写在前面
1. 着力于本质,才能通万物——重点在于分析其内在原理,对于普通的操作不做太详细的学习。
目录
写在前面
一、定义
二、 基本概念
三、技术架构
四、数据结构
-
一、定义
1. 基于Apache Lucene的分布式多用户能力的全文搜索引擎
2. 采用RESTful风格来命名自己的API
3. 基本格式:http://<ip>:<port>/<索引>/<类型>/<文档id>
4. 常用动词:GET/PUT/POST/DELETE
5. 分而治之,一切为了更高的查询性能
-
二、 基本概念
1. 索引(Index):Elastic 数据管理的顶层单位即 Index(索引),是单个数据库的同义词。每个 Index (即数据库)的名字必须是小写。
2. 文档(Document):Index 里面单条的记录称为 Document(文档),ES中的文档(Document)是没有固定的模式和统一的结构。
字段(Field):文档的一个Key/Value对;
词(Term):表示文本中的一个单词;
标记(Token):表示在字段中出现的词,由该词的文本、偏移量(开始和结束)以及类型组成;
3. 文档类型(Type):Document 的分组即Type,不同的Type应该有相似的结构(schema)。
4. 节点(Node):单独一个ElasticSearch服务器实例称为一个节点。
5. 集群(Cluster):集群是多个ElasticSearch节点的集合。是提供高可用与高性能的重要手段。
6. 分片索引(Shard):集群能够存储超出单机容量的信息。为了实现这种需求,ElasticSearch把数据分发到多个存储Lucene索引的物理机上。这些Lucene索引称为分片索引,这个分发的过程称为索引分片(Sharding)。
7. 索引副本(Replica):当集群负载增长,用户搜索请求可能会阻塞在单个节点上时,通过索引副本(Replica)机制就可以解决这个问题。在提供基础查询性能的同时,也保证了数据的安全性。即如果主分片数据丢失,ElasticSearch通过索引副本使得数据不丢失。索引副本可以随时添加或者删除,所以用户可以在需要的时候动态调整其数量。
8. 网管(Gateway):ES运行过程中需要的所有数据(文档,状态、索引参数等)都被存储在Gateway中。
-
三、技术架构
查询分为两个阶段:分散阶段(scatter phase)和合并阶段(gather phase)。在分散阶段将查询分发到包含相关文档的多个分片中去执行查询,而在合并阶段则从众多分片中收集返回结果,然后对它们进行合并、排序,进行后续处理,然后返回给客户端。

(一) 分片/副本策略
1. 为支持大量数据,索引会按某个维度分成多个部分,每个部分就是一个分片(Shard)。一个节点(Node)一般会管理多个分片。
2. 同一个索引分片通常会分布到不同节点(Node)上。分片有两种,分别是主分片(Primary)和副本分片(Replica)。注意,建索引操作只会发生在主分片上,而不是副本上。
(二)MasterNode、DataNode、TransportNode
混合部署
1. DataNode 和 TransportNode 混合,每一个节点既存分片又存全局路由表。
2. 优势: 简单、易上手;
3. 缺点:多种请求会相互影响,大集群中如果某一个节点出现问题,就会影响途径这个DataNode的所有其他跨Node请求;没办法热更新。
分层部署
1. 部分节点专门做请求转发和结果合并(TransportNode);部分节点专门做数据处理(DataNode);
2. 好处就是角色相互独立,不会相互影响,一般Transport Node的流量是平均分配的,很少出现单台机器的CPU或流量被打满的情况,而DataNode由于处理数据,很容易出现单机资源被占满,比如CPU,网络,磁盘等。独立开后,DataNode如果出了故障只是影响单节点的数据处理,不会影响其他节点的请求,影响限制在最小的范围内。
(三)路由策略
路由分层,共四层:RountingTable、IndexRoutingTable、IndexShardRountingTable、ShardRountingTable。
-
四、数据存储结构
(一) ElasticSearch可以存储结构和非结构的数据。
(二) 倒排索引(敲黑板,划重点)
1. 普通关系型数据库通常采用BTree索引,而ES采用的是倒排索引。思路:
将磁盘里的东西尽量搬进内存,减少磁盘随机读取次数(同时也利用磁盘顺序读特性),结合各种奇技淫巧的压缩算法,用及其苛刻的态度使用内存。
2. ES将Document直接进行存储?
No~首先将Doc进行分词,然后存储词条以及词条和文档之间的映射关系(Postings List)。
3. 这么简单的词条(Term)存储可以造就ES检索的高效率吗?
No~把内存用到极致才是优秀的检索。
ES建立了Term Index-->Term Dictionary-->Term Position的存储/检索方式。
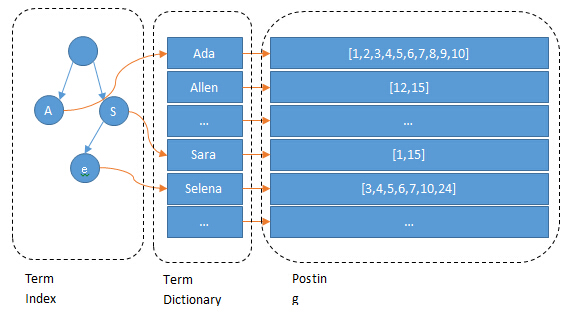
Term Index:采用FST (Finite State Transducer)结构,像一棵树,这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。同时,可以使term index缓存到内存中。
Term Dictionary:Term词典,用于定位到Postinglist。
Posting List:会其进行压缩——顺序存储,增量编码压缩,将大数变小数,按字节存储。(1)那如果ID是顺序的,或者是有公共前缀等具有一定规律性的ID,压缩比会比较高;(2)通过Posting list里的ID到磁盘中查找Document,因为Elasticsearch是分Segment存储的,根据ID这个大范围的Term定位到Segment的效率直接影响了最后查询的性能,如果ID是有规律的,可以快速跳过不包含该ID的Segment,从而减少不必要的磁盘读次数。
(三)那么是不是所有的字段需要被分词然后索引的呢?——显然不是。
1. 当index为analyzed时,该字段是分析字段,ElasticSearch引擎对该字段执行分析操作,把文本分割成分词流,存储在倒排索引中,使其支持全文搜索;
2. 当index为not_analyzed时,该字段不会被分析,ElasticSearch引擎把原始文本作为单个分词存储在倒排索引中,不支持全文搜索,但是支持词条级别的搜索;也就是说,字段的原始文本不经过分析而存储在倒排索引中,把原始文本编入索引,在搜索的过程中,查询条件必须全部匹配整个原始文本;
3. 当index为no时,该字段不会被存储到倒排索引中,不会被搜索到;
-
五、搜索
(一)查询相关性、评分公式
(二)
- 未完待续
最后
以上就是合适秀发最近收集整理的关于大数据之ElasticSearch写在前面的全部内容,更多相关大数据之ElasticSearch写在前面内容请搜索靠谱客的其他文章。








发表评论 取消回复