Reinforcement Learning学习笔记
Lecture 1
笔记基于David Silver 的上课内容及PPT。
视频地址(B站中文字幕):https://www.bilibili.com/video/av9831889。
PPT地址:http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching_files/intro_RL.pdf
About Reinforcement Learning
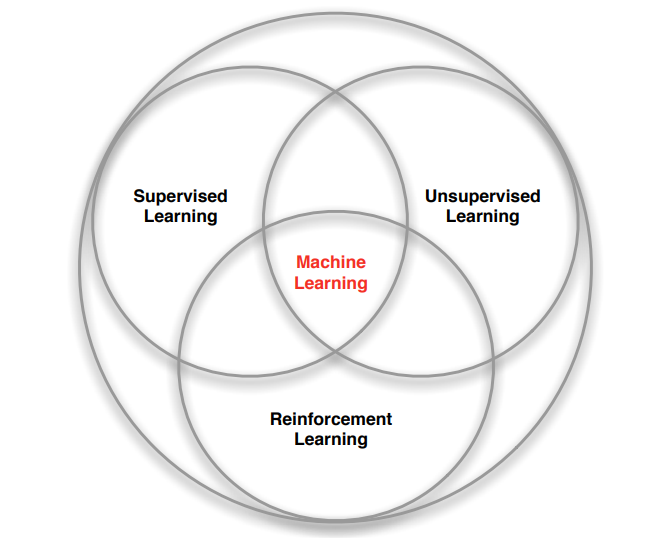
强化学习是机器学习的一种,与有监督学习和无监督学习有明显的差别。监督学习是使用已知正确答案的示例来训练网络,使用的是有标签的数据。有监督的学习是从一个已经标记的训练集中进行学习,训练集中每一个样本的特征可以视为是对该situation的描述,而其label可以视为是应该执行的正确的action,但是有监督的学习不能学习交互的情景,因为在交互的问题中获得期望行为的样例是非常不实际的,agent只能从自己的经历(experience)中进行学习,而experience中采取的行为并一定是最优的。无监督学习适用于具有数据集但无标签的情况,例如聚类分析等等。
强化学习的特点是:
1. 没有监督者,只有一个reward反馈。
2. 反馈不是实时的,具有延迟性。
3. 时间或者说序列很重要。
4. Agent选择的action影响它接下来收到的数据。
适用于强化学习的一些环境:
直升机操控、玩Atari游戏、人形机器人行走、炒股等等。
The Reinforcement Learning Problem
RL问题中的一些定义。
Rewards
一个reward
R
t
R_t
Rt是一个标量反馈信号,反馈的是agent做的工作好不好,agent的目标就是使累积的rewards达到最大。强化学习是基于以下假设进行的:所有的目标都可以被描述为累计奖励期望的最大值。All goals can be described by the maximisation of expected cumulative reward。
rewards的一些实例:
1、在飞机的模拟飞行中,+ve reward代表符合期望的运动轨迹,-ve reward代表撞击。
2、在Atari游戏中,+/-ve reward分别代表赢或者输掉一场游戏。
3、炒股中,+ve reward代表赚钱盈利。
套进框架,一个强化学习的问题可以看作是一个连续决策的问题,这个问题的目标是选择合适的action使未来的总的奖励达到最大。可能需要很长的序列才能得到我们想要的结果,而奖励是可能延迟的,所以不要执着于眼前最大的奖励,不要太贪心,要有为了未来更大的奖励牺牲及时利益的想法。
Environment
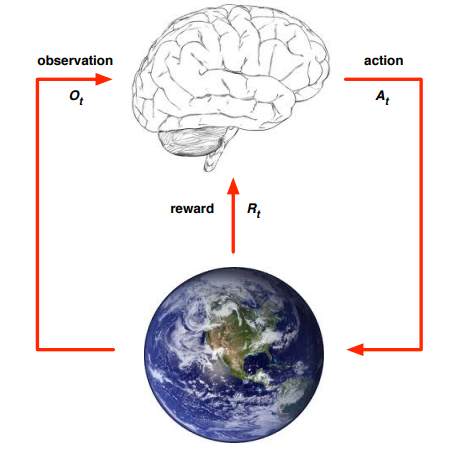
图中大脑代表agent,地球代表环境environment。从图中可以看出,agent在时刻T与environment之间有一个交互,agent决定执行action
A
t
A_t
At,之后环境发生变化,返回给agent一个变化后的Ot+1和一个奖励Rt+1,agent根据接收到的信息决定下一步执行的At+1。
State
记录关于Observation、Reward、Action的序列,Ht= O1, R1, A1, …, At-1, Ot, Rt,根据这个历史序列,agent选择合适的action,environment返回reward和observation。但是history通常是很长很大的一个序列,所以在强化学习中不使用history而使用State。State是关于history中的一个总结,用于决定接下来发生什么的信息,可以表示为
S
t
S_t
St = f(
H
t
H_t
Ht)。环境状态state取决于history,决定经过action后,environment将会发生的变化和返回给agent的奖励reward,并且这些信息对agent并不全是可见的,agent只需要关注收到的observation和reward。代理状态收集history中的信息并对下一步实施的action进行决策。那么对信息状态或者称作马尔科夫状态下一个定义,就是包含了所有从history得到的信息。

关于这个定义,我的理解是一个状态符合马尔科夫性质当且仅当现在这个状态只与前一个状态有关,与更前面的状态无关。一旦时刻t时的状态已知,那么t时刻之前的history都可以被丢弃,每一个state都已经吸收了之前的所有信息。环境状态和history都是Markov。最好的情况就是agent state和environment state是等价的,即Full observability:agent可以观测到环境的state,执行完action后,environment直接返回state,这时候可以将强化学习问题表示为马尔科夫决策过程,即Markov Decision Process(MDP)。除此之外还有Partial observability: agent indirectly observes environment,可以转化为POMDP问题。
Inside An RL Agent
一个RL agent包含下面几个重要组件:
Policy
policy代表的是agent的行为,是一个由state到action的映射。Deterministic policy: a = π(s),这种policy中每个状态对应的行为都是确定的。Stochastic policy: π(a|s) = P[At = a|St = s],这种policy中每个state对应的action是有一定概率分布的,有多种选择。
Value Function
value function是对未来奖励的预测,用来评估当前状态的好坏。可以定义value function为:
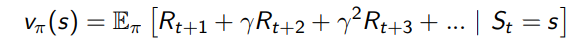
其中的折现因子γ是为了能够降低很长时间后的奖励对现在的影响,说明更注重现在的所得利益。
Model
model用来预测环境将会发生的变化,是agent视角中的环境表示。一般情况下包含两部分,transition model P 用来预测下一个状态,reward model R 用来预测下一步得到的奖励。
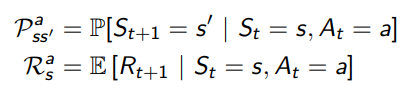
Categorizing RL agents
分类方式1:
-Value Based:learn value function & implicit policy
agent通过value function来挑选下一步的行为而policy是不明确的。
-Policy Based:no value function & learn policy
不去表示agent的内部,不计算value ,每一步都是根据policy来决定下一步的行为,存储的也是policy。
-Actor Critic:learn value function & learn policy
将两者进行结合从而得到最大的奖励。
分类方式2:
- Model Free:Policy and/or Value Function & No Model
不需要知道环境是如何动态改变的
- Model Based:Policy and/or Value Function & Model
需要建立model来表示环境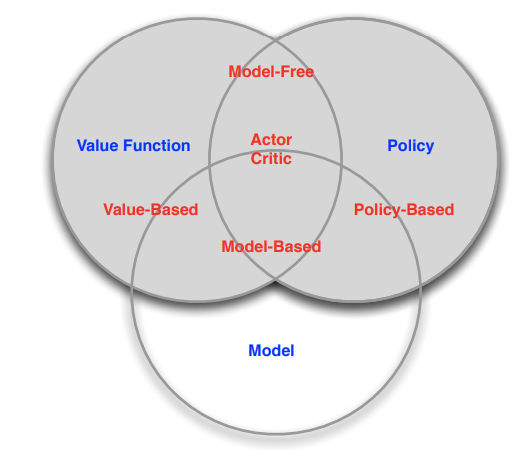
Problems within RL
1. Learning and Planning
在连续决策问题中,有两种不同的问题。一个是learning,对于agent来说,环境是未知的,agent需要不断的与环境进行交互然后进行学习,从而得到合适的policy,从而获取最优奖励。另一种是planning,规划,在这种问题下,环境是已知的,agent不需要与环境进行交互,只需要根据公式等进行内部的计算,从而改善policy。
2. Exploration and Exploitation
RL是一个试错学习,我们需要不断的与环境交互并且辨别其中好与不好的地方,在学习的时候,agent要规划一条最优路线从而获得最大奖励。exploration,搜索是有选择的抛弃一些奖励,去更大限度的了解这个环境。exploitation,开发是最大限度的利用已知的环境和信息来获得最优奖励,但是可能会放弃掉未知的最大奖励。
3. Prediction and Control
prediction,预测是指给定一个policy,我可以计算根据这个policy的指示,我可以获得多少奖励。control是寻找一个最优的policy,RL需要先解决预测问题,然后对所有的policy进行评估从而选取最优policy。
最后
以上就是勤劳高跟鞋最近收集整理的关于强化学习笔记一 -- 简介 Reinforcement Learning学习笔记 Lecture 1About Reinforcement LearningThe Reinforcement Learning ProblemInside An RL AgentProblems within RL的全部内容,更多相关强化学习笔记一内容请搜索靠谱客的其他文章。








发表评论 取消回复