PHP简介:PHP是一种适用于web开发的动态脚本语言(网页快捷开发),是用纯C语言实现的。我们可以认为PHP就是一个用C语言实现包含大量组件的软件框架。更狭义一点可以认为是一个功能强大的UI框架。
PHP的设计理念及特点
- 多进程模型:PHP采用多进程模型,不同请求之间互不干涉,保证了一个请求挂掉不会对其它请求和服务造成影响。当然,PHP目前已支持多线程模型;
- 弱类型语言:PHP是一门弱类型语言,变量的类型在定义时是不需要给定的,会在运行中根据变量的值发生隐式或是显式的类型转换,这种机制的灵活性在web开发中非常方便、高效;
- PHP通过引擎(zend)+组件(extension)的模式来降低内部耦合;
- 中间层(sapi)隔绝web server 与 PHP;
- 语法简单灵活,没有太多的规范,当容易导致代码风格的混乱。
PHP的四层架构(如下图)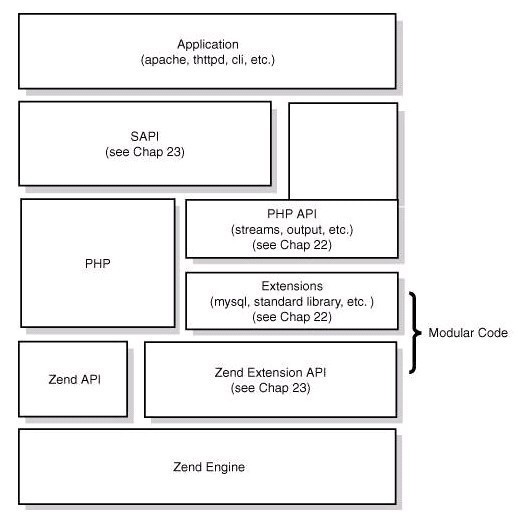
-
Zend引擎:也可以称之为Zend软件虚拟机,用于翻译执行PHP代码。Zend整体用纯C实现,是PHP的内核部分,它将PHP代码翻译(词法、语法解析等一系列编译过程)为可执行opcode代码,并实现相应的处理方法、实现了基本的数据结构(主要的数据结构是hashtable)、内存分配及管理、提供了相应的api方法供外部调用,是一切的核心,所有的外围功能均围绕Zend实现。
- Opcode:是一种PHP脚本编译后的中间语言,是PHP最终真正执行的代码,类似于java中的字节码(ByteCode)执行一段PHP代码会有如下四个步骤:
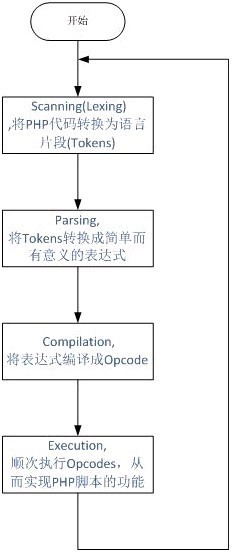
- 将PHP代码转换为语言片段(Tokens);
- 将Tokens转换成简单而有意义的表达式;
- 将表达式编译成Opocde;
- 顺次执行Opcodes,每次一条,从而实现PHP脚本的功能。
- 由上可知,PHP实现了一个典型的动态语言执行过程:拿到一段代码后,经过词法解析、语法解析等阶段后,源程序会被翻译成一个个指令 (opcode),然后Zend虚拟机顺次执行这些指令完成操作。另外,PHP本身是用C实现的,因此最终调用的也都是C的函数,实际上,我们可以把PHP看做是一个C开发的软件。PHP的执行的核心是翻译出来的一条一条指令,即opcode。
- 补充:现在有的Cache比如APC,可以使得PHP缓存住Opcodes,这样,每次有请求来临的时候,就不需要重复执行前面3步,从而能大幅的提高PHP的执行速度。
- Opcode:是一种PHP脚本编译后的中间语言,是PHP最终真正执行的代码,类似于java中的字节码(ByteCode)执行一段PHP代码会有如下四个步骤:
-
Extensions:围绕着Zend引擎,extensions通过组件式的方式提供各种基础服务,我们常见的各种内置函数(如array 系列)、标准库等都是通过extension来实现,用户也可以根据需要实现自己的extension以达到功能扩展、性能优化等目的(如PHP中间层、富文本解析就是extension的典型应用)。
-
Sapi:Sapi全称是Server Application Programming Interface,也就是服务端应用编程接口,Sapi通过一系列钩子函数,使得PHP可以和外围交互数据,这是PHP非常优越和成功的一个设计,通过 sapi成功的将PHP本身和上层应用解耦隔离,PHP可以不再考虑如何针对不同应用进行兼容,而应用本身也可以针对自己的特点实现不同的处理方式。
-
Sapi通过一系列的接口,使得外部应用可以和PHP交换数据并可以根据不同应用的特性实现特定的处理方法,我们常见的一些sapi有:
- apache2handler:这是以apache作为webserver,采用mod_PHP模式运行时候的处理方式也是现在应用最广泛的一种。
- cgi:这是webserver和PHP直接的另一种交互方式,也就是大名鼎鼎的fastcgi协议,在最近几年fastcgi+PHP得到越来越多的应用,也是异步webserver所唯一支持的方式。
- cli:命令行调用的应用模式
-
-
上层应用:这就是我们平时编写的PHP脚本程序,通过不同的sapi方式得到各种各样的应用模式,如通过webserver(比较常用的是Apache或Nginx)实现web应用、在命令行下以脚本方式运行等等。
核心数据结构HashTable
- HashTable在PHP中是数据存储的核心。各种常量、变量、函数、类以及对象都是通过HashTable来组织的。在实现HashTable时结合了双向链表和数组两种数据结构的优点,提供了非常高效的查询与存储机制。
- 在Zend HashTable包括两个主要的数据结构,其一是Bucket(桶)结构,另一个是HashTable结构。Bucket结构是用于保存数据的容器,而 HashTable结构则提供了对所有这些Bucket(或桶列)进行管理的机制。每个元素(Bucket)都有一个唯一的键名(Key),根据键名可以在HashTable中确定一个唯一的数据元素。
- Bucket结构:
typedef struct bucket {
ulong h; /* Used for numeric indexing */
uint nKeyLength; /* key 长度 */
void *pData; /* 指向Bucket中保存的数据的指针 */
void *pDataPtr; /* 指针数据 */
struct bucket *pListNext; /* 指向HashTable桶列中下一个元素 */
struct bucket *pListLast; /* 指向HashTable桶列中前一个元素 */
struct bucket *pNext; /* 指向具有同一个hash值的桶列的后一个元素 */
struct bucket *pLast; /* 指向具有同一个hash值的桶列的前一个元素 */
char arKey[1]; /* 必须是最后一个成员,key名称*/
} Bucket;
- 补充:键名有两种表示方式。第一种方式使用字符串arKey作为键名,该字符串的长度为nKeyLength。注意到在上面的数据结构中arKey虽然只是一个长度为1的字符数组,但它并不意味着key只能是一个字符。实际上Bucket是一个可变长的结构体,由于arKey是 Bucket的最后一个成员变量,通过arKey与nKeyLength结合可确定一个长度为nKeyLength的key。这是C语言编程中的一个比较常用的技巧。另一种键名的表示方式是索引方式,这时nKeyLength总是0,长整型字段h就表示该数据元素的键名。简单的来说,即如果 nKeyLength=0,则键名为h;否则键名为arKey, 键名的长度为nKeyLength。当nKeyLength > 0时,并不表示这时的h值就没有意义。事实上,此时它保存的是arKey对应的hash值。不管hash函数怎么设计,冲突都是不可避免的,也就是说不同 的arKey可能有相同的hash值。具有相同hash值的Bucket保存在HashTable的arBuckets数组(参考下面的解释)的同一个索引对应的桶列中。这个桶列是一个双向链表,其前向元素,后向元素分别用pLast, pNext来表示。新插入的Bucket放在该桶列的最前面。在Bucket中,实际的数据是保存在pData指针指向的内存块中,通常这个内存块是系统另外分配的。但有一种情况例外,就是当Bucket保存的数据是一个指针时,HashTable将不会另外请求系统分配空间来保存这个指针,而是直接将该指针保存到pDataPtr中,然后再将pData指向 本结构成员的地址。这样可以提高效率,减少内存碎片。由此我们可以看到PHP HashTable设计的精妙之处。如果Bucket中的数据不是一个指针,pDataPtr为NULL。HashTable中所有的Bucket通过pListNext, pListLast构成了一个双向链表。最新插入的Bucket放在这个双向链表的最后。
- 注意:在一般情况下,Bucket并不能提供它所存储的数据大小的信息。所以在PHP的实现中,Bucket中保存的数据必须具有管理自身大小的能力。
- HashTable结构:
typedef struct _hashtable {
uint nTableSize;
uint nTableMask;
uint nNumOfElements;
ulong nNextFreeElement;
Bucket *pInternalPointer;
Bucket *pListHead;
Bucket *pListTail;
Bucket **arBuckets;
dtor_func_t pDestructor;
zend_bool persistent;
unsigned char nApplyCount;
zend_bool bApplyProtection;
#if ZEND_DEBUG
int inconsistent;
#endif
} HashTable;
- 在HashTable结构中,nTableSize指定了HashTable的大小,同时它限定了HashTable中能保存Bucket的最大数量,此数越大,系统为HashTable分配的内存就越多。为了提高计算效率,系统自动会将nTableSize调整到最小一个不小于nTableSize的2 的整数次方。也就是说,如果在初始化HashTable时指定一个nTableSize不是2的整数次方,系统将会自动调整nTableSize的值。即:nTableSize = 2ceil(log(nTableSize, 2)) 或 nTableSize = pow(ceil(log(nTableSize,2)))。如果在初始化HashTable的时候指定nTableSize = 11,HashTable初始化程序会自动将nTableSize增大到16。
- arBuckets是HashTable的关键,HashTable初始化程序会自动申请一块内存,并将其地址赋值给arBuckets,该内存大小正好能容纳nTableSize个指针。我们可以将arBuckets看作一个大小为nTableSize的数组,每个数组元素都是一个指针,用于指向实际存放数据的Bucket。当然刚开始时每个指针均为NULL。
- nTableMask的值永远是nTableSize – 1,引入这个字段的主要目的是为了提高计算效率,是为了快速计算Bucket键名在arBuckets数组中的索引。
- nNumberOfElements记录了HashTable当前保存的数据元素的个数。当nNumberOfElement大于nTableSize时,HashTable将自动扩展为原来的两倍大小。
- nNextFreeElement记录HashTable中下一个可用于插入数据元素的arBuckets的索引。
- pListHead、 pListTail则分别表示Bucket双向链表的第一个和最后一个元素,这些数据元素通常是根据插入的顺序排列的。也可以通过各种排序函数对其进行重 新排列。pInternalPointer则用于在遍历HashTable时记录当前遍历的位置,它是一个指针,指向当前遍历到的Bucket,初始值是 pListHead。
- pDestructor是一个函数指针,在HashTable增加、修改、删除Bucket时自动调用,用于处理相关数据的清理工作。
- persistent标志位指出了Bucket内存分配的方式。如果persisient为TRUE,则使用操作系统本身的内存分配函数为Bucket分配内存,否则使用PHP的内存分配函数。具体请参考PHP的内存管理。
- nApplyCount与bApplyProtection结合提供了一个防止在遍历HashTable时进入递归循环时的一种机制。
- inconsistent成员用于调试目的,只在PHP编译成调试版本时有效。表示HashTable的状态,状态有四种:
状态值 含义
HT_IS_DESTROYING 正在删除所有的内容,包括arBuckets本身
HT_IS_DESTROYED 已删除,包括arBuckets本身
HT_CLEANING 正在清除所有的arBuckets指向的内容,但不包括arBuckets本身
HT_OK 正常状态,各种数据完全一致
- 键名结构:
typedef struct _zend_hash_key {
char *arKey; /* hash元素key名称 */
uint nKeyLength; /* hash 元素key长度 */
ulong h; /* key计算出的hash值或直接指定的数值下标 */
} zend_hash_key;
- 现在来看zend_hash_key结构就比较容易理解了。它通过arKey, nKeyLength, h三个字段唯一确定了HashTable中的一个元素。
结语:以上便是自己总结的一些原理知识,其中参考了一位大佬写的文章,非常不错,推荐一下Zend HashTable详解,文章中对HashTable的实现也做了描述,值得一看。
最后
以上就是健壮刺猬最近收集整理的关于PHP运行原理的全部内容,更多相关PHP运行原理内容请搜索靠谱客的其他文章。








发表评论 取消回复