
上一篇Attention机制详解(一)——Seq2Seq中的Attention回顾了早期Attention机制与RNN结合在机器翻译中的效果,RNN由于其顺序结构训练速度常常受到限制,既然Attention模型本身可以看到全局的信息, 那么一个自然的疑问是我们能不能去掉RNN结构,仅仅依赖于Attention模型呢,这样我们可以使训练并行化,同时拥有全局信息?
这一篇就主要根据谷歌的这篇Attention is All you need论文来回顾一下仅依赖于Attention机制的Transformer架构,并结合Tensor2Tensor源代码进行解释。
直观理解与模型整体结构
先来看一个翻译的例子“I arrived at the bank after crossing the river” 这里面的bank指的是银行还是河岸呢,这就需要我们联系上下文,当我们看到river之后就应该知道这里bank很大概率指的是河岸。在RNN中我们就需要一步步的顺序处理从bank到river的所有词语,而当它们相距较远时RNN的效果常常较差,且由于其顺序性处理效率也较低。Self-Attention则利用了Attention机制,计算每个单词与其他所有单词之间的关联,在这句话里,当翻译bank一词时,river一词就有较高的Attention score。利用这些Attention score就可以得到一个加权的表示,然后再放到一个前馈神经网络中得到新的表示,这一表示很好的考虑到上下文的信息。如下图所示,encoder读入输入数据,利用层层叠加的Self-Attention机制对每一个词得到新的考虑了上下文信息的表征。Decoder也利用类似的Self-Attention机制,但它不仅仅看之前产生的输出的文字,而且还要attend encoder的输出。以上步骤如下动图所示:

Transformer模型的整体结构如下图所示
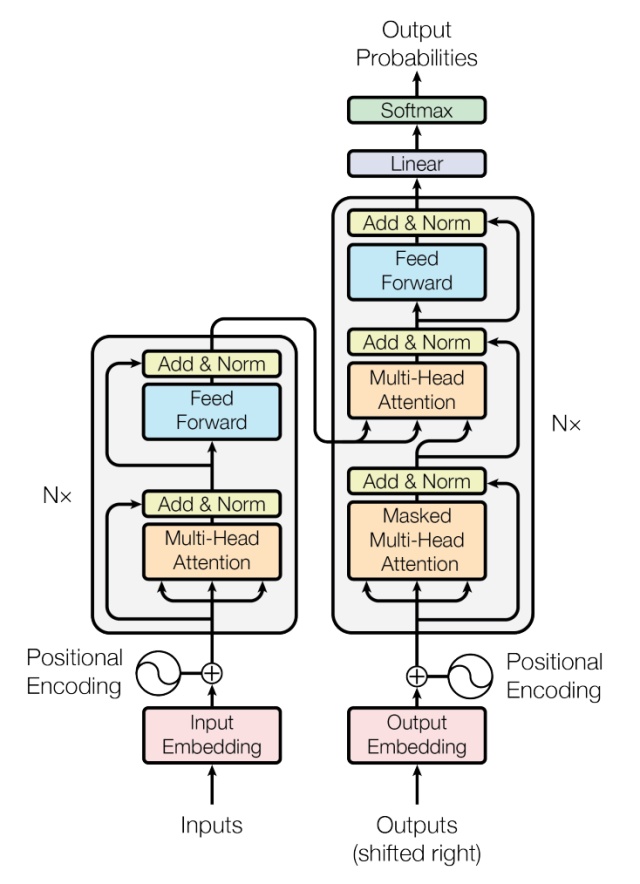
这里面Multi-head Attention其实就是多个Self-Attention结构的结合,每个head学习到在不同表示空间中的特征,如下图所示,两个head学习到的Attention侧重点可能略有不同,这样给了模型更大的容量。
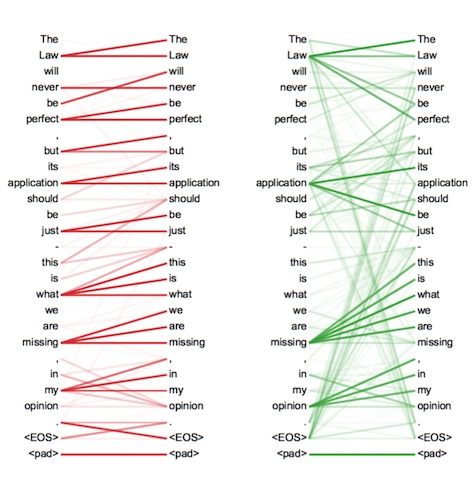
Self-Attention详解
了解了模型大致原理,我们可以详细的看一下究竟Self-Attention结构是怎样的。其基本结构如下
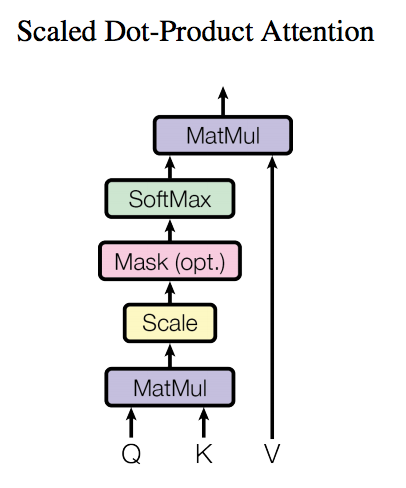
对于self-attention来讲,Q(Query), K(Key), V(Value)三个矩阵均来自同一输入,首先我们要计算Q与K之间的点乘,然后为了防止其结果过大,会除以一个尺度标度
这里可能比较抽象,我们来看一个具体的例子(图片来源于https://jalammar.github.io/illustrated-transformer/,该博客讲解的极其清晰,强烈推荐),假如我们要翻译一个词组Thinking Machines,其中Thinking的输入的embedding vector用
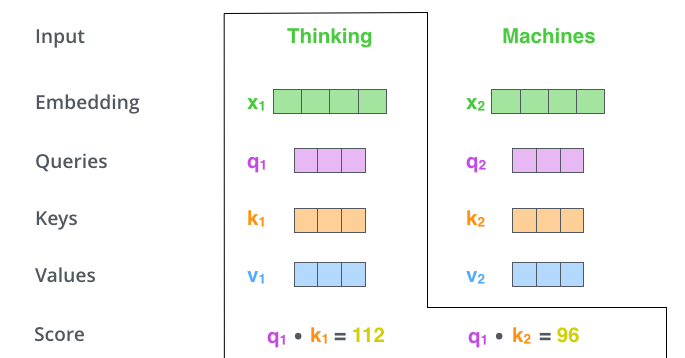
当我们处理Thinking这个词时,我们需要计算句子中所有词与它的Attention Score,这就像将当前词作为搜索的query,去和句子中所有词(包含该词本身)的key去匹配,看看相关度有多高。我们用
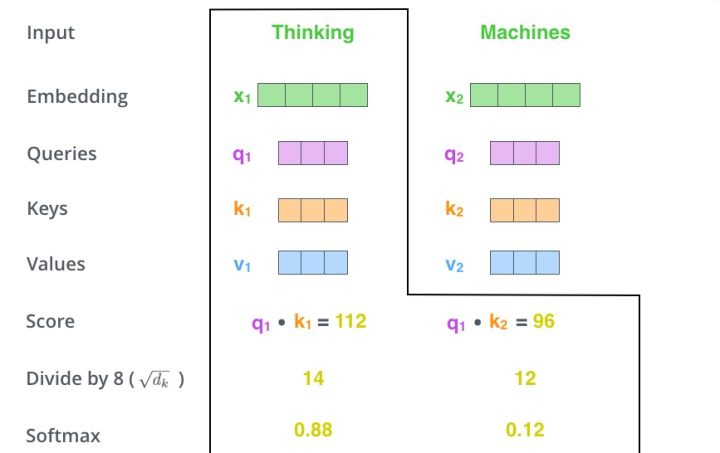
显然,当前单词与其自身的attention score一般最大,其他单词根据与当前单词重要程度有相应的score。然后我们在用这些attention score与value vector相乘,得到加权的向量。
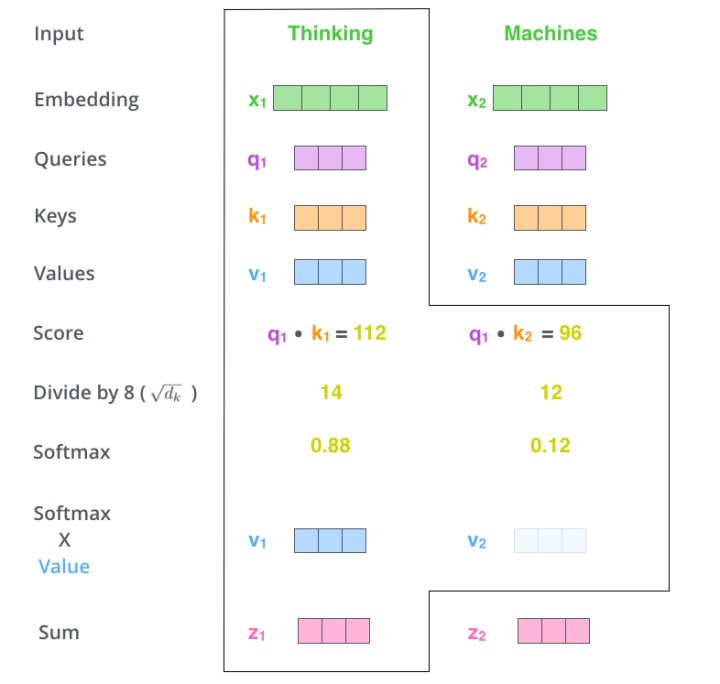
如果将输入的所有向量合并为矩阵形式,则所有query, key, value向量也可以合并为矩阵形式表示
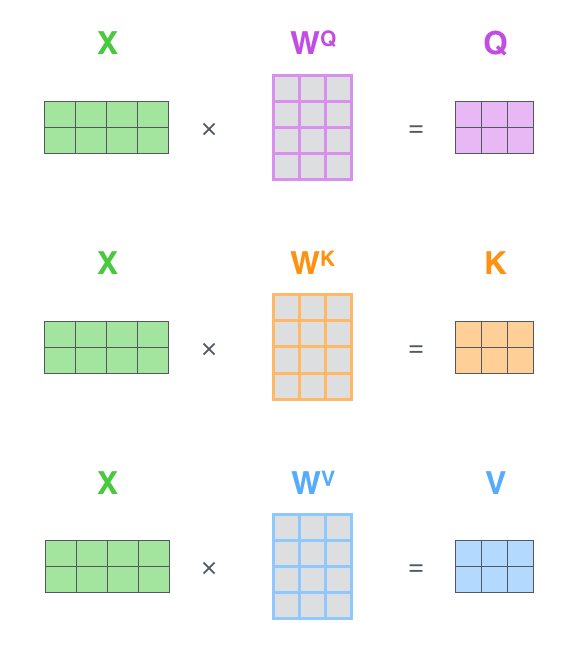
其中
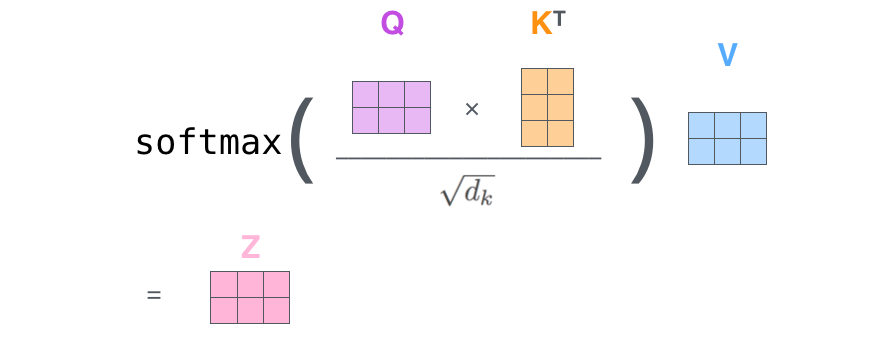
而multihead就是我们可以有不同的Q,K,V表示,最后再将其结果结合起来,如下图所示:
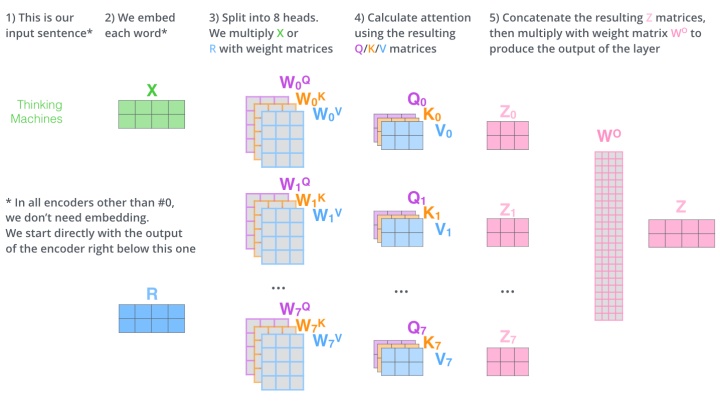
这就是基本的Multihead Attention单元,对于encoder来说就是利用这些基本单元叠加,其中key, query, value均来自前一层encoder的输出,即encoder的每个位置都可以注意到之前一层encoder的所有位置。
对于decoder来讲,我们注意到有两个与encoder不同的地方,一个是第一级的Masked Multi-head,另一个是第二级的Multi-Head Attention不仅接受来自前一级的输出,还要接收encoder的输出,下面分别解释一下是什么原理。
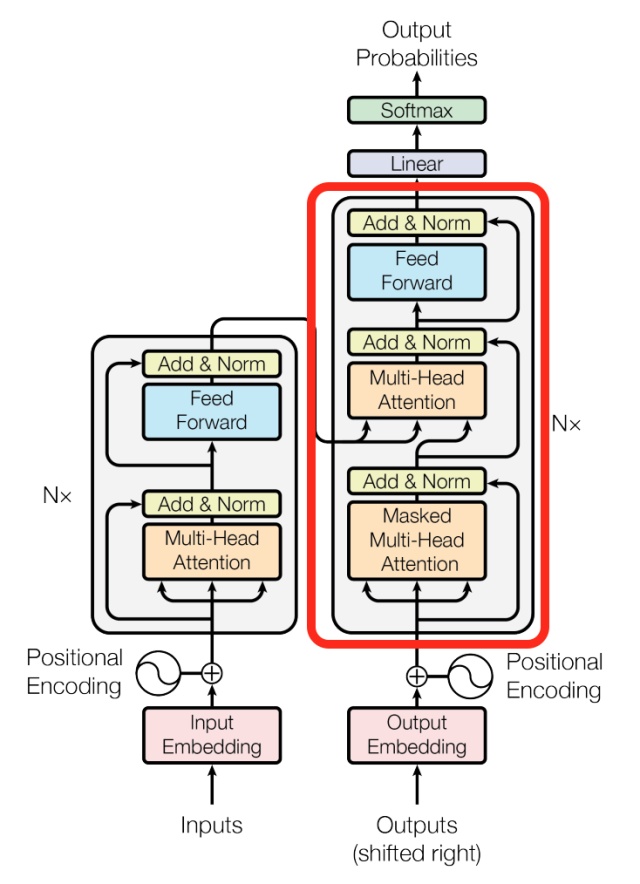
第一级decoder的key, query, value均来自前一层decoder的输出,但加入了Mask操作,即我们只能attend到前面已经翻译过的输出的词语,因为翻译过程我们当前还并不知道下一个输出词语,这是我们之后才会推测到的。
而第二级decoder也被称作encoder-decoder attention layer,即它的query来自于之前一级的decoder层的输出,但其key和value来自于encoder的输出,这使得decoder的每一个位置都可以attend到输入序列的每一个位置。
总结一下,k和v的来源总是相同的,q在encoder及第一级decoder中与k,v来源相同,在encoder-decoder attention layer中与k,v来源不同。
论文其他细节解读
我们再来看看论文其他方面的细节,一个使position encoding,这个目的是什么呢?注意由于该模型没有recurrence或convolution操作,所以没有明确的关于单词在源句子中位置的相对或绝对的信息,为了更好的让模型学习位置信息,所以添加了position encoding并将其叠加在word embedding上。该论文中选取了三角函数的encoding方式,其他方式也可以,该研究组最近还有relation-aware self-attention机制,可参考这篇论文[1803.02155] Self-Attention with Relative Position Representations。
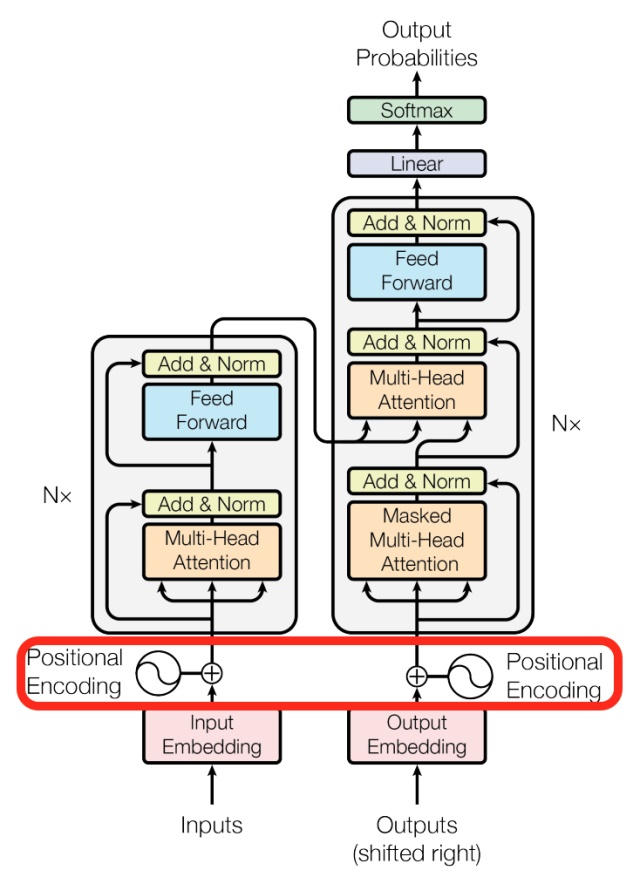
再来看看模型中这些Add & Norm模块的作用。
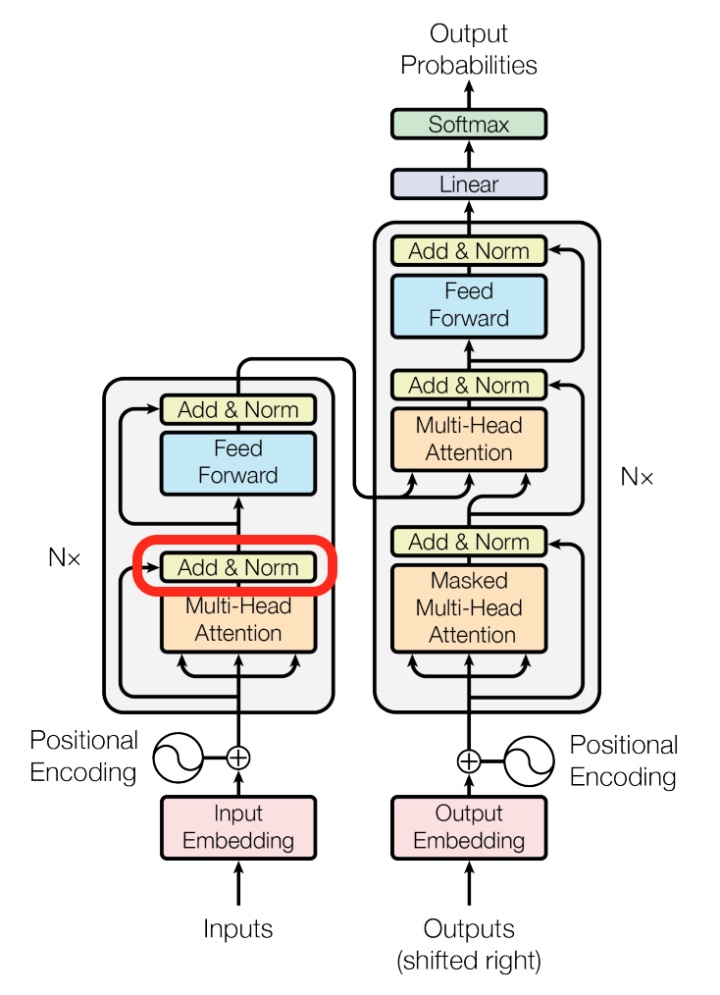
其中Add代表了Residual Connection,是为了解决多层神经网络训练困难的问题,通过将前一层的信息无差的传递到下一层,可以有效的仅关注差异部分,这一方法之前在图像处理结构如ResNet等中常常用到。
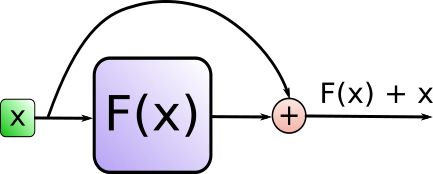
而Norm则代表了Layer Normalization,通过对层的激活值的归一化,可以加速模型的训练过程,使其更快的收敛,可参考这篇论文Layer Normalization。
源码解读
我们可以通过阅读源码加深理解,主要的部分是common_attention library以及调用该library的Transformer模型。
我们先来看看common_attention library 中的multihead-attention method(为简化省去很多argument及logic,集中于主要的logic,而且以单一head为例并加入了自己的一些comment,感兴趣的可以详细查阅源码):
def 其中compute_qkv定义为
def 其中dot_product_attention定义为
def 我们再来看看Transformer模型中是如何调用的,对于encoder
def 对于decoder
def 这些代码验证了我们之前在self-attention详解中的理解是正确的。
总结
完全的不依赖于RNN结构仅利用Attention机制的Transformer由于其并行性和对全局信息的有效处理使其获得了较之前方法更好的翻译结果,在这基础上,Attention和Transformer架构逐步被应用在自然语言处理及图像处理等领域,下一篇将会介绍这些方面的应用。
川陀学者:Attention机制详解(三)——Attention模型的应用zhuanlan.zhihu.com
参考资料:
[1] CS224n: Natural Language Processing with Deep Learning 斯坦福自然语言处理教程。
[2]Attention is All you need
[3]One Model to Learn them All
[4]Universal Transformers
[5]Tensor2Tensor
[5]https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
[6]https://jalammar.github.io/illustrated-transformer/
[7]Self-Attention with Relative Position Representations
[8]Layer Normalization
最后
以上就是眯眯眼春天最近收集整理的关于attention机制_Attention机制详解(二)——Self-Attention与Transformer的全部内容,更多相关attention机制_Attention机制详解(二)——Self-Attention与Transformer内容请搜索靠谱客的其他文章。








发表评论 取消回复