from keras.datasets import mnist我们用mnist为例,
MNIST手写数字数据库有60000个示例的训练集和10000个示例的测试集。数字已被规格化,并在固定大小的图像中居中。
它是一个很好的数据库,供那些想尝试在实际数据上学习技术和模式识别方法,同时在预处理和格式化方面花费最少精力的人使用。
此网站提供四个文件:
train-images-idx3-ubyte.gz:训练集图像(9912422字节)
train-labels-idx1-ubyte.gz:训练集标签(28881字节)
t10k-images-idx3-ubyte.gz:测试集图像(1648877字节)
t10k-labels-idx1-ubyte.gz:测试集标签(4542字节)
我们使用程序
(x_train,y_train),(x_test,y_test) = mnist.load_data()为了查看内容,我们打印一下:
print(x_train.shape)
print(y_train.shape)
print(x_test.shape)
print(y_test.shape)打印结果为:
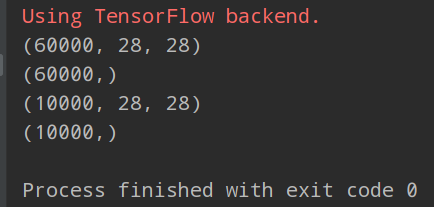
这充分说明了该数据是由28*28像素的图像构成,训练集有60000个,测试集有10000个。
其存放路径为
C:Users用户名.kerasdatasets
注意该文件是隐藏文件。
最后
以上就是高贵电脑最近收集整理的关于机器学习之 Keras默认数据集/模型存放位置的全部内容,更多相关机器学习之内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复