磁盘故障导致索引无法恢复处理流程
ES集群版本:V_5.4.2
translog 损坏
如因磁盘故障,导致索引translog损坏而无法恢复,此时可通过清空索引translog的方式恢复索引,但translog中未刷盘的数据会丢失(索引历史数据不会丢失,一般来说,至多只会丢失当天数据)。
查看未分配分片原因
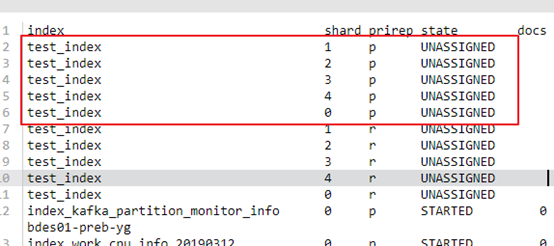
// 按照state状态正序排序,state一致时按照 prirep 正序排序
// 获取到未分配主分片(p)的 index,shard,prirep 信息
GET _cat/shards?v&s=state,prirep
// 使用explain命令查看未分配的原因
// index 填写未分配主分片的索引名称;shard 填写未分配主分片的分片编号;primary为true表示是主分片,填false表示查看副本未分配的原因
GET /_cluster/allocation/explain
{
"index": "test_index",
"shard": 1,
"primary": true
}
如果返回结果中,有 [failed to recover from translog] 字样,如:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-at2L308M-1587985414236)(F:Typora_picturesPathimage-20200427175126708.png)]](https://www.shuijiaxian.com/files_image/2023060423/20200427190648558.png)
“explanation” : “shard has exceeded the maximum number of retries [5] on failed allocation attempts - manually call [/_cluster/reroute?retry_failed=true] to retry, [unassigned_info[[reason=ALLOCATION_FAILED], at[2018-07-30T11:28:21.654Z], failed_attempts[5], delayed=false, details[failed shard on node [_wtZ2Gq7TvWoKsII2yCN6Q]: shard failure, reason [failed to recover from translog], failure EngineException[failed to recover from translog]; nested: TranslogCorruptedException[operation size must be at least 4 but was: 0]; ], allocation_status[deciders_no]]]”
或者在es集群日志中,有 [failed to recover from translog] 如:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NdAayBX9-1587985414240)(F:Typora_picturesPathimage-20200427175535976.png)]](https://www.shuijiaxian.com/files_image/2023060423/20200427190724649.png)
则表示是因为 translog 损坏,导致分片无法恢复,此时只能清空translog,会导致translog里的数据丢失(通知用户,会丢失当天的数据)。
通知用户
清空 translog 日志
通知用户后,开始清空未分配分片的translog 日志,在第一步查看未分配分片的原因时,通过explain命令,已经获取到了未分配分片所在节点:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-d3A1wXj0-1587985414244)(F:Typora_picturesPathimage-20200427175703135.png)]](https://www.shuijiaxian.com/files_image/2023060423/20200427190741230.png)
查看 explain 命令返回结果,找出所有带 [failed to recover from translog] 的对应的 node_name 的名称(可能有多个节点),假设在 es01 和 es02 两个节点上都找到了,则需要去 es01 和 es02 两个节点上去清空 translog 日志。
知道 索引名称index、未分配分片的编号shard,以及目标节点node_name后,需要去获取 index 的 UUID:
// 获取 index 的 UUID
GET _cat/indices/test_index?v
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lEHd8sbI-1587985414247)(F:Typora_picturesPathimage-20200427175819595.png)]](https://www.shuijiaxian.com/files_image/2023060423/20200427190757675.png)
获取到 UUID 后,即可开始清空 损坏的 translog 了,到目标节点 node_name 的es安装包的 bin 目录下,执行:
bin/elasticsearch-translog truncate -d /data00/clusterName/nodes/0/indices/UUID/shard/translog/
命令解析:
bin/elasticsearch-translog truncate –d : 固定不变
/data00/clusterName/nodes/0/indices/UUID/shard/translog/ :
data0*:磁盘(注意,节点上每一块磁盘,都需要清理)
clusterName:集群名称
UUID:索引的UUID
shard:未分配分片的编号
其余保持不变
/data00/clusterName/nodes/0 /indices 其实就是 es 的数据目录
手动分配分片
translog 清空后,即可手动分配分片了,使用 reroute 命令:
// 使用 allocate_stale_primary 命令手动分配分片
POST _cluster/reroute
{
"commands": [
{
"allocate_stale_primary": {
"index": "test_index",
"shard": 0,
"node": "one_of_node_name",
"accept_data_loss": true
}
}
]
}
命令解析:
index : 索引名称
shard : 未分配的分片的编号
node : 分配到哪一台节点上,填节点的名称,如 es-node1 【如果不确定节点名称,可以通过 GET _cat/nodes?v 命令,查看节点名称】注意,填写的节点名称,必须是清空 translog 的那个节点,如果有多个节点,随便选一个即可。
手动分配后,可以通过 GET _cat/shards/indexname?v 命令查看,是否未分配的分片状态,还是 UNASSIGNED ,如果不是,则流程结束,等待恢复;如果是,则 通过 explain 命令,查看原因。
index 文件损坏
如果是索引文件损坏,explain 或 集群日志中,有 input/output error 类似的字样,则表示无法恢复此分片的数据了,只能强制分配一个空主分片,原先分片里的数据会全部丢失。
手动分配分片到集群中任意一个节点上:
POST _cluster/reroute
{
"commands": [
{
"allocate_empty_primary": {
"index": "test_index",
"shard": 0,
"node": "one_of_cluster_node ",
"accept_data_loss": true
}
}
]
}
命令解析:
index : 索引名称
shard : 未分配的分片的编号
node : 集群任意一台正常的节点名称
最后
以上就是激昂犀牛最近收集整理的关于磁盘故障导致索引无法恢复处理流程磁盘故障导致索引无法恢复处理流程的全部内容,更多相关磁盘故障导致索引无法恢复处理流程磁盘故障导致索引无法恢复处理流程内容请搜索靠谱客的其他文章。








发表评论 取消回复