问题现象:DQN训练中,设置ε-greedy策略,取得相反的训练结果(智能体一开始选择最优动作,后期选择较多随机动作,为什么训练效果反而更好,是哪个环节出现问题了)。
问题描述:(1)智能体有ε的概率选择随机动作,(1-ε)的概率选择最优动作。在训练中,令ε单调递减(一开始更多选择随机动作,随着训练加深,逐渐选择最优动作)。代码如下所示
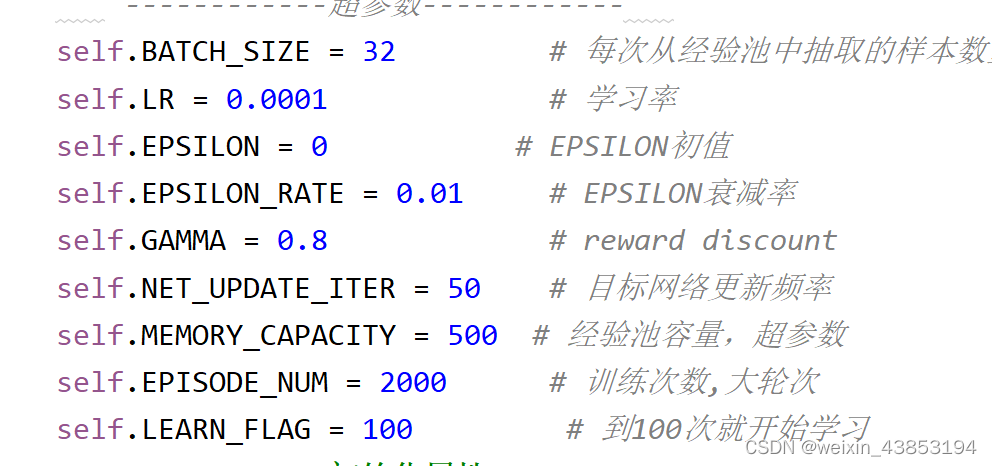
图A1 参数设置(合理值)

图A2 动作选择函数
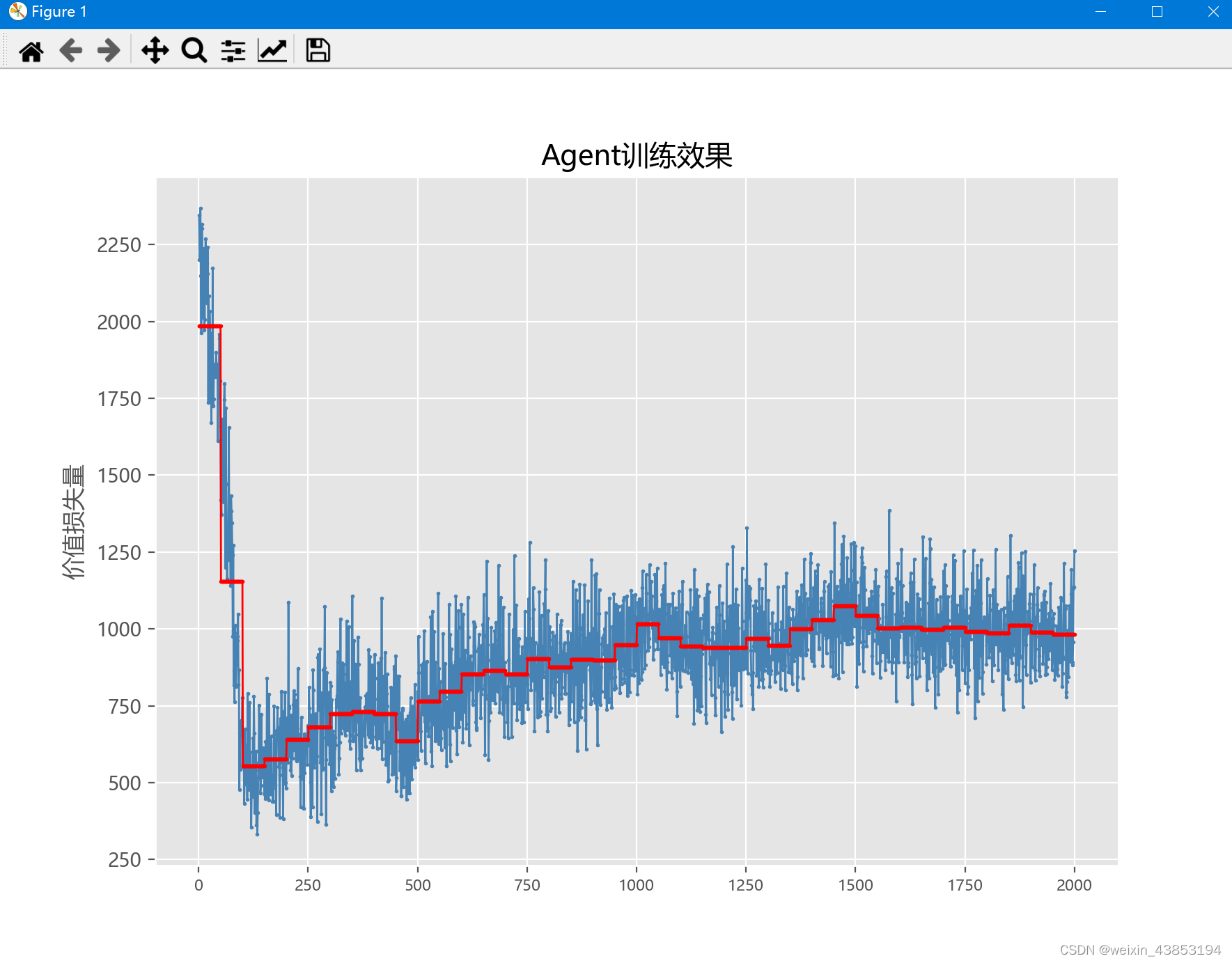
图A3 训练结果
==============================(分割线)=================================

图B1 参数设置和动作选择函数(相比图A1,A2,参数设置不变,但是目标选择函数中:以1-ε的概率选择随机值)
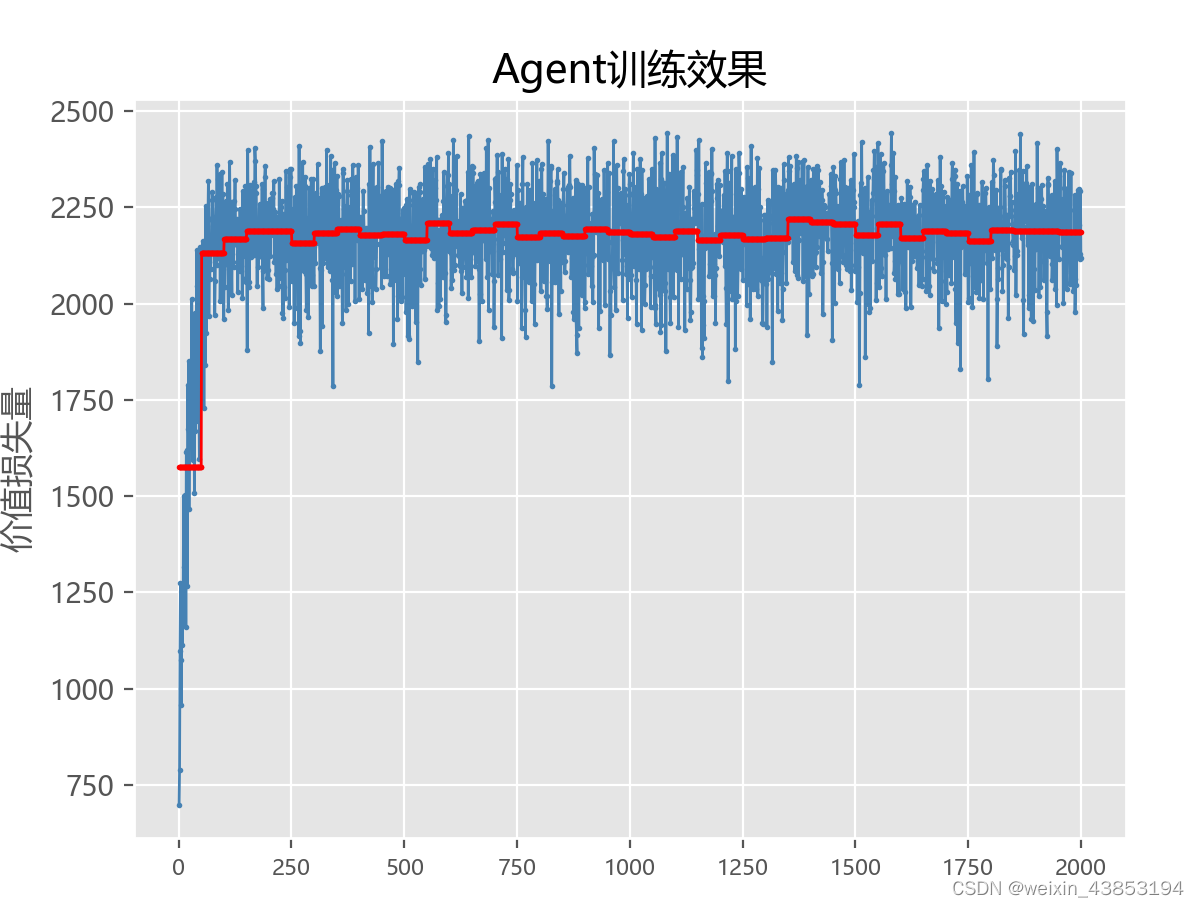
图B2 训练结果
原则上说,一开始让智能体选择较多的随机动作,越后期,随机动作越小,这样的训练效果最好,但为什么在我的实验中,是相反的?
最后
以上就是光亮毛巾最近收集整理的关于代码实现DQN的ε-greedy(Epsilon贪婪策略),取得相反结果的全部内容,更多相关代码实现DQN内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复