
笔者作为一个从业5年多的技术人员,吃到了深度学习的早期红利,这次来聊一聊深度学习的崛起背景、当下的典型应用领域,算作给尚未或者正打算拥抱这门技术的朋友们一个较为全面的科普。
深度学习为什么能够崛起
一架飞机要成功在天上飞行,离不开3大要素,优良的结构设计,强劲的发动机,足够的燃料。对于深度学习来说,要成功也需要满足这3个前提条件,即先进的算法模型,强劲的计算资源,足够的学习数据。

深度学习的成功不是一蹴而就,正是这三个条件长时间积累后的集中爆发,换一种更具体的说法就是大数据时代的来临,GPU的发展,神经网络相关工程理论的改进。
大数据时代的来临
人类的文明历史,经过了从结绳记事,文字记事,到如今的图片,视频记事的发展历史,正所谓一图胜千言。

在文字被发明之前,人类文明其实没有多少记录,比如我们对夏朝及其以前的历史其实就不太熟悉。而商朝时古人发明了甲骨文,于是文明通过文字的形式传承下来。不过在纸张被发明之前,记录下的信息并不多。古人形容一个人有学识,要用学富五车来形容,这个五车就是实实在在的信息的度量方式,因为当时的文字存在于竹简上。后面纸张被发明,记录文字的效率才得到提升。
随着现代文明的中心转移到了西方,1826年前后法国科学家Joseph Nicéphore Niépce发明第一张可以永久记录的模拟照片,美国发明家爱迪生则在1877年前后发明了留声机。在第一次世界大战后的两年,数字图像也被发明了,被用于新闻行业,从此人类记录的信息变得更加丰富。
1969年因特网的前身ARPANET被发明,随着计算机技术的迭代更新,我们开始逐渐进入互联网信息时代,数据的形式开始变得更加高维和复杂,以网页为代表的数据形式,同时包括了文本、图像、语音、超链接等信息。
根据2012年的畅销书《大数据时代》的统计结果:2000年的时候, 数字存储信息只占全球数据量的四分之一;另外四分之三的信息都存储在报纸、 胶片、黑胶唱片和盒式磁带这类传统的媒介上,这个时期个人依旧是被动式的接收中心节点整理好的信息,数据量有限,更新频率低。

但时间到了2007年, 所有数据中只有7%是存储在报纸、 书籍、 图片等媒介上的模拟数据, 其余全部是数字数据,个人开始主动创造数据并传送到中心节点,数据量庞大,更新频率高。
我们打开APP,拍照上传,发帖评论,浏览网页,播放视频,点击广告,搜索信息,收藏购买,在线支付,即时通信,点赞转发,心跳血压,每时每刻都在制造数据。

本图来自清华大学-大数据应用人才培养系列教材
当时互联网每天产生的全部内容可以刻满6.4亿张DVD,全球每秒发送290万封电子邮件,一分钟读一篇的话,足够一个人昼夜不停地读5.5年。

基于此,杰姆·格雷(Jim Gray)提出数据领域的“新摩尔定律”,即人类有史以来的数据总量,每过18个月就会翻一番。
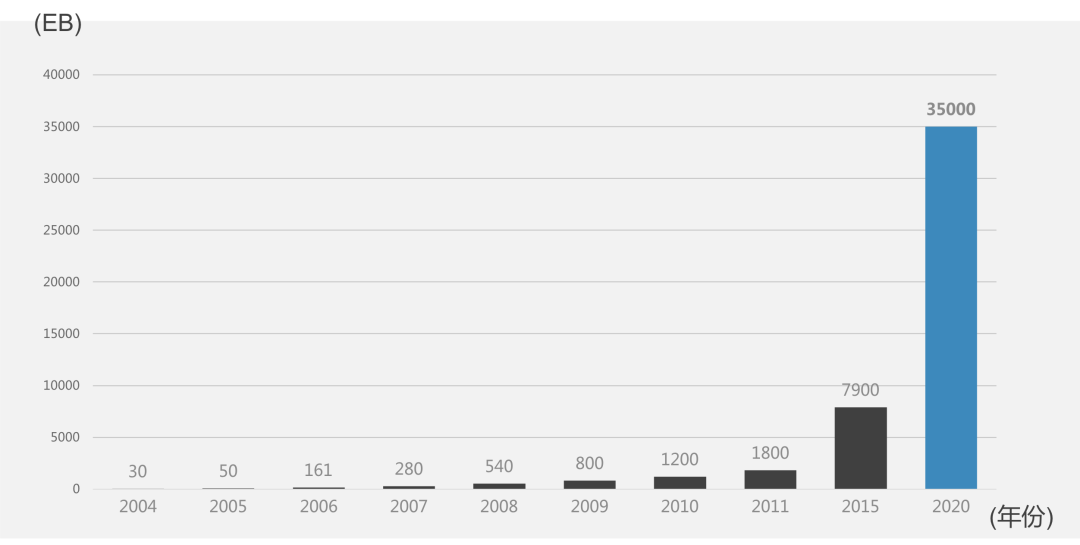
自此我们进入了大数据时代,大数据时代的特点在于,我们处理问题的思维方式发生了变化,我们习惯从数据中进行统计学习,从追求因果关系到追求相关关系。
大数据时代对我们生活的改变是深远的,譬如在2012年数以万计的美国人进行模型侧写, 平均凭借一个Facebook用户的68个“赞”,模型就能够估计出他们的肤色(准确率为95%)、性取向(准确率为88%)和党派(民主党或共和党,准确率为85%)。基于此,Cambridge Analytica公司使用大数据挖掘和心理侧写(Psychological profiling)等技术手段,采取不同的传媒策略(主要是社交媒体上的精准投放),在2016年帮助英国脱欧公投阵营赢得脱欧公投、在美国大选中操纵选情帮助特朗普总统赢得大选。

研究人员有了更多的数据,就可以开始解决更加复杂的问题。以计算机视觉任务为例,1998年发布的手写数字识别数据集MNIST,共60000图片,10个类别,2009年发布的ImageNet数据集,共1400多万图片,2万多个类别,百万标注框。如果不是大数据时代的积累,我们就没有ImageNet这样的行业基准来推动计算机视觉领域的快速进步。
大数据还催生了新的职业,如数据标注工程师,诞生了许多相关的公司、大数据社区。

没有大数据,不可能有足够的‘养料’喂养出深度学习模型,而深度学习的崛起,正是从2010年左右,我们进入数据快速增长的大数据时期开始。
GPU的发展
现在我们都知道做深度学习任务GPU是必不可少的,其结构和CPU相比有很大不同。
CPU( Central processing unit )需要很强的通用性来处理各种不同的数据类型,同时在大量的逻辑判断中,包含了大量的分支跳转和中断处理,使得CPU的内部结构异常复杂,不擅长于快速计算。
而GPU(Graphic Processing Unit)则专为图像处理设计,采用了数量众多的计算单元(arithmetic and logic unit)和超长的流水线,但只有非常简单的控制逻辑并省去了Cache。
这使得GPU拥有高带宽的独立显存;浮点运算性能高;几何处理能力强;适合处理并行与重复计算任务;适合图像或视频处理任务;

CPU的峰值计算能力=CPU频率×CPU核心数×浮点运算单元数,如i7-8700K的CPU频率=3.7GHZ,核数为6,浮点运算单元数为16,浮点运算能力是3.7*16*6<360 Gflops以下。而TITAN V峰值浮点性能为110 TFlops(1T=1024G),TESLA v100峰值浮点性能为125 TFlops ,因此GPU有超过CPU几个数量级的速度优势。
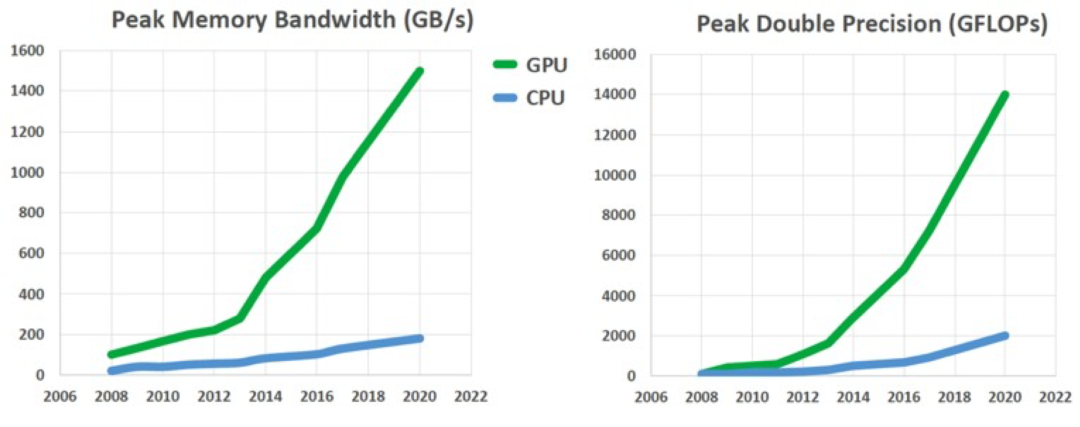
不过GPU也不是一开始就拥有如此强劲的计算能力,简单来说经历了3个时期。
第1时期是固定架构时代( fixed function architecture,1995-2000年)。1999年,NVIDIA推出第一款GPU Geforce256,拥有完整的顶点变换、光照计算、参数设置以及渲染等四种3D计算引擎,每秒处理至少1000万个多边形,极大加快了计算机3D程序运行速度。2000年, NVIDIA推出全球首款针对笔记本的GPU——GeForce2 Go。

第2时期是分离渲染架构时代( separated shader architecture,2001-2005年)。1999年到2002年, NVIDIA推出了业界首款独立的可编程GPU Geforce3,ATI(2006年被AMD收购)推出了Radeon8500。这个时期的GPU用可编程的顶点渲染器(Vertex Shader)替换了变换与光照相关的固定单元,用可编程的像素渲染器(Pixel Shader)替换了纹理采样与混合相关的固定单元,这两部分是实现图形特效最密集的部分, 使用渲染器大大加强了图形处理的灵活性与表现力。两个渲染器呈现流处理器(stream processor)的特点, 不过在物理上是两部分硬件, 不可相互通用。

第3时期是统一渲染架构时代( unified shader architecture,2006年至今)。2006年NVIDIA与ATI分别推出了CUDA(Computer Unified Device Architecture,统一计算架构)编程环境和CTM(Close To the Metal)编程环境,这使GPU通用计算编程的复杂性大幅度降低。这个时代的GPU首次提供几何渲染程序(geometry shader program)功能,并动态调度统一的渲染硬件(unified shader)来执行顶点、几何、像素程序,在体系结构上不再是流水线的形式,而呈现并行机的特征。
2006年,研究人员使用NVIDIA GeForce 7800训练了4层的卷积神经网络,相比CPU的BLAS优化有24%–47%的提升,这也是早期GPU在模型训练中的尝试。
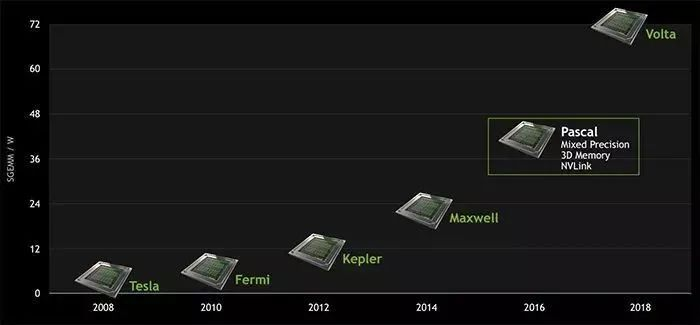
随后NVIDIA的GPU产品线迭代速度明显加快,其设计架构从40nm Fermi、28nm Kepler、28nm Maxwell、16nm Pascal到如今的12nm Volta、Turing,推出了NVIDIA Tesla,GeForce GTX 600,GeForce GTX TITAN, GeForce GTX 980,GeForce GTX 1080,Tegra K1,GeForce GTX TITAN X,Tesla V100,Tesla P100等众多消费者熟知的产品,对于深度学习模型的训练产生了深远的影响。
2009年,Hinton的团队使用Nvidia GTX 280训练2层的Deep Belief Network (DBN) 。
2012年,同样是Hinton的团队使用2个NVIDIA GTX580在ImageNet数据集上训练8层的AlexNet,训练时间为6天,这成为了深度学习在计算机视觉领域中的里程碑事件。
2018年,Facebook团队使用256个NVIDIA Tesla P100在ImageNet数据集上训练ResNet50,训练时间1小时。
2018年,腾讯团队使用 2048个NVIDIA Tesla P40在 ImageNet数据集上训练ResNet-50,训练时间6.6分钟。
2018年,日本索尼的神经网络库NNL,使用3456个NVIDIA Tesla v100,在ImageNet数据集上训练ResNet-50,将其训练时间缩短到了112秒。
正是第三个时期的GPU架构的快速发展,为深度学习模型的训练提供了可能,催生了一代又一代新的更复杂的模型架构的诞生。
神经网络相关工程理论的发展
什么是深度学习,它本质上是一个复杂的非线性变换构成的抽象算法,对数据进行表征学习(representation learning)。
传统机器学习算法的研究流程是:手工特征+机器学习模型。而深度学习算法的研究流程是:从数据中自动学习特征,提高机器学习模型的性能,它们的主要区别在于特征提取这里。
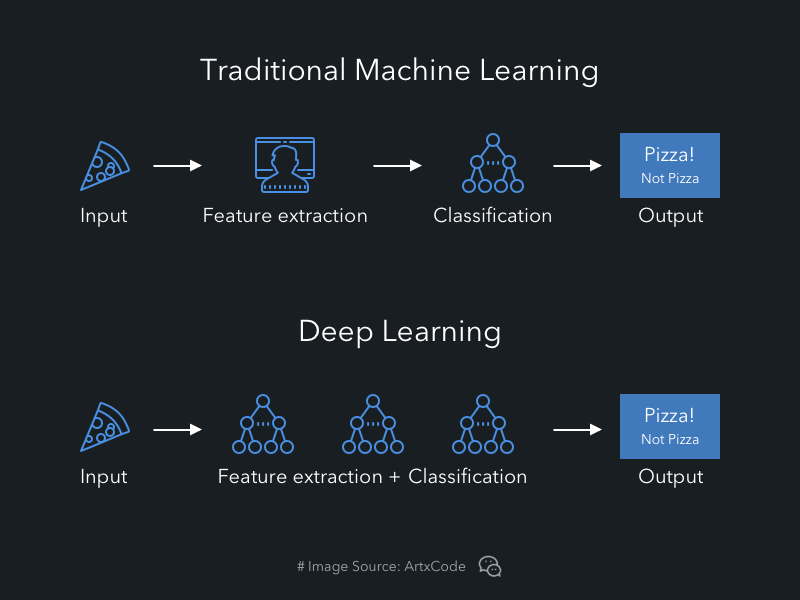
神经网络由于其结构非常适合于逐层进行数据的抽象表达,因此我们平常说深度学习,指的就是深度神经网络,其中“深”表示网络层数深,从传统的几层到成百上千层。
深度学习并不是全新的概念,神经网络在上个世纪中期就已经诞生,其核心优化理论,反向传播算法(Back-Propagation, BP算法)由保罗·韦尔博斯(Paul Werbos)在1974年发明,1986年戴维·鲁梅哈特(David Rumelhart),杰弗里·辛顿(Geoffrey Hinton) 等人将其进行推广完善。

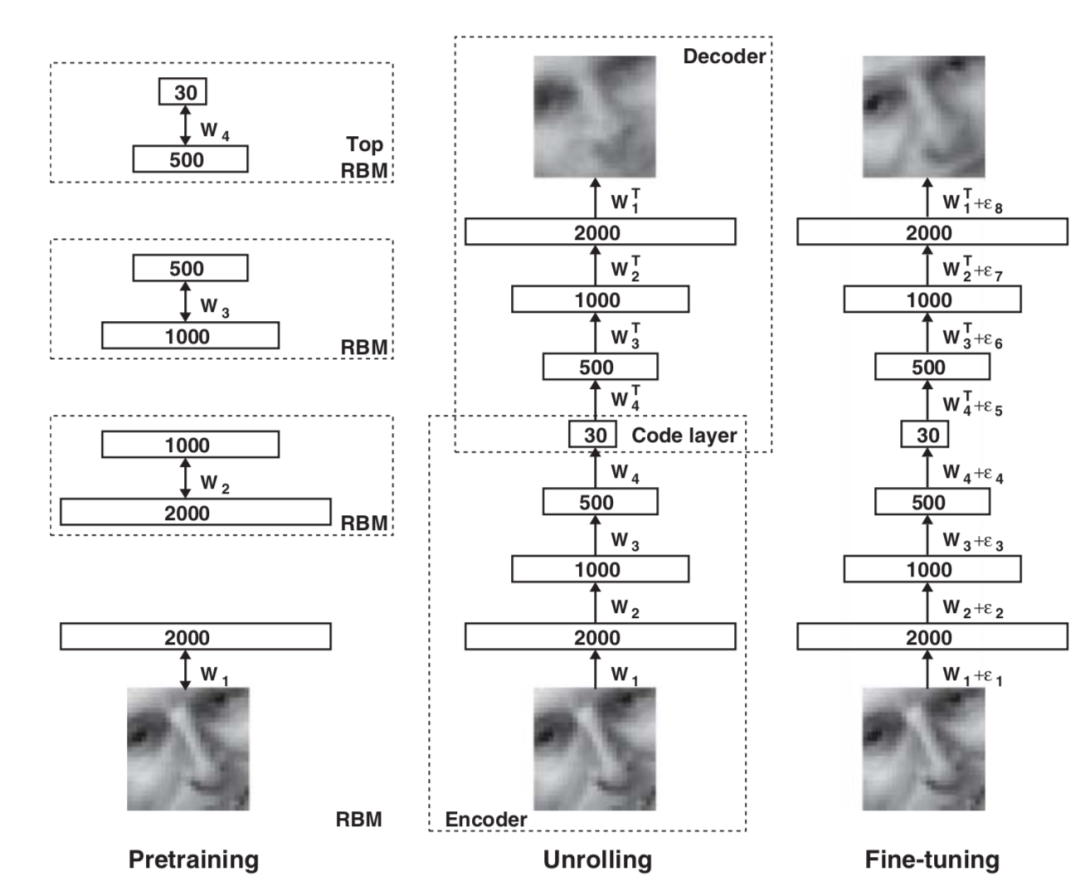
在2006年,Geoffrey Hinton团队发表了两篇经典研究。第一篇是“Learning Multiple Layers of Representation”,提出了不同于以往学习一个分类器的目标,而是希望学习生成模型(generative model)的观点,以期学习到更好的特征表达,摆脱对大量训练数据的依赖,因此早期的深度学习也被称为表示学习。另一篇论文“Reducing the dimensionality of data with neural networks”,则提出了逐层无监督预训练玻尔兹曼机的方式,通过“预训练+微调”有效地解决了深层模型难以训练的问题,这具有非常重要的工程意义。
2011年,Glorot等人提出ReLU激活函数,有效地抑制了深层网络的梯度消失问题,简单而有效。
2012年,Hinton等人提出Dropout技术,有效地抑制了深层网络的过拟合问题。它消除或者减弱了神经元节点间的联合,降低了网络对单个神经元的依赖,从而增强了泛化能力。
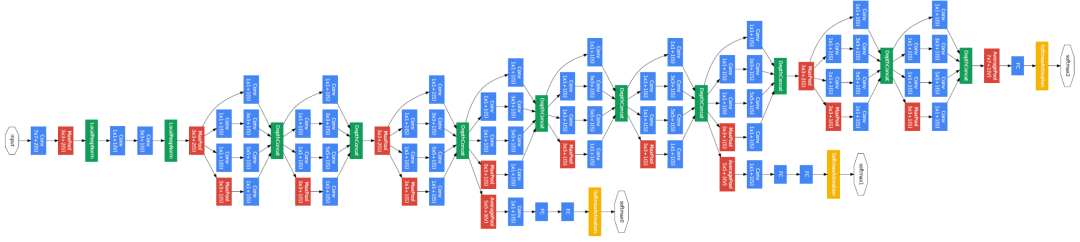
紧接着就是2012年Alex Krizhevsky在论文“ImageNet classification with deep convolutional neural networks”中正式提出了AlexNet网络,包含8个网络层,其中5个卷积层,3个全连接层,以低约10%的错误率,大幅度超过竞争对手,意味着深度学习的黄金时代真正到来了。
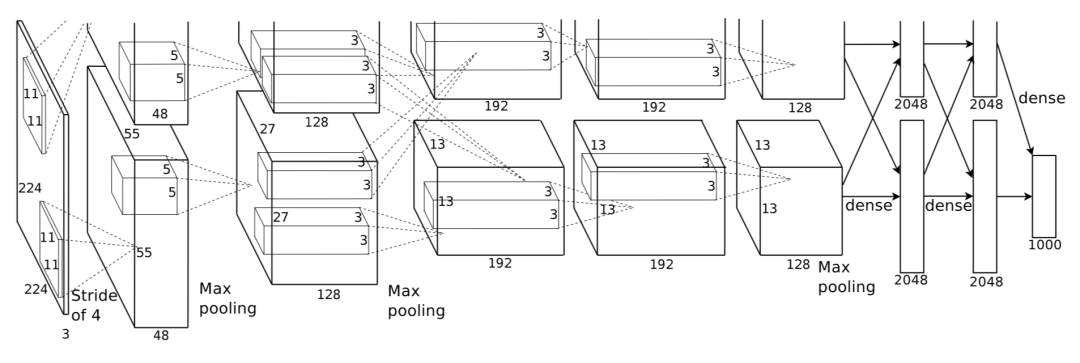
AlexNet模型的成功,就得益于当时最大的数据集ImageNet提供了足够的样本进行学习、当时最大的GPU以训练超过55M的参数量,以及一系列神经网络相关工程技术的使用,包括ReLU激活函数,LRN归一化,Dropout,数据增强,这就是深度学习发展需要的三驾马车。
麻省理工科技评论在2013年评选出十大突破性科学技术,深度学习位居榜首,随后产业界开始重视深度学习。
2010年,斯坦福教授吴恩达( Andrew Ng)会见了Google当时的CEO, 决定开发Google Brain;
2012年,Google的一个由16000台电脑集群组成的人工神经网络通过YouTube上有关于猫的资料自行训练而能够识别出“猫”这一概念;
2012年,华为成立诺亚方舟实验室;
2013年,谷歌聘用了深度学习宗师Geoffrey Hinton;
2013年,百度深度学习研究院( Institute of Deep Learning )建立;
2013年,FaceBook在纽约成立了FAIR(Facebook AI. Research),聘用了Yann LeCun作为首席科学家;
2014年,谷歌以未公布的价格并购了英国DeepMind公司;
由此我们进入了长达将近10年的深度学习发展黄金时期,并且还将继续下去。
深度学习在产业界的应用
从2012年至今已有将近10年的发展,深度学习在各行各业中不断创造商业价值,这里我们从4个大的研究方向来看,即语音处理,计算机视觉,自然语言处理,推荐系统。
语音处理
在传统的研究方法里,语音识别经历了几次重要的技术发展。从20世纪70年代的隐含马尔科夫模型声学建模,20世纪80年代的N元组语言模型,20世纪90年代的隐含马尔科夫模型状态绑定和自适应技术,到21世纪第一个十年的GMM-HMM模型。尽管这些技术取得了不错的进步,但是仍然无法让语音识别达到可商用的地步,直到深度学习的到来,一举让语音识别错误率相比以往最好的方法还下降了30%以上,突破了语音识别技术可以商用的临界点。
在2009年neural information processing systems(NIPS)会议上,邓力和Geoffrey Hinton联合组织了Deep Learning for Speech Recognition and Related Applications workshop。他们首次证明使用新方法训练的深度神经网络在大量语音识别基准上优于之前的方法,并联合发表了论文“Deep Neural Networks for Acoustic Modeling in Speech Recognition”。
2012年Abdel-Hamid等人证实卷积神经网络可以在频率坐标轴上有效归一化说话人的差异,并在TIMIT音素识别任务上讲错误率从20.7%降低到20%。
之后俞栋,邓力以及Geoffrey Hinton等人致力于将深度学习技术广泛引入语音识别中,并撰写了书籍《Deep learning: methods and applications》。

2016年,微软率先实现语音识别系统5.9%的低错误率,在Switchboard对话语音识别任务中已经达到人类对等的水平。
现如今深度学习在语音分类、语音质量评测、语音增强、音频指纹识别、语音检索与唤醒、语音识别、声纹/说话人识别、语音合成与生成中应用非常广泛。
语音分类和音频指纹识别的典型应用即听歌识曲,相信许多朋友都使用它识别过歌曲。
语音检索识别的应用自不用说,智能音箱、语音输入法、同声传译、实时字幕生成,这些都是非常高频的应用,大大便利了我们的日常生活。

语音合成(Text To Speech)技术在智能配音、虚拟主播、有声阅读、地图导航、智能客服等领域中也已经普及,以下展示的就是几个AI语音助手一起演唱歌曲的应用。
点击边框调出视频工具条
而最先进的语音处理技术,当属语音生成,可以从头创作不存在的语音,乐曲,国内外都有非常多优秀的案例。如平安人工智能研究院创作的交响曲《我和我的祖国》,网易研究院创作的歌曲《醒来》,由AI完成词、曲、编、唱这个全链路的工作,大家不妨来收听感受一下。

这些应用的落地,都得益于深度学习技术的进步,使得我们通过语音与世界的交互变得更加便利和智能。
计算机视觉
由于人类接触到的70%以上的信息都是视觉信息,因此计算机视觉是深度学习应用最广泛也是最成熟的领域,研究领域本身就覆盖了图像分类、目标检测、图像分割、目标识别、目标跟踪、图像质量分析、图像降噪与修复、图像增强、图像去模糊、图像超分辨、图像翻译与风格化、图像生成、三维重建、图像编辑等方向……
而应用领域则覆盖了交通行业,安防行业,娱乐创作行业、教育行业、医疗行业、电商零售行业、制造行业、养殖行业等范围。
自2012年AlexNet图像分类网络取得成功后,一系列新的基准模型被提出,使得图像识别领域率先取得商业大规模应用落地,其中最典型的当属Google图片、百度识图等以图搜图的图片检索引擎,可以应用于各类物品检索。

2015年以后,人脸识别算法取得不断突破,如今在日常考勤,金融支付中已经是标准化技术,还可以被应用于犯罪分子抓捕、走失儿童与老人寻找,社会价值巨大。

随着目标检测与识别等技术的成熟,自动驾驶领域中的行人检测 、车辆检测、交通标志检测等感知能力大大提升,推动了自动驾驶商业化落地的进程。

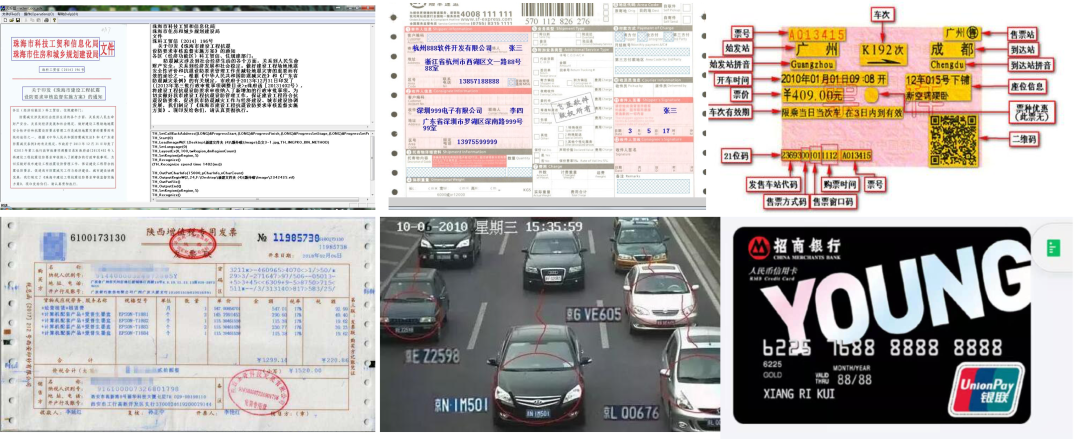
各类场景中的文字与标志识别精度达到了商业化落地水平,在诸如文档识别、身份证识别、车票识别、银行卡识别、车牌识别、发票识别、快递单识别、仪表盘读数识别等方向取得了落地,提高了这些任务的自动化水准。
目标检测算法使得工业制造中的缺陷检测、目标计数也可以变得更加智能,降低人力成本和产品损耗,提高生产效率。

除了识别相关的任务,深度学习在更底层的图像处理任务中也取得了长足的进步,典型的应用包括图像的自动裁剪,图像的自动增强,老照片的修复,图像分辨率的提升,图像的风格化等。

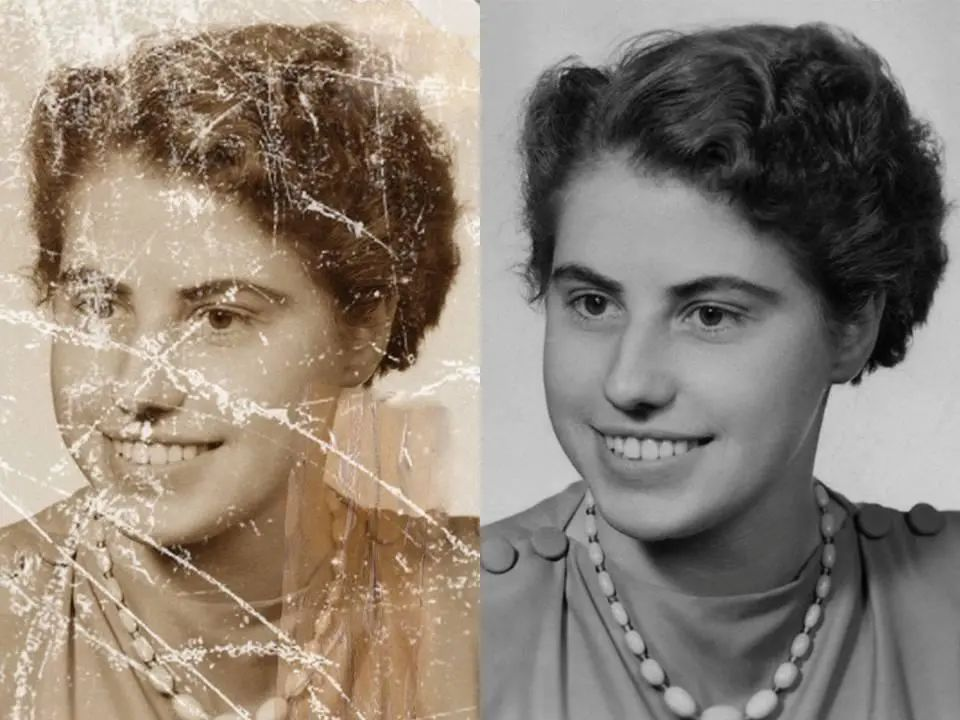

说到视觉里最前沿的技术,当属图像和视频的生成,随着GAN等技术的发展,如今已经可以生成纤毫毕现的图片和视频,达到真假难辨的水平,比如下图分别展示了生成的人脸和换脸的结果。


随着二维图片的处理渐趋成熟,三维的图片处理成为了当下的热门,在表情驱动、人体驱动、姿态编辑、虚拟主播 、关键点定位、虚拟试妆中有着广阔的应用场景。

下面视频中展示的虚拟主播,就应用到了三维人脸重建的技术。
点击边框调出视频工具条
当下我们还处于将图片处理技术迁移到视频中的重要时期,诸如视频分类、行为分析、视频生成与预测、视频检索、光流估计、关键帧提取、视频描述、视频剪辑等都是热门技术,这些都得益于深度学习技术的发展。
自然语言处理
自然语言处理技术被誉为人工智能皇冠上的明珠,自然语言处理的发展可以追溯到上个世纪50年代的图灵测试,经历了从规则到统计,再到现在的深度学习的发展过程。早期基于传统机器学习模型的自然语言处理算法一般都基于浅层模型(如SVM和logistic 回归),这些模型都在非常高维和稀疏的特征(one-hot encoding)上进行训练和学习,会面临着维度爆炸等难以解决的问题。
现如今深度学习在自然语言处理领域也发挥着巨大的价值,典型的研究领域包括文本分类与聚类、文章标签与摘要提取、文本审核与舆情分析、机器翻译、阅读理解、问答系统与聊天机器人、搜索引擎、知识图谱、自然语言生成等方向……
在2003年,Bengio等人在论文《A Neural Probabilistic Language Model》中提出了神经网络语言模型,作为副产品的词向量,掀开了用稠密的多维向量来编码词义的方式。Mikolov等人在2013年做出的研究《Distributed Representations of Words and Phrases and their Compositionality》中真正使得从大规模语料中获得词向量变为现实。
此后,一些基本的方向包括词向量化,分词,词性标注,命名实体识别,文本结构化等研究逐渐成熟。
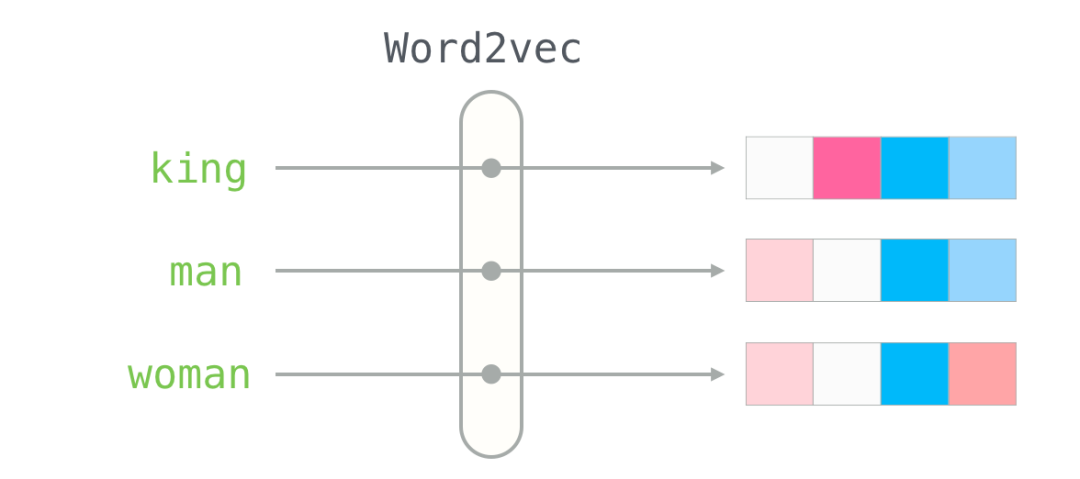
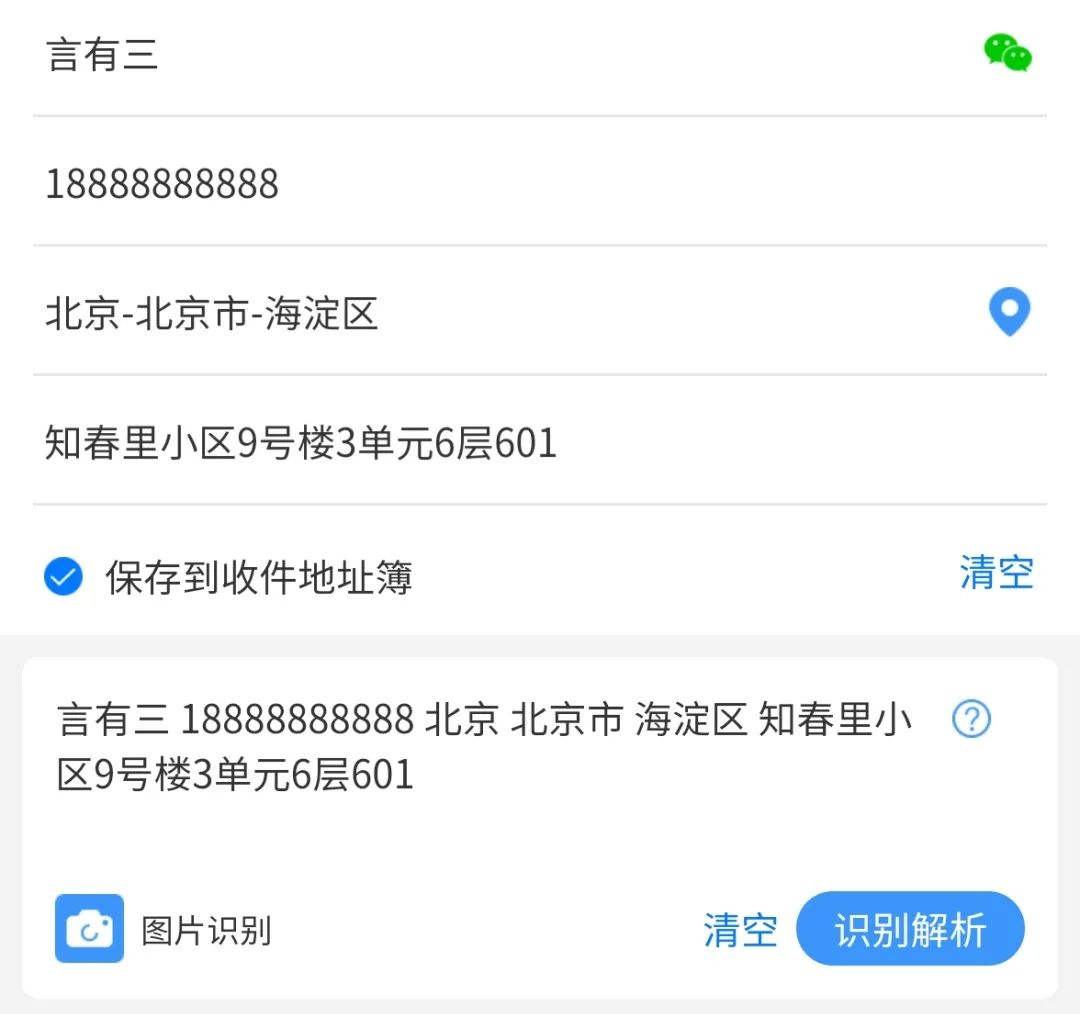
它们可以直接被用于一些基础的文本处理任务,诸如快递地址自动识别与填充,文本文件的分类,文章标签与摘要提取,标题生成等。

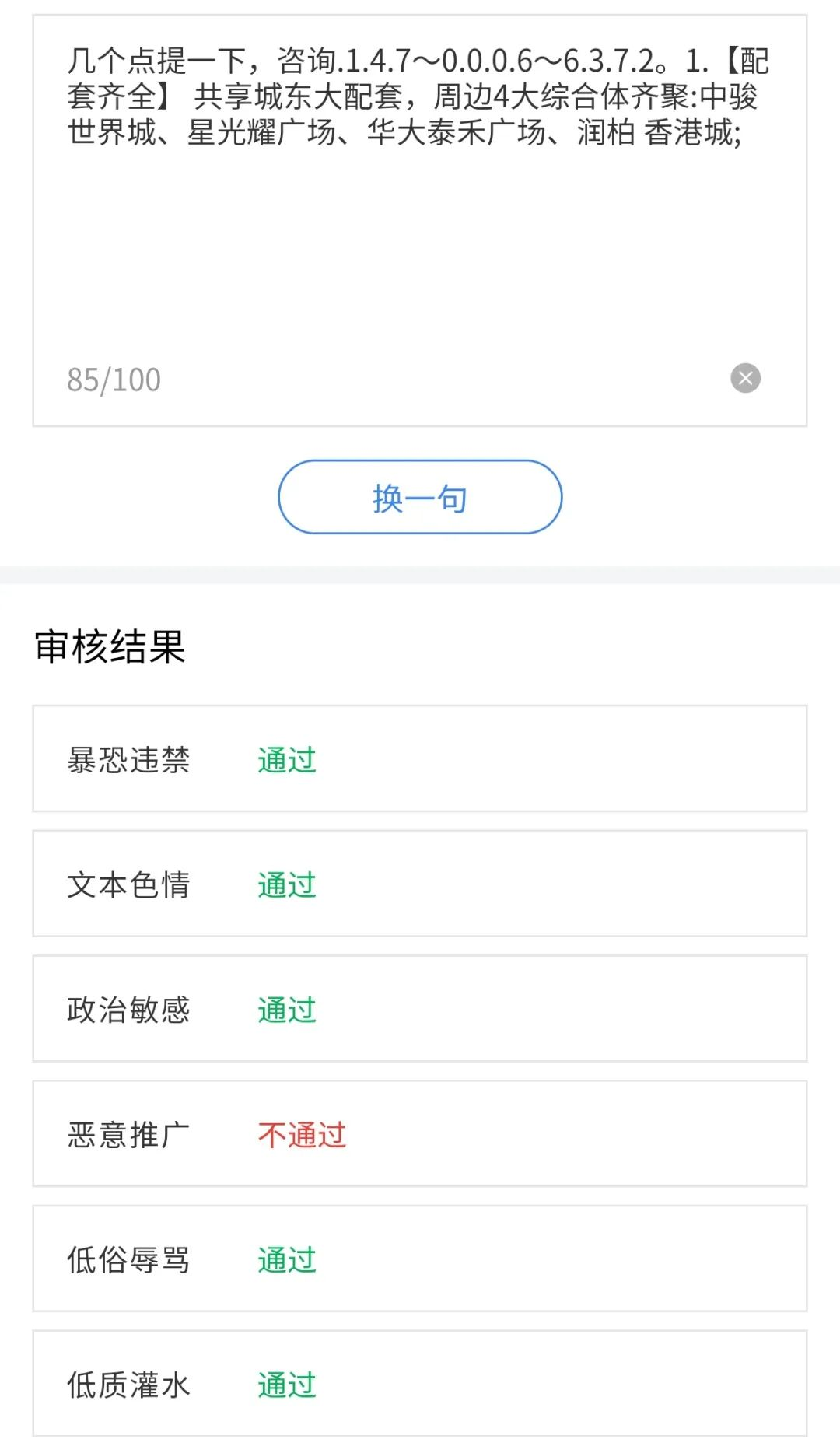
随着互联网文本信息的增加,对文本中夹杂的色情、推广、辱骂、违禁违法等内容的检测有助于维护更健康的网络环境,自然语言处理在其中发挥着重要作用。
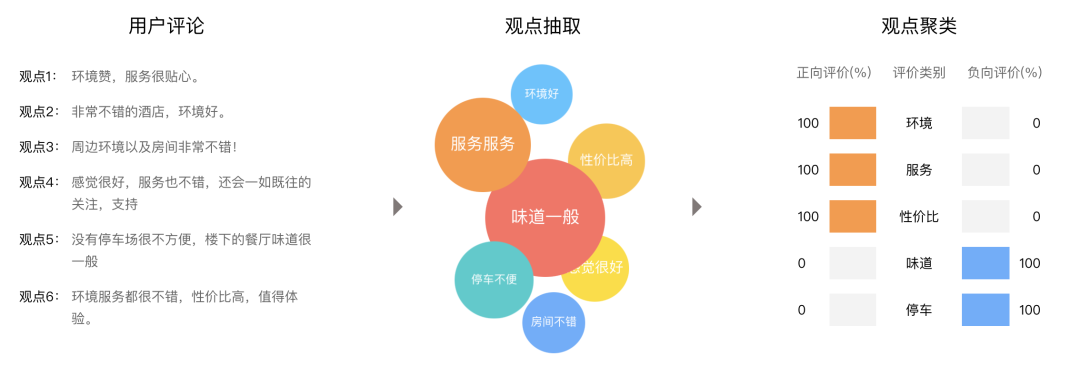
同时,对带有情感色彩的主观性文本进行分析、处理和抽取,也在电影影评分析、商品口碑分析中有着重要作用,有助于提升消费者的使用体验。
作为一个非常具有难度而又商业价值巨大的领域,机器翻译一直是自然语言处理的核心问题,随着深度学习模型的发展,以Google为代表的公司已经开发出了非常强大的机器翻译算法,在各类翻译词典、翻译机、跨语言检索、语音同传应用中大大便利了人们的日常交流。

我们对于以机器人为代表的人工智能技术总是充满着非常高的期望,当下以百度小度为代表的问答机器人,阿里小蜜为代表的客服机器人,微软小冰为代表的聊天机器人,都已经在商业环境中正式上岗。

阅读理解,一向是复杂度非常高的人类推理行为,是深度学习大大推进了当下机器阅读理解的发展,利用算法使计算机理解文章语义并回答相关问题的技术,AI在选择题、问答题、填充题等多项任务中不断取得突破,在某一些领域中甚至超过了人类水平。

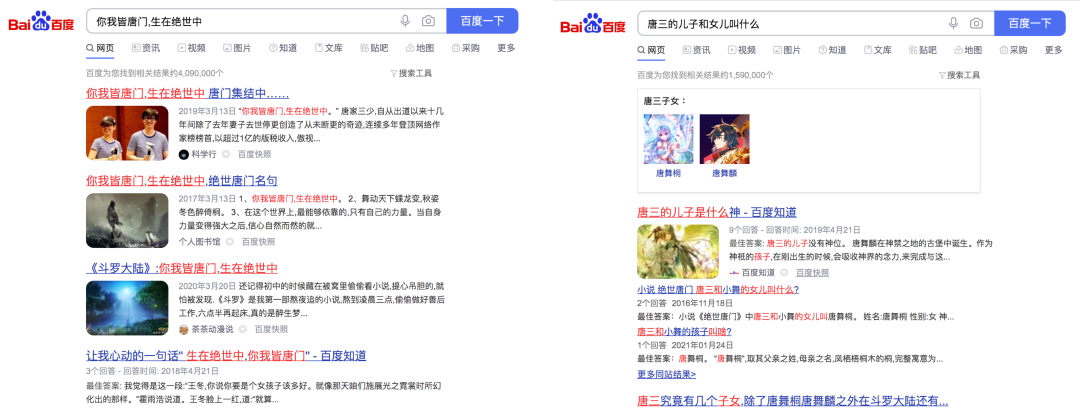
搜索引擎是当下我们获取信息的主要来源,通过自然语言理解技术,我们从基于关键字查询的检索迈入了面向自然语言理解的检索,不仅可以检索匹配关键词相关内容,还可以理解用户意图。当你搜索‘唐三的女儿和儿子叫什么’时,直接给出的是答案,而不是一些相关网页链接。
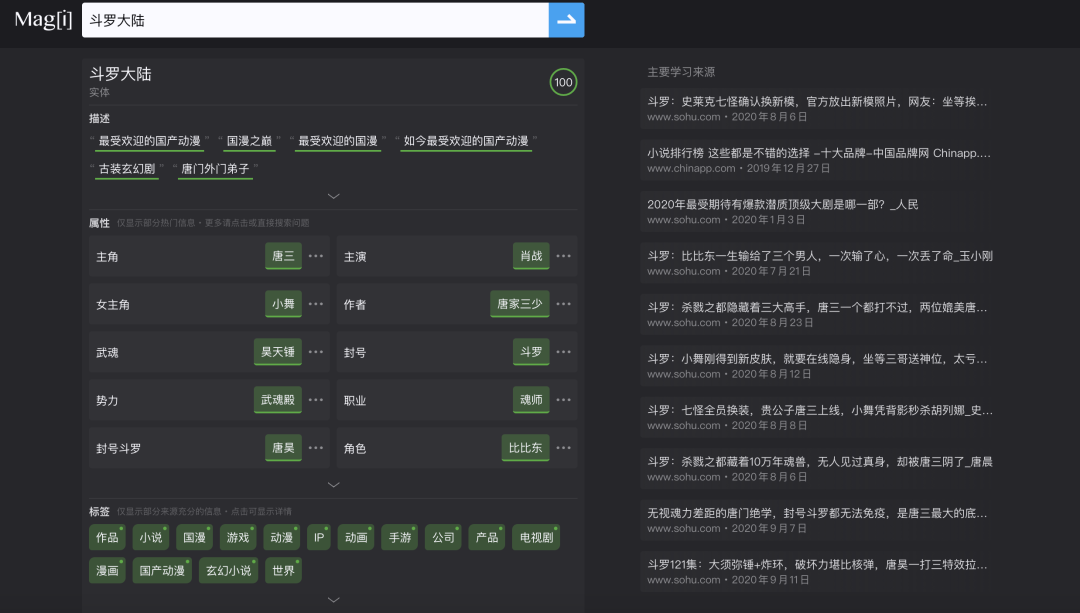
而知识图谱的构建,则让信息的展示变得更加条理清晰,这得益于自然语言处理中的多项关键技术。
当下基于深度学习的自然语言处理的最时髦的研究,莫过于自然语言生成/文本生成技术,不管是写新闻,写对联,还是写诗,都信手拈来。微软小冰甚至创作并且出版了人类历史上第一部100%由人工智能创造的诗集。
“树影压在秋天的报纸上中间隔着一片梦幻的海洋我凝视着一池湖水的天空",这般优美的诗句,都是来自AI的诗意。


在此之前,微软还让小冰在天涯、豆瓣、简书等平台,用27个笔名发表自己的诗歌,读者们还不知道“骆梦”、“风的指尖”、“一荷”、“微笑的白”这些笔名背后的诗人,其实并非人类。
当下自然语言处理已经能够完成较为复杂的任务,如何处理更多艺术和情感相关的任务,也是研究人员在慢慢解决的问题,人类与AI共存的时代,已然降临了。
推荐系统
人类从来没有像今天这样,被推荐系统如此深刻地支配过,仿佛找到了对抗选择强迫症的方法,不再需要自己去思考和搜索,只需要接受系统推荐过来的信息即可。
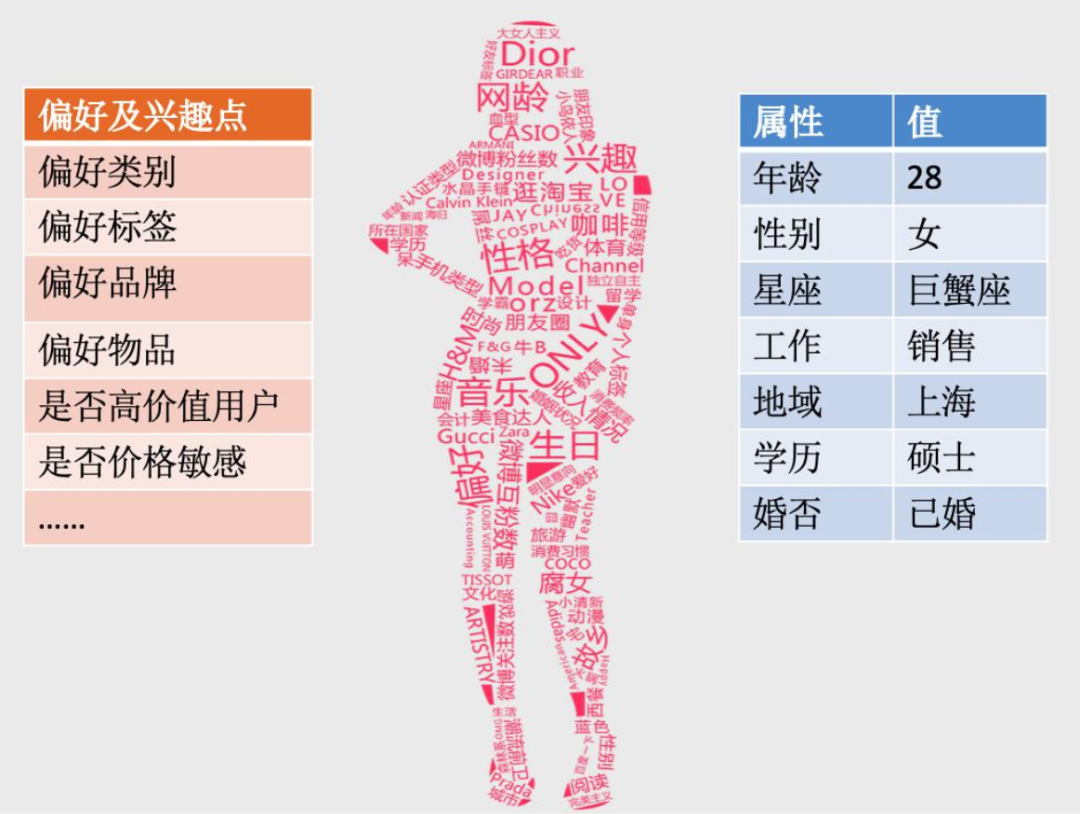
我们在互联网上留下的所有足迹,都被小心地搜集起来,然后被抽象成具体的标签,得到了千人千面的用户画像,被服务商用来推送有针对性的内容,所以你会感叹最懂你的不再是家人或者朋友,而是手机。
从用户角度来看,推荐系统可以帮用户从海量信息中便捷地筛选出感兴趣的内容,在用户面对陌生领域时提供参考意见,满足用户的好奇心。而从系统角度来看,推荐系统可以帮系统筛选出高质量的用户群,提高留存率,提高广告的商业变现率,降低运营成本,提高内容的时效性、多样性,解决长尾信息的阅读问题。
所以你打开头条看到的是你想读的新闻, 打开淘宝看到的是你可能购买的商品,打开微信刷感兴趣的文章和视频,打开微博关注喜欢的博主,推送过来的东西精准又高效,这就是个性化推荐的效果。
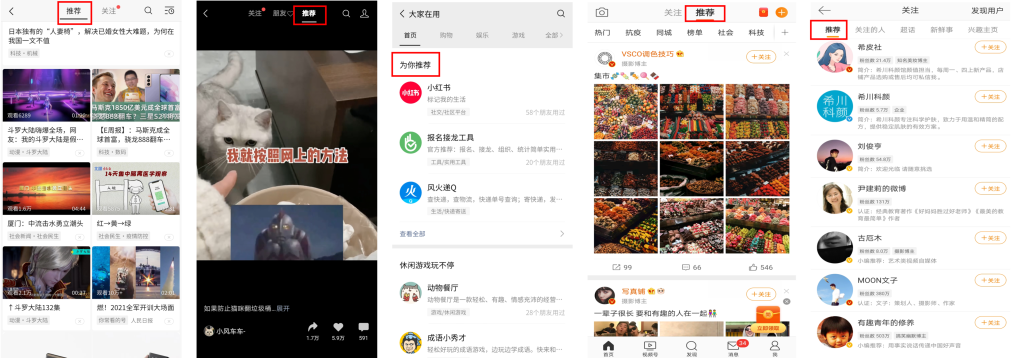
当你刷完一个视频,系统一定会给你再推荐类似的让你欲罢不能的视频,当你买完一件商品,又给你推送想入手的商品,于是真的陷入了‘看了还看’,‘买了又买’的循环,这就是相关推荐的效果。
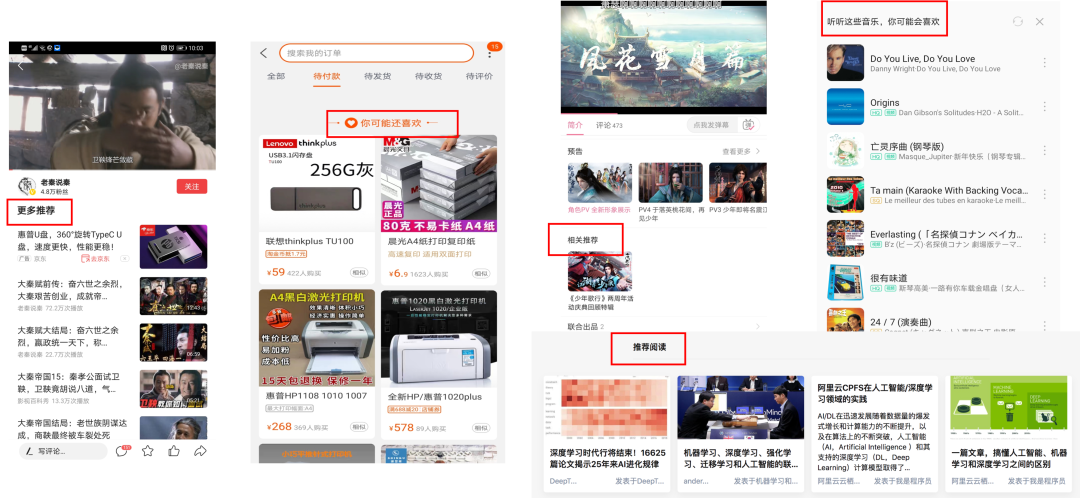
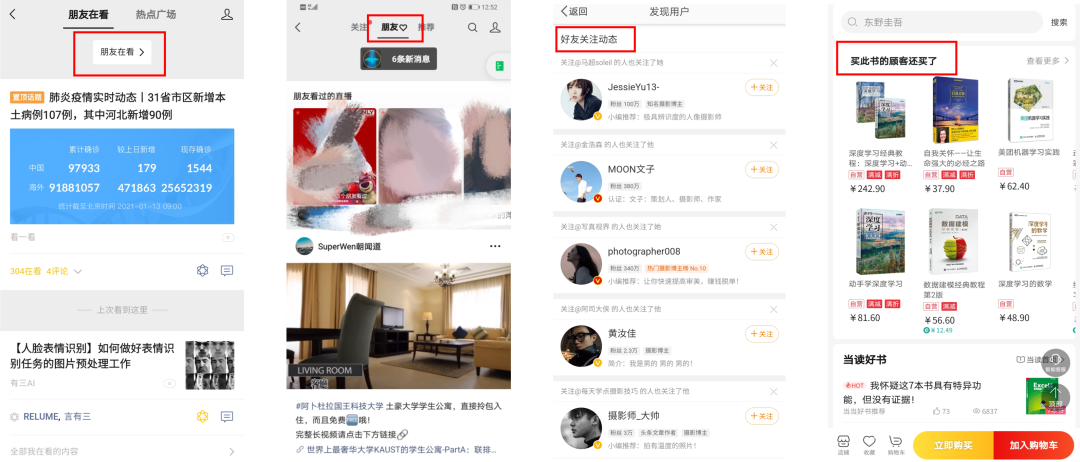
能做到如此高效的推荐系统,背后得益于深度学习模型建模复杂特征,挖掘复杂关系的能力。如今商品推荐、新闻推荐、视频推荐、音乐推荐、美食推荐等已经成为了上网的标配,彻底改变了我们从互联网的信息海洋中获取自己感兴趣信息的方式。
结语
深度学习,并非是近十年诞生的新技术,而更像是新瓶装旧酒,在大数据的爆发,硬件计算能力飞速提升的大背景下,一系列新的工程技术不断被创新,让我们进入了一个更加智能化的时代,不断重组人们的生活和工作方式,创造商业传奇,这是值得当下每一个人关注的技术。
为了帮助大家学习相关内容,有三AI联合阿里云开设了《深度学习》系列课程,本文所介绍的内容都在视频中有更加详细的介绍,欢迎大家持续关注。
课程的具体地址为https://tianchi.aliyun.com/course/279,扫码亦可直达:

没有阿里云账号的,可以参考下文进行配置:
【阿里云课程】有三AI在阿里云天池开设深度学习课程啦,从人工智能基础讲起,零基础都可以来学
【重要】免费GPU+数据代码!有三AI联合阿里天池推出深度学习训练营,任何基础都可以学习
进入了智能时代,不懂深度学习,可能就真的落伍了。


往期相关
【阿里云课程】有三AI在阿里云天池开设深度学习课程啦,从人工智能基础讲起,零基础都可以来学
【阿里云课程】深度学习在语音处理与计算机视觉中的研究方向与典型应用
【阿里云课程】深度学习在自然语言处理与推荐系统中的研究方向与典型应用
【杂谈】2020年如何长期、系统,全面地学习深度学习和计算机视觉,这是有三AI的完整计划
最后
以上就是自然冰棍最近收集整理的关于【杂谈】万字长文回顾深度学习的崛起背景,近10年在各行各业中的典型应用的全部内容,更多相关【杂谈】万字长文回顾深度学习内容请搜索靠谱客的其他文章。








发表评论 取消回复