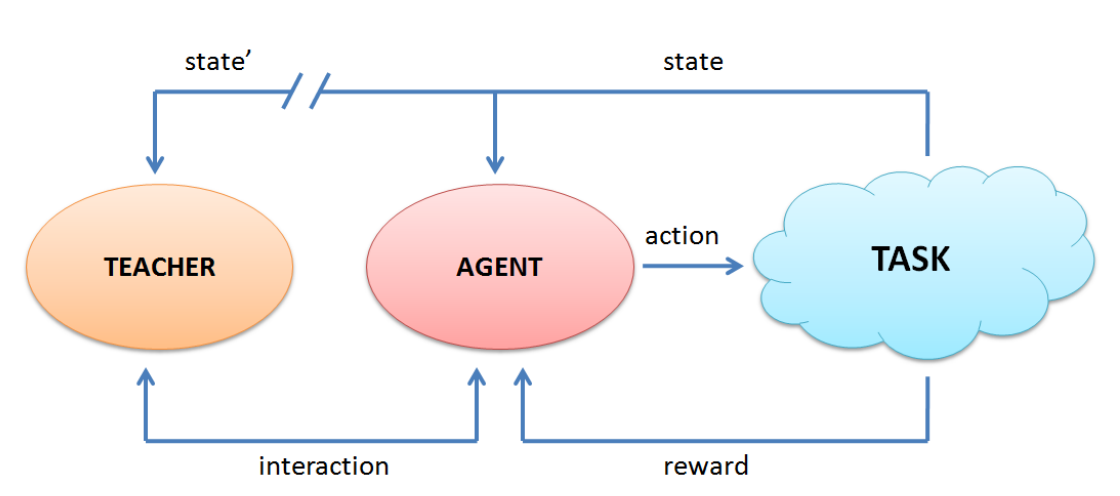
图3:通用的示教者-学习者交互方案
图 3 详细说明了示教者和学习者代理之间的这种交互方案。 在每个时间步中,学习者agent感知状态,选择要执行的动作,并像经典的 RL 交互一样获得奖励。 在这个框架中,示教者通常观察与学习者相同的状态,由学习者或示教者决定何时适合示教者提出建议。 然而,如果智能体观察到的状态 s t a t e state state 和示教者观测到的状态 s t a t e ′ state' state′ 有不同的感知机制(例如,机器人学习者的相机不会像人类教师的眼睛那样检测状态变化),它们所观察到的状态可能会有所不同。 此外,建议的性质可以有多种形式:学习者当前执行的单个动作;学习者agent在内部重放的完整动作序列;用于交互判断agent行为的奖励;一个agent必须随机或贪婪地从中选择一个动作的动作集。
示教者建议的总体框架包括四个主要步骤原文为[five main steps]:(i) 请求或接受建议; (ii) 将建议转化为可用的形式; (iii) 将重新制定的建议整合到agent的知识库中; (iv) 判断建议的价值。 在本次调查中,我们专注于通过第一步的不同趋势对不同方法进行分类。因此,有两大类算法:学习者agent在需要时向示教者寻求建议,示教者在必要时向学习者提供建议。
4.1.3.1 学习者agent寻求建议
在这种方法中,学习者agent提出一个置信度参数,当这种状态的置信度较低时,学习者agent向示教者寻求建议。 通常,此建议对应于示教者在当前状态下代替学习者agent将执行的操作。在得到建议的情况下,学习者agent通过首先执行该动作(因为学习者自己选择它),然后接收相应的奖励来学习示教者的动作。此奖励用于使用任何强化学习算法更新策略。这些示教者建议算法称为寻求帮助算法。在最初的寻求帮助方法中,Clouse 在两种不同的策略中使用了置信度参数:统一询问策略和不确定性询问策略。首先,学习者的要求在整个学习过程中服从均匀分布。在这种情况下,此参数确定学习者请求帮助的时间步长的百分比。第二个是基于学习者agent对其当前动作选择的不确定性。在这种情况下,当当前学习步骤中的所有动作都具有相似的 Q 值时,Clouse 确认Agent不确定要选择的动作;即,如果最小和最大 Q 值非常相似(由置信度参数指定),则学习器agent会寻求建议。然而,最高和最低 Q 值之间的这种间隔估计测量会在某些领域(例如迷宫领域)中产生违反直觉的结果。在这个域中,每个状态的真实 Q 值非常相似,因为迷宫状态是高度连接的。因此,对于类似迷宫的域,区间估计不是一个稳定的置信度度量。
Hans;Garc´ıa 和 Fern´andez;Garc´ıa等人使用此置信度参数来检测危险情况。在这种情况下,风险的概念基于致命转变或未知状态的定义。Hans等人认为如果相应的奖励小于给定的阈值 τ,则认为转换是致命的,如果操作 a 导致致命的转换,则在给定状态 s 中将其视为不安全。在这项工作中,作者还使用修改后的贝尔曼最优方程构建了示教者策略,该方程不会最大化回报,而是最小的回报。学习者代理尝试使用示教者策略或基于级别的探索策略中先前确定的安全动作,来探索所有状态被认为安全的动作,这需要存储大量元组。
Garc´ıa 和 Fern´andez;Garc´ıa等人提出基于未知和已知空间的风险新定义,这反映了作者对人类学习者何时需要建议的直觉。当然,当人类处于新的或未知的情况时,他们会从帮助中受益。作者使用基于案例的方法来检测此类情况。 传统上,基于案例的方法使用密度阈值 θ 来确定何时应将新案例添加到内存中。当最近邻到查询状态的距离大于 θ 时,添加一个新案例。 Garc´ía 和 Fern´andez 提出了 PI-SRL 算法,其中风险函数
Q
B
(
S
)
Q^{B(S)}
QB(S) 根据与案例库 B 中先前访问过的(和安全的)状态的相似性来衡量状态的风险,
B
=
c
1
.
.
.
,
c
n
B= {c_1 . . . , c_n}
B=c1...,cn。每个案例
c
i
c_i
ci 都由智能体过去经历过的状态-动作对
(
s
i
,
a
i
)
(s_i, a_i)
(si,ai) 和相关值
V
(
s
i
)
V(s_i)
V(si) 组成。当案例库中到最近状态的距离大于参数 θ 时,风险最大,而如果该距离小于 θ,则风险最小。因此,在该工作中,风险函数被定义为阶跃函数。然而,以这种方式定义风险函数表明它仍然可能对学习代理造成损害。原因是,仅在与最近已知状态的距离大于 θ 时才遵循示教者的建议可能为时已晚。另一方面,人们会期望风险函数是渐进式的。因此,当 θ 的极限接近时,风险应该开始增加,学习agent可以开始使用示教者的建议。在进一步的工作中,Garc´ıa 等人建议使用渐进风险函数来确定遵循示教者建议的可能性。该建议与 π 重用探索策略[π-reuse exploration strategy]的集成产生了 PR-SRL 算法。π 重用探索策略允许agent以概率φ使用过去的策略
Π
p
a
s
t
Π_{past}
Πpast,探索的概率为
ε
ε
ε,利用当前策略
Π
n
e
w
Π_{new}
Πnew 的概率为
1
−
φ
−
ε
1−φ−ε
1−φ−ε。在 PR-SRL 算法中,过去的策略
Π
p
a
s
t
Π_{past}
Πpast 被示教者策略替换,要学习的新策略
Π
n
e
w
Π_{new}
Πnew 被 B 中的案例库策略替换,参数
ψ
ψ
ψ 被 sigmoid 风险函数替换,
Q
B
(
S
)
Q^{B(S)}
QB(S) 计算示教者建议的概率。
Hailu 和 Sommer 还将风险的概念与距离的概念联系起来,以区分新情况。在这种情况下,学习器代理由一个前馈神经网络组成,该网络由输入层的 RBF 神经元和输出层的随机神经元组成。每个神经元代表一个宽度为
Σ
Sigma
Σ 覆盖了输入空间的超球面。学习者代理在学习过程开始时没有神经元。此时,机器人感知到一个新的状态
s
s
s,无法概括情况。因此,它请示示教者,示教者将其动作发送给学习者。学习器接收动作并添加一个神经元。当感知到一个新状态时,学习器识别出最接近感知状态的第一个获胜神经元[first winning neuron]。如果获胜神经元的距离大于
Σ
Sigma
Σ ,状态被认为是新的,学习者调用示教者并添加一个神经元来概括感知到的新情况。通过这种方式,学习者逐渐成长,从而提高其能力。
相反,Geramifard等人(2011);Geramifard等人(2012);Geramifard等人(2013)假设存在名为 s a f e : S × A → { 0 , 1 } safe: S×A → {0, 1} safe:S×A→{0,1} 的函数,如果在状态 s 执行动作 a 将导致灾难性结果,则返回 true,否则返回 false。在每个时间步,如果学习者代理认为该动作是安全的,则将在下一步执行,否则学习者调用老师认为安全的动作。安全函数基于约束函数的存在: S → { 0 , 1 } S → {0, 1} S→{0,1},表示是否允许处于特定状态。风险被定义为访问任何约束状态的概率。然而,这种方法存在两个主要缺点:(i) 对受约束的函数进行正确建模,以及 (ii) 假设系统模型是已知的或部分已知的,尽管它仅用于风险分析。 Jessica Vleugel 和 Gelens 提出了一种方法,其中不安全状态以前被标记。在这种方法中,当学习器达到先前标记的不安全状态时,它会寻求建议。
最后,虽然与从演示中学习更相关,但 Chernova 和 Veloso 也使用置信度参数,根据分类器返回的动作选择置信度度量在Agent自己决定动作和演示请求之间进行选择。 低于给定阈值的置信度表明智能体不确定要采取哪种行动,因此它以演示的形式寻求示教者的帮助,改进策略并增加对未来类似状态的置信度。
4.1.3.2 示教者提供建议
在这一类方法中,只要示教者认为有必要,示教者就会提供行动或信息。因此,在所有这些方法中,不需要在学习器代理中使用明确的机制来识别(和表达)其对建议的需求。因此,出现了一个新的开放性问题,即示教者何时提供信息最佳。 Clouse 和 Utgoff 为 RL 算法添加了一个简单的接口,以允许人类示教者在学习过程中与学习者代理进行交互。在这项工作中,示教者监控学习者的行为,并在认为必要时提供行动。这个动作应该是在那个状态下做出的正确选择。否则,学习器代理会根据其开发策略采取自己的行动。 Maclin 和 Shavlik 在他们的 RATLE 算法中使用了类似的方法,示教者可以在任何时候中断代理学习执行并使用简单的 IF-THEN 规则和涉及多个步骤的更复杂的规则输入其建议。 Thomaz 和 Breazeal 还介绍了人类示教者和学习者代理之间的接口。人类示教者通过两种方式向代理提供建议:使用交互式奖励界面和发送人类建议消息。通过第一个,示教者为学习过程的每一步引入一个奖励信号 r ∈ [−1, 1]。人类示教者接收视觉反馈,使他/她能够在将奖励信号发送给代理之前对其进行调整。在第二个阶段,代理通过暂停来开始学习循环的每次迭代,让示教者有时间介绍建议消息(1.5 秒)。如果收到建议消息,代理将在从这些消息派生的一组动作之间随机选择。否则,代理会在具有最高 Q 值的一组动作之间随机选择。以类似的方式,Suay 和 Chernova 还使用示教者为 Aldebaran Nao 人形机器人提供奖励和指导。相反,Vidal 等人提出了一种学习算法,其中强化来自人类示教者,他正在观察机器人的行为。这位示教者只需按下无线操纵杆上的按钮即可惩罚机器人。当示教者按下按钮给机器人负强化时,机器人从中学习并将控制权转移给示教者,这样示教者就可以移动机器人并将其放置在合适的位置继续学习。手动控制结束后,示教者将按下第二个按钮以继续学习过程。在所有这些方法中,示教者根据他/她自己的感觉决定何时提供信息(即,当示教者认为有必要时),但没有关于提供信息的最佳时间的标准或规则。 此外,使用示教者对学习者代理的持续监控,由于时间或成本影响,这在实践中可能是不可取的。
Maclin 等人将建议作为示教者提供的一套规则来实施。 当规则适用(即满足 LHS)时,它用于表示某些动作的 Q 值应该是高还是低。实验是使用远离域进行的,规则的一个例子表明,当最近的接球手距离最近的接球手至少 8 米(即 Q(hold) ≥ high)时,守门员应该拿着球。在后来的工作中,Maclin 等人扩展了之前的方法,建议在指定的一组状态中,某些动作优于另一个动作。因此,示教者给出的建议是关于策略而不是 Q 值,这是人类提出建议的更自然的方式(例如,当最近的接球者至少有 8 米时,持球比传球更受欢迎)。同样,Torrey 等人也使用了一组规则,但这些规则是在之前的相关任务中使用归纳逻辑编程遵循迁移学习方法学习的。用户还可以在学习过程开始之前添加关于学习规则的补充示教者建议。在学习过程中,学习者代理接收示教者的建议,代理可以根据其价值来遵循、完善或忽略它。
Walsh 等人使用了一位示教者来分析每个情节的学习者代理的回报。此返回为示教者决定是否提供演示提供了足够的信息。对于每一集,如果代理的回报低于某个测量值,则示教者决定从相同的初始状态开始展示该集的演示。通过这种方式,代理学习了它自己无法有效学习的概念。
4.1.3.3 其他方法
在其他方法中,教师和学习者代理在接受建议的交互中的控制不是预先定义的。 Rosenstein 和 Barto 提出了一种监督强化学习算法,该算法计算复合动作,该动作是教师建议的动作 ( a T a_T aT) 和评估函数 建议的探索性动作( a E a_E aE)的加权平均值,使用
a = k a E + ( 1 − k ) a T (12) a = ka_E + (1 - k)a_Ttag{12} a=kaE+(1−k)aT(12)
在等式 12 中, a E = a A + N ( 0 , σ ) a_E = a_A +N(0, σ) aE=aA+N(0,σ),其中 a A a_A aA 是针对给定状态 s s s 从代理的策略 π A ( s ) π_A(s) πA(s) 导出的动作; N ( 0 , σ ) N(0, σ) N(0,σ) 是正态分布。参数 k k k 可用于在寻求帮助方法和教师发挥主要作用的方法之间进行插值。因此, k k k 决定了学习者代理和教师的控制水平或自主性。一方面,如果学习者代理对要采取的行动完全有信心,它可以设置 k = 1 k = 1 k=1。相反,只要它需要老师的帮助以获得寻求帮助的方法(第 4.1.3.1 节),它就可以将 k k k 的值设置为接近 0。另一方面,与第 4.1.3.2 节中的方法类似,只要教师对学习器代理的自主行为失去信心,就可以设置 k = 0 k = 0 k=0。重要的是要注意,将教师建议的动作和探索性动作结合起来的提议方法最初是为连续动作空间设想的,但通过考虑动作的分布,它也可以扩展到离散动作空间。
Kuhlmann 等人还使用教师和代理的建议来计算动作。 在这项工作中,教师为当前世界状态中可能的动作生成值。它是作为一组规则实现的。如果规则适用,则相应的动作值会增加或减少一个恒定量。教师生成的值与学习代理生成的值相加。选择的最终动作是具有最大最终合成值的动作。另一方面,Judah 等人使用了一个老师,允许观察代理当前策略的执行,然后沿着轨迹来回滚动,并将任何状态下的任何可用动作标记为好或坏。学习者代理使用这些建议和自己生成的轨迹来组成代理策略,使环境中的回报最大化。 Moreno 等人通过扩展 Iglesias 等人提出的方法,将动作计算为不同教师建议的动作的组合。 在每个时间步,每个教师产生一个效用向量 u u u,其中包含一个值 u ( s , a i ) ∈ [ 0 , 1 ] u(s, a_i) ∈ [0, 1] u(s,ai)∈[0,1] 用于在当前状态 s s s 中可能执行的每个动作 a i a_i ai。然后老师的向量被合并成一个单一的向量, w ( a ) w(a) w(a)。该向量和探索性向量 e ( a ) e(a) e(a),计算为 e ( a ) = 1 − w ( a ) e(a) = 1−w(a) e(a)=1−w(a),用于绘制最终决策向量,该向量指示哪些动作最适合当前状态。
Torrey 和 Taylor 提出了一种算法,其中建议概率取决于学习者代理的置信度和教师的置信度之间的关系。 在教师比学生更有信心的状态下,它以更大的概率提供建议。随着代理对某个状态的信心增加,建议概率会降低。其他方法基于将教师执行的情节与正常的探索情节交织在一起。教师和正常探索的这种混合使 RL 算法更容易区分有益和不良或不安全的行为。 Lin 使用两种不同的交织策略。首先,在每个完整的情节之后,学习者代理从最近的 100 个经验演示中随机选择 n 个演示,最近的课程更有可能被选择。在第二个过程中,在每个完整的情节之后,智能体还会随机选择已经教过的演示进行重播。 Driessens 和 Dˇzeroski 也使用交错策略并比较其在以不同频率提供时的影响。
在其他作品中,建议采取奖励的形式。 在这种情况下,教师通过发送可以映射到标量值的反馈信号来判断代理行为的质量(例如,通过按下按钮或“好”和“坏”的口头反馈)。与强化学习相反,学习者代理寻求直接最大化教师给予的短期强化。其他作品结合了 MDP 的奖励功能和教师提供的奖励功能。
最后
以上就是负责黄豆最近收集整理的关于【论文翻译】A Comprehensive Survey on Safe Reinforcement Learning的全部内容,更多相关【论文翻译】A内容请搜索靠谱客的其他文章。








发表评论 取消回复