前面的话:本人目前北邮研一在读,觉得前面的博主写的很好,自己经常也要看,所以前面一部分转载于博主的。恳请博主不要误会,若是给你造成麻烦立即删除,后面开始学习心得和笔记的记载。希望大家能一起成功!
“啤酒与尿布”故事:
这是一个几乎被举烂的例子,“啤酒与尿布”的故事产生于20世纪90年代的美国沃尔玛超市中,沃尔玛的超市管理人员分析销售数据时发现了一个令人难于理解的现象:在某些特定的情况下,“啤酒”与“尿布”两件看上去毫无关系的商品会经常出现在同一个购物篮中,这种独特的销售现象引起了管理人员的注意,经过后续调查发现,这种现象出现在年轻的父亲身上。
在美国有婴儿的家庭中,一般是母亲在家中照看婴儿,年轻的父亲前去超市购买尿布。父亲在购买尿布的同时,往往会顺便为自己购买啤酒,这样就会出现啤酒与尿布这两件看上去不相干的商品经常会出现在同一个购物篮的现象。如果这个年轻的父亲在卖场只能买到两件商品之一,则他很有可能会放弃购物而到另一家商店,直到可以一次同时买到啤酒与尿布为止。沃尔玛发现了这一独特的现象,开始在卖场尝试将啤酒与尿布摆放在相同的区域,让年轻的父亲可以同时找到这两件商品,并很快地完成购物;而沃尔玛超市也可以让这些客户一次购买两件商品、而不是一件,从而获得了很好的商品销售收入,这就是“啤酒与尿布”故事的由来。
当然“啤酒与尿布”的故事必须具有技术方面的支持。1993年美国学者Agrawal 提出通过分析购物篮中的商品集合,从而找出商品之间关联关系的关联算法,并根据商品之间的关系,找出客户的购买行为。艾格拉沃从数学及计算机算法角度提出了商品关联关系的计算方法——A prior算法。沃尔玛从上个世纪90年代尝试将Aprior算法引入到POS机数据分析中,并获得了成功,于是产生了“啤酒与尿布”的故事。
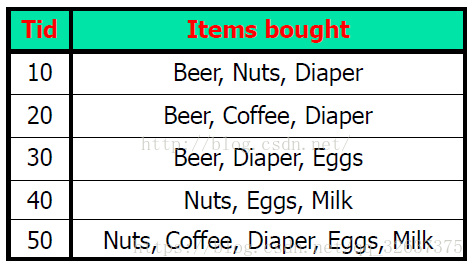
频繁项集基本概念:
频繁模式主要作用是寻找到数据集中频繁出现的项集、序列或子结构。
1.项集(itemset):
最基本的模式是项集,它是指若干个项的集合。如上图,{Beer,Nuts,Diaper}就是一个项集。
2.K-项集(K-itemset):
包含K个项的项集
3.数据集:
典型的数据集是事物的集合,每一个事物是一个非空项集,并拥有一个标识TID。如上图,上图就是一个数据集。
4.绝对支持度(Absolute Support):
数据集中包含项集X的事物数。如上图,含Beer的TID为10,20,30,因此绝对支持度就是3。
5.相对支持度(Relative Support):
项集X的绝对支持度与数据集事物总数的比值。如上图,Beer的绝对支持度为3,相对支持度为60%。
6.频繁项集(Frequent Itemset):
项集X的支持度超过最小支持度阀值(min_sup)时,称X为频繁项集。min_sup大部分情况下由需求而定,如上图,如果min_sup=50%,则Beer为频繁项集,如果min_sup=70%,则Beer不是频繁项集。
关联规则(Association Rules):
光是知道频繁项集,并不能带来什么,因此我们需要引入关联规则的概念。
1.支持度(Support):
可以理解为上方的相对支持度。通常需要一个最小支持度阀值(min_sup)或者其他相应的筛选规则(比如,销量最高的前20个)来进行筛选。
2.置信度(Confidence):
反映了规则的确定性。置信度是一个事物在包含X的同时也包含Y的条件概率。置信度作用于多个项的项集,因此所有置信度都是单项的,也就是X->Y与Y->X的置信度不同。如上图,{Beer,Diaper}这个项集的绝对支持度是3,Beer->Diaper的置信度为3/3(Beer的绝对支持度)=100%,而Diaper->Beer的置信度为3/4(Diaper的绝对支持度)=75%。同样,置信度也会有最小置信度阈值。
同时满足最小支持度阈值和最小置信度阈值的规则称为强规则
一般而言,关联规则的挖掘分为两步:
1.找出所有频繁项集,即候选规则
2. 对所有候选规则计算置信度,找出其中的强规则
3.提升值(Lift):
以度量此规则是否可用。描述的是相对于不用规则,使用规则可以提高多少。
lift(A->B) = P(AB)/(P(A)P(B))
lift > 1 则不是偶然现象,有较强的关联度。
lift<=1 的规则不做参考
频繁项集的压缩:
频繁项集里存在着较多的冗余,因此人们又引入了频繁闭项集和最大频繁集的概念。
1.频繁闭项集(Closed Patterns):
当项集X是频繁项集,且数据集D中不存在X的真超集Y,使得X和Y的支持度相等,则X是闭频繁项集。闭频繁项集的表示是无损压缩,不会丢失支持度的信息。通过闭频繁项集可以反推出所有的频繁项集以及相应的支持度。
完全看不懂吧,还是来举个栗子(( ̄︶ ̄)↗)。
因为项集{Beer,Diaper}出现在TID为10,20,30的事务中,所以{Beer,Diaper}的绝对支持度为3。而{Beer,Diaper}的直接超集:{Beer,Nuts,Diaper},{Beer,Coffee,Diaper},{Beer,Diaper,Eggs}的支持度计数分别为1,1,1,都不等于{Beer,Diaper}的支持度计数3,所以{Beer,Diaper}为闭项集,如果其支持度超过阈值,则{Beer,Diaper}为闭频繁项集。
2.最大频繁项集(Max-Patterns):
当项集X是频繁项集,且数据集D中不存在X的真超集Y,使得Y是频繁项集,则X是最大频繁项集。极大频繁项集的表示是有损压缩,失去了频繁项集的支持度信息,我们可以根据极大频繁项集判断任意项集是否是频繁的,但无法得到相应的支持度。
理论什么的看着就头大,还是来举个栗子吧~(~ ̄▽ ̄)~。
如果,{Beer,Nuts,Diaper}大于最小阀值(别看支持度什么的都很低,但是阀值是人定的,讲不定就大于阀值呢。),那{Beer,Nuts,Diaper}就是个最大频繁项集,因为没有包含{Beer,Nuts,Diaper}并且比它更大的集合了。
频繁项集挖掘算法:
1.Apriori :(Agrawal & Srikant@VLDB’94)
2.Eclat (Zaki, Parthasarathy, Ogihara, Li @KDD’97)
3.FP-Growth (Han, Pei, Yin @SIGMOD’00)

举个例子:
1.频繁模式判断
首先由于模式acdf在数据库中出现2次,所以模式acdf支持度为:
ξ
=
2
5
=
0.4
xi=frac{2}{5}=0.4
ξ=52=0.4
归纳一下就是,
ξ
=
某
个
模
式
出
现
在
数
据
库
中
次
数
整
个
数
据
库
中
模
式
的
总
个
数
xi=frac{某个模式出现在数据库中次数}{整个数据库中模式的总个数}
ξ=整个数据库中模式的总个数某个模式出现在数据库中次数
acdf满足最小支持度要求,因此模式acdf是频繁模式。由于没有其他频繁模式含有acdf,故模式acdf是最大频繁模式.
2.关联模式的判断
在模式acdf中最大支持度项目c的支持度是5**(出现了5次),所以模式***acdf***的***all-confidence***是:
α
=
2
5
=
0.4
<
η
=
0.5
alpha=frac{2}{5}=0.4<eta=0.5
α=52=0.4<η=0.5
小于最小all-confidence,因此模式acdf不是关联模式。
由于模式adf在数据库中出现了2次,所以模式adf支持度也满足要求,即为频繁模式,且模式adf中最大支持度项目f的支持度是4,所以模式adf的all-confidence是
α
=
2
4
alpha=frac{2}{4}
α=42,满足最小all-confidence,因此模式adf是频繁的关联模式。
总结一下怎么判断关联模式:
η
=
某
个
模
式
出
现
在
数
据
库
中
次
数
其
中
某
个
最
大
元
素
的
支
持
度
eta=frac{某个模式出现在数据库中次数}{其中某个最大元素的支持度}
η=其中某个最大元素的支持度某个模式出现在数据库中次数
3.最大频繁关联模式的判断
由于包含模式adf的频繁模式只有acdf,而acdf不是最大频繁关联模式,所以模式adf是最大频繁关联模式。
关联和相关的定义区分
其实遇到这个情况但时候我也很头大,啥叫关联,啥又是相关。简单的说,就是有两件产品A、B。如果一位顾客,买了A产品又去买B产品的概率特别大,那就说明A和B这两个产品的他们是关联的。举个例子来说就是,你网上抢到了一个小米MIX3,买了这个手机你很爱惜,你肯定要买手机壳,而且买手机壳的概率真的非常的高。那就说明这两款产品是关联的。事实上他们是不是关联的,手机和手机壳。这个不言而喻吧。用数学的语言来表示就是
P
(
B
/
A
)
发
生
的
概
率
非
常
高
,
即
在
A
发
生
的
条
件
下
B
发
生
的
概
率
特
别
高
P(B/A)发生的概率非常高 ,即在A发生的条件下B发生的概率特别高
P(B/A)发生的概率非常高,即在A发生的条件下B发生的概率特别高
那什么又是相关呢?
就是说一个顾客是否购买B严重的影响他时候购买A,举个例子,我现在要买一本python的书,一本是A书,一本是B书
最后
以上就是细腻航空最近收集整理的关于频繁模式和关联规则:的全部内容,更多相关频繁模式和关联规则内容请搜索靠谱客的其他文章。








发表评论 取消回复