决策树的理论部分
- 什么是决策树
- 决策树的工作原理
- 如何建立决策树
- Hunt算法
- 选择最佳划分的度量
什么是决策树
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。Entropy = 系统的凌乱程度,使用算法ID3, C4.5和C5.0生成树算法使用熵。这一度量是基于信息学理论中熵的概念。
这是百度给出的介绍,如果想了解决策树,我们先要了解一些基础概念
- 分类任务
分类任务就是确定对象属于哪个预先定义的目标类别,这是一个普遍存在的问题有非常多的应用,生活中我们就用得上,例如根据电子邮件标题和内容检查是否是垃圾邮件,通过搜索记录判断用户的男女,这一章我们主要介绍决策树的一些理论。 - 描述性建模
分类模型可以用作解释性的工具,用于区分不同类中的对象。例如下表
| 名称 | 体温 | 表皮覆盖 | 胎生 | 水生动物 | 飞行动物 | 有腿 | 冬眠 | 类别 |
|---|---|---|---|---|---|---|---|---|
| 人类 | 恒温 | 毛发 | 是 | 否 | 否 | 是 | 否 | 哺乳类 |
| 蟒蛇 | 冷血 | 鳞片 | 否 | 否 | 否 | 否 | 是 | 爬行类 |
| 桂鱼 | 冷血 | 鳞片 | 否 | 是 | 否 | 否 | 否 | 鱼类 |
.
.
.
还有很多行我就不写了
3.预测性建模
分类模型还可以用于预测未知记录的类别,当我们发现了一个新的物种,我们就可以根据上面图中的数据集建立的分类模型来确定该生物所属的类别
| 名称 | 体温 | 表皮覆盖 | 胎生 | 水生动物 | 飞行动物 | 有腿 | 冬眠 | 类别 |
|---|---|---|---|---|---|---|---|---|
| 毒蜥 | 冷血 | 鳞片 | 否 | 否 | 否 | 是 | 是 | ??? |
输入属性集→分类模型→输出类别
4.分类计数的一般方法
分类技术其实就是根据输入数据集建立分类模型的系统方法,分类也有很多种,例如:决策树,朴素贝叶斯,神经网络,支持向量机,这些技术都使用的一种学习算法确定分类模型,这些模型能很好的拟合输入数据中类标号和样本集之间的联系,进而正确预测位置样本的类标号
决策树的工作原理
好了我们总算到了主题了,决策树其实就是一种解决上面提出的分类问题的方法。
那么具体的原理又是什么呢?我们依旧使用上面关于动物的例子,如果我发现了一个新的物种,如何判断他是哺乳动物还是非哺乳动物呢?
那我就要提出一系列问题了
1.这个动物是冷血动物还是恒温动物?如果是冷血动物那肯定是非哺乳动物了。如果是恒温动物的话新的问题又来了
2.该物种是否是雌性产仔进行繁殖的么?如果是那肯定是哺乳动物了,如果不是那就有可能是非哺乳动物了。
通过提出一系列精心构思的关于属性的问题,可以解决分类问题,每当一个问题得到答案,后续的问题将随之而来。直到我们得到记录的类标号,这一系列问题和这些问题的可能答案就组成了决策树。如下图
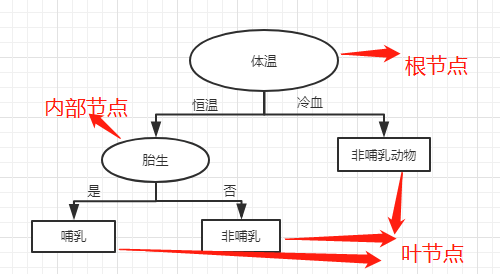
在决策树中,每个叶节点都赋予了一个类标号,而根节点和内部节点都有属性的测试条件用于区分不同特征的记录。一旦构造了决策树,对于检验记录进行分类就简单了。
例如:我们现在有一个物种:火烈鸟,恒温,卵生
这一条记录进入决策树,由于体温是恒温所以走左侧进行下一个判断,由于是卵生所以最终走到了叶节点非哺乳动物。
那么新的问题来了,如何构建一个决策树呢?
如何建立决策树
原则上说,对于给定的属性集,可以构造的决策树的数量是指数级的,啥意思?假设假设你有10个属性,那么根节点就可能有10个,后续的内部节点也是这个道理,你可以构建很多不同的树,但是如果计算所有树来找出最佳的决策树,这是不可行的,对于属性少的还好说,但是每添加一个新的属性其复杂度就会指数增长。这怎么办?人们开发除了一些有效的算法,能在合理的时间内构造出一定准确率的次最优决策树,Hunt算法就是这样一种算法,Hunt算法是许多决策树算法的基础,包括ID3 C4.5和CART,本章先讨论Hunt算法
Hunt算法
Hunt算法的主旨是讲训练记录相继划分为比较纯的子集,以递归的方式建立决策树。
Hunt算法通过将训练记录相继划分为较纯的子集,以递归方式建立决策树。设Dt是与结点t相关联的训练记录集,而y = { y1, y2, …, yc}为类标号,Hunt算法的递归定义如下:
1.如果Dt中所有的记录都属于同一个类yt,则结点t是叶子结点,用yt标记;
2.如果Dt中包含多个类的记录,则选择一个属性测试条件,将记录划分为较小的子集。对于测试条件的每个输出,创建一个子女结点,并根据测试结果将Dt中的记录分布到子女结点中,然后对每个子女结点递归地调用该算法;
| Tid | 有房者 | 婚姻状况 | 年收入 | 拖欠贷款 |
|---|---|---|---|---|
| 1 | 是 | 单身 | 125K | 否 |
| 2 | 否 | 已婚 | 100K | 否 |
| 3 | 否 | 单身 | 70K | 否 |
| 4 | 是 | 已婚 | 120K | 否 |
| 5 | 否 | 离异 | 95K | 是 |
| 6 | 否 | 已婚 | 60K | 否 |
| 7 | 是 | 离异 | 220K | 否 |
| 8 | 否 | 单身 | 85K | 是 |
| 9 | 否 | 已婚 | 75K | 否 |
| 10 | 是 | 单身 | 90K | 是 |
我们使用这个数据集来举例,首先根据‘有房者’作为测试条件(具体选择的理由后面会介绍),这些记录被划分为较小的子集,之后对根节点的子女递归的调用Hunt算法直到子集是纯的为止。
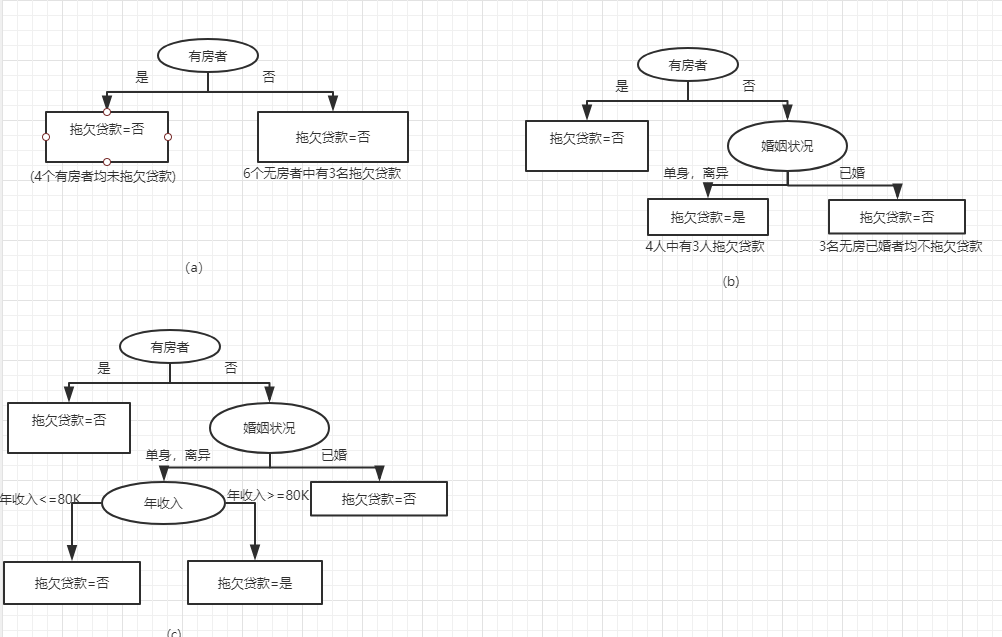
上图描述了Hunt算法的具体逻辑
选择最佳划分的度量
现在我们要解决一个问题,如何选择一个合适的标准来对根节点或中间节点进行判断,如何才能更好的将数据分配的更纯。
下面是几种计算不纯性的公式
gini
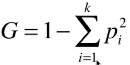
Entropy(熵)
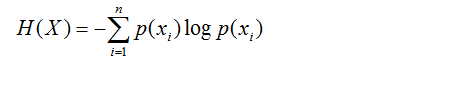
为了确定测试条件的效果,我们需要比较父节点(划分前)的不纯成都和子女节点(划分后)的不纯成都,他们差距越大,测试条件的效果就越好。当使用熵(entropy)当做不纯性度量的时候,信息增益 = entroy(前) - entroy(后),信息增益是ID3所使用的策略。
当需要划分的属性是连续值得时候怎么办?就像我们之前看到的贷款案例中,年收入。连续值你可以找出无数个分割点,怎么办呢?我们将记录中所有的属性值都作为候选划分点,对于每个划分点计算不纯度(gini或Entropy),找到纯度最好的那个作为分割点。
最后
以上就是生动西牛最近收集整理的关于决策树(理论部分)什么是决策树的全部内容,更多相关决策树(理论部分)什么是决策树内容请搜索靠谱客的其他文章。








发表评论 取消回复