1.Embedding
Embedding层可将一个整数转化成特定维数的向量。
1.1 导入方式
from keras.layers import Embedding
1.2 实验
1.2.1 导包
from keras.models import Sequential
from keras.layers import Embedding
import numpy as np
1.2.2 设置Embedding参数
1) 经常需要设置输入的维度,比如说文本处理时,规定输入单词的数量;又如使用ANN做分类预测时,规定输入的特征数量。可以在参数input_length中设置。
2)由于Embedding层将一个整数转化成特定维数的向量,在keras中需要规定整数的范围,这个可以在input_dim中设置,输入的数据元素取值在[0,input_dim)之间。
3)输出是一个特定维数的向量,可以在output_dim中设置维数。
这里先讲这三个参数。
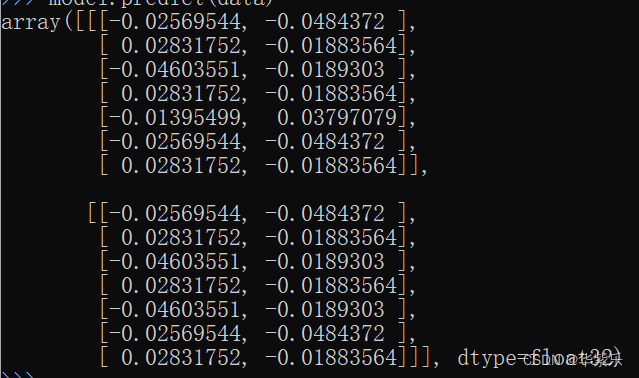
代码如下,在这里,我希望输入向量的维度为7,向量的元素不超过4,输出一个二维向量(将每个元素输出为一个二维向量):
model = Sequential()
model.add(Embedding(4,2,input_length = 7))
接下来准备数据做做实验。
data = np.array([[0,1,2,1,3,0,1],[0,1,2,1,2,0,1]])
model.predict(data)
输出:
2.BatchNormalization
对数据进行批量归一化,数据分布转化成标准正态分布。
3.Flatten
将一批数据多维向量变成一维。
3.1 导包
from keras.layers import Flatten
3.2 实验
# 准备数据
data = np.array([[[0,1,2,3,],[1,3,0,1]],[[0,1,2,1],[3,2,0,1]]])
data.shape

b = flatten(data)
b
实验结果:

3.2.2 对比numpy数组的flatten
b = data.flatten()
b
实验结果

4 Dense
4.1 导包方式
from keras.layers import Dense
4.2 Dense的参数设置
Dense层的help文档如下所示:
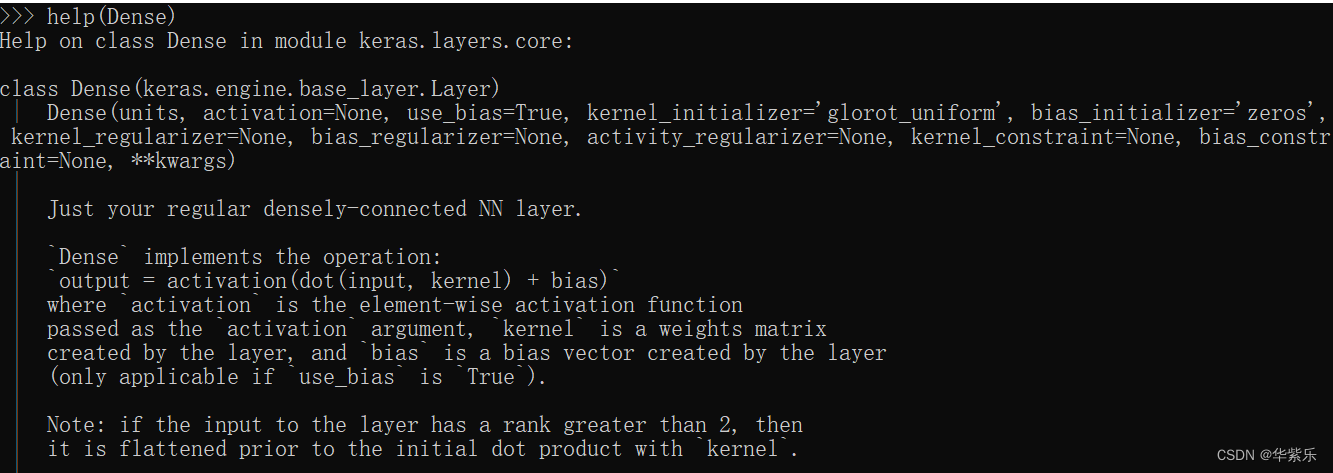
常用的参数有:
1)unit:指经过Dense层输出的单元数;
2)activation:激活函数
…
还有一个有时必要的参数是input_shape。如果Dense层是第一层,那就需要input_shape,即输入数据集的维度;如果Dense层不是第一层,比如使用Sequential建立模型,某一层的Dense层建立在前面的Dense层的基础之上,这时,input_shape可以不填。
另外,笔者还关注了一下kernel_intializer中的’glorot_uniform’的含义。glorot_uniform是默认的权重初始化参数,它从
[
−
l
i
m
i
t
,
l
i
m
i
t
]
[-limit, limit]
[−limit,limit]中的均匀分布中抽取样本,其中
l
i
m
i
t
limit
limit的计算如下:
l
i
m
i
t
=
s
q
r
t
(
6
/
(
f
a
n
i
n
+
f
a
n
o
u
t
)
limit = sqrt(6/({fan_{in} + fan_{out}})
limit=sqrt(6/(fanin+fanout),
f
a
n
i
n
fan_{in}
fanin是权值张量中的输入神经元的数量,
f
a
n
o
u
t
fan_{out}
fanout是权重张量的输出神经元的数量。
4.3 实验尝试
简单做了两组实验,可见未经训练,权重是不同的。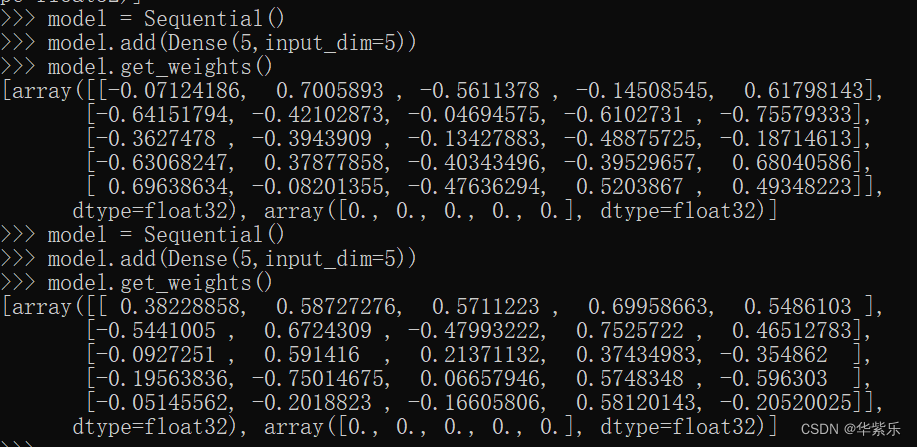
最后
以上就是失眠戒指最近收集整理的关于Keras深度学习函数实验及用法总结(持续更新ing)的全部内容,更多相关Keras深度学习函数实验及用法总结(持续更新ing)内容请搜索靠谱客的其他文章。








发表评论 取消回复