2019独角兽企业重金招聘Python工程师标准>>> 
一些常见商业应用程序或企业应用,大多都会遇上业务规则在一定的条件下,允许进行一些灵活的配置,以满足业务变化的需要。 解决的方式大致有以下几个方面:
- 最为传统的方式是java程序直接写死提供几个可调节的参数配置然后封装成为独立的业务模块组件,在增加参数或简单调整规则后,重新调上线。
- 最为彻底的解决方式,引入商业化规则引擎,如iLog,国产的“旗正规则引擎”等。
- 使用开源解决方案,典型的drools规则引擎。不过,我个人觉得,使用drools,多少有点换个地方写程序的意思,中国化支持比较弱。(PS:鄙人还没有正式使用过这款规则引擎,简单的做了几个案例,觉得不太适合我的业务场景,因此暂时放弃。希望有高手给予纠正)
受限于项目预算限制(国内的交付型项目,大家都懂的),引入商业化规则引擎几乎不能考虑,直接使用java实现相对独立的业务组件,在规则的维护上,并不太方便。使用开源drools,总是觉得这东西外国人用应该很不错,中国化的应用,还没有找到相对好一些的方案。
使用动态脚本引擎,是一个不错的方案。在JSR223规则中,已经对java中集成脚本引擎有了规范。目前较为常见的是在java中动态解析javascript,groovy。曾经使用过javascript作为脚本引擎,总是觉得他做得还不够,规则配置的灵活程度,还达不到自己的预期。试验了一段时间的groovy之后,各方面相对比较符合自己的预期。另外在activiti流程引擎中,内置支持groovy作为脚本引擎。
下面,我将举一个案例(MBA培训)为原形进行案例说明。如果对groovy不熟悉的同学,请自行学习groovy。
给几个参考:
http://www.groovy-lang.org/documentation.html#languagespecification(英文不好的同学不用担心,直接看它的案例代码就可以了,作为了一个英文四级没过的我,表示基本都能看懂)
http://www.jianshu.com/p/777cc61a6202
http://blog.csdn.net/a253664942/article/details/51182619
groovy是运行在JVM之上的,因此,和java天生就是兼容的。
先贴上数据模型
def student = ['id' : 'E9527',
'name' : '于小小',
'gender' : 'F',
'kind' : 'EMBA',
'className' : '重庆理工大学MBA三年级四班',
'grade' : 4,
'birth' : '1989/03/02',
'address' : '重庆市巴南区红光大道',
'salary' : 50000,
'createTime' : '2016/01/21 11:31:00',
'courses' : [
['id': 'GJC', name: '公共基础', 'classHour': 32],
['id': 'ZXW', name: '组织行为学', 'classHour': 40],
['id': 'TJX', name: '统计学', 'classHour': 20],
['id': 'CJR', name: '财务与金融', 'classHour': 60],
['id': 'JJF', name: '经济法', 'classHour': 48],
['id': 'JSJ', name: '计算机技能', 'classHour': 16],
],
'mainInstructor': ['id': 'TE007', 'name': '杨大大'],
'extra' : [
'attendanceLog': ['2016/02/01 09:00:02', '2016/02/03 08:50:03', '2016/02/15 09:12:34', '2016/04/01 07:30:11'],
'progressState': 'finished'
]
];每个属性名称以及字段,我想不需要解释,单单从数据上看,也能看懂95%以上。
使用这个数据模型,我需要计算出另一个业务对象模型(BOM)
def 规则集 = [
'基础信息':
[
'是否90后': '',
'性别' : '',
'注册天数':0,
'地区':''
],
'评级' : [
'学费档次' : '',
'收入档次':''
],
'学习情况': [
'总学时':0,
'迟到次数':0,
'出勤次数':0,
'单门课程最长学时':0,
]
]这样的一个业务模型,对于业务规则而言,可以进行一个统一的管理维护,可视化程度较好。由于是动态脚本因此可以动态拼装,这样的模型可以使用关系数据库统一维护,提供较好的GUI界面进行统一管理。
整体groovy代码
import java.text.SimpleDateFormat
import java.text.ParseException
class RuntimeContext {
//以下是英文部分变量,一般通过程序自动装载得到,用于从数据库或其他持久层加载业务数据
def collegeName = "EMBA业余大学"
def tuitionFee = 80000
def startDate = '2016/02/01', finishDate = '2016/09/01'
def today = "2017/01/21"
def student = ['id' : 'E9527',
'name' : '于小小',
'gender' : 'F',
'kind' : 'EMBA',
'className' : '重庆理工大学MBA三年级四班',
'grade' : 4,
'birth' : '1989/03/02',
'address' : '重庆市巴南区红光大道',
'salary' : 50000,
'createTime' : '2016/01/21 11:31:00',
'courses' : [
['id': 'GJC', name: '公共基础', 'classHour': 32],
['id': 'ZXW', name: '组织行为学', 'classHour': 40],
['id': 'TJX', name: '统计学', 'classHour': 20],
['id': 'CJR', name: '财务与金融', 'classHour': 60],
['id': 'JJF', name: '经济法', 'classHour': 48],
['id': 'JSJ', name: '计算机技能', 'classHour': 16],
],
'mainInstructor': ['id': 'TE007', 'name': '杨大大'],
'extra' : [
'attendanceLog': ['2016/02/01 09:00:02', '2016/02/03 08:50:03', '2016/02/15 09:12:34', '2016/04/01 07:30:11'],
'progressState': 'finished'
]
];
def toDate(_date){
try{
return (new SimpleDateFormat("yyyy/MM/dd hh:mm:ss")).parse(_date);
}catch(ParseException e){
return (new SimpleDateFormat("yyyy/MM/dd")).parse(_date);
}
}
def 规则集 = [
'基础信息':
[
'是否90后': student.birth >= '1990/01/01'?'是':'否',
'性别' : student.gender == 'M' ? '男' : '女',
'注册天数':toDate(today) - toDate(student.createTime),
'地区':{
def province = student.address.subSequence(0,3);
//做一个区域和省级行政单位的映射关系
def areaMapping = ['西南':['重庆市','四川省','贵州省','云南省'],'江浙沪':['上海市','江苏省','浙江省'],'京津冀':['北京市','天津市','河北省']];
//进行筛选
def entry = areaMapping.find {key,value ->
value.contains(province);
}
entry.key
}()//最后这个"()"一定要,否则闭包不执行
],
'评级' : [
//使用三元表达式,大于6W --> A ,4-6W --> B,2-4W -->C,2W以下 --> D
'学费档次' : tuitionFee>=60000?'A':(tuitionFee>=40000&&tuitionFee<60000?'B':(tuitionFee>=20000&&tuitionFee<40000)?'C':'D'),
'收入档次':{
if(student.salary>=20000) '高收入'
else if(student.salary>=10000) '中等收入'
else if(student.salary>=5000) '一般收入'
else '低收入'
}() //最后这个"()"一定要,否则闭包不执行
],
'学习情况': [
'总学时':{
int totalHourse = 0;
student.courses.each { totalHourse += it.classHour}
totalHourse
}(),
'迟到次数':{
int _count = 0
student.extra.attendanceLog.each {
Date _date = toDate(it)
_count += (_date.hours>=9&&_date.seconds>=1)?1:0
}
_count
}(),
'出勤次数':student.extra.attendanceLog.size(),
'单门课程最长学时':{
int maxHour = 0;
student.courses.each { maxHour = Math.max(maxHour,it.classHour)}
student.courses.find({it.classHour == maxHour}) //默认最后一句为返回值
}(),
]
]
}
// ========运行验证========
//创建运行时对象
def rctx = new RuntimeContext()
//输出结果看
//----简单的规则取值
println "基础信息.是否90后 = ${rctx.规则集.基础信息.是否90后}"
println "基础信息.性别 = ${rctx.规则集.基础信息['性别']}"
println "基础信息.注册天数 = ${rctx.规则集.基础信息.注册天数}"
println "评级.学费档次 = ${rctx.规则集.评级.学费档次}"
//----使用闭包的方式取值
println "基础信息.地区 = ${rctx.规则集.基础信息.地区}"
println "评级.收入档次 = ${rctx.规则集.评级.收入档次}"
println "学习情况.总学时 = ${rctx.规则集.学习情况.总学时}"
println "学习情况.迟到次数 = ${rctx.规则集.学习情况.迟到次数}"
println "学习情况.出勤次数 = ${rctx.规则集.学习情况.出勤次数}"
println "学习情况.单门课程最长学时 = ${rctx.规则集.学习情况.单门课程最长学时}"
运行结果如下图:
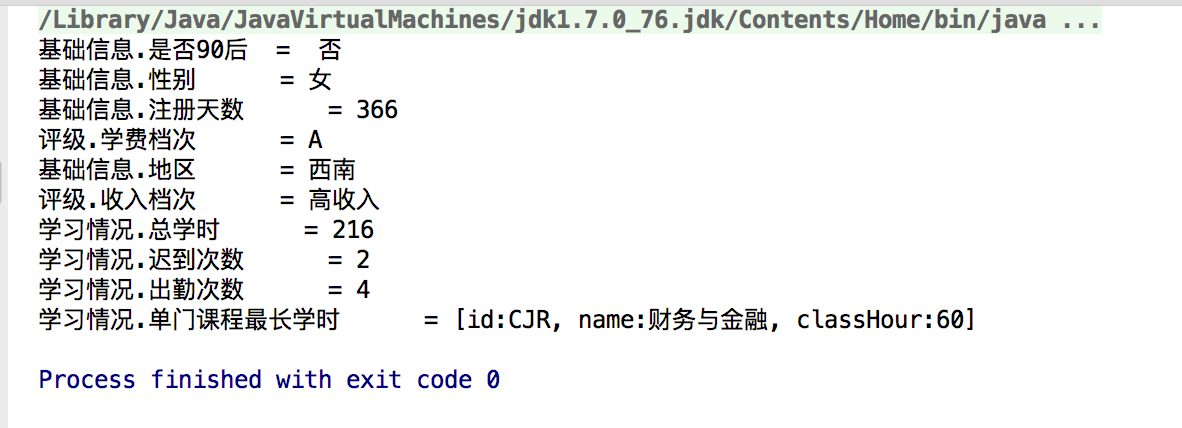
下一篇文章,我将实现这段脚本的动态配置,并且嵌入到java中。
希望此文能够抛砖引玉。
转载于:https://my.oschina.net/skymozn/blog/828930
最后
以上就是甜美裙子最近收集整理的关于Java内嵌Groovy脚本引擎进行业务规则剥离(一)的全部内容,更多相关Java内嵌Groovy脚本引擎进行业务规则剥离(一)内容请搜索靠谱客的其他文章。








发表评论 取消回复