最近在使用Java8的新特性stream,因为LZ也在使用Spark,所以这种流式编程还是蛮顺手的,比以前的循环处理方便很多。stream基本用法网上有很多教程,这里就不在赘述了。这里LZ重点介绍stream的collect方法和其强大的工具类Collector。
先看下接口中声名的collect方法:
R collect(Collector super T, A, R> collector);
R collect(Supplier supplier,
BiConsumer accumulator,
BiConsumer combiner);
1
2
3
4
5
Rcollect(Collector<?superT ,A,R>collector);
Rcollect(Suppliersupplier,
BiConsumeraccumulator,
BiConsumercombiner);
第一个方法比较常用,比如将stream转化为集合:
Stream stream = Stream.of("I", "love", "you", "too");
List list = stream.collect(Collectors.toList());
1
2
3
Streamstream=Stream.of("I","love","you","too");
Listlist=stream.collect(Collectors.toList());
其中Collectors类中提供了许多Collector接口的默认实现,这些实现能满足大部分的需求,否则要自己来实现Collector接口。Collector接口的3个泛型分别表示:
T:输入元素类型(上例中的集合元素类型String)
A:缩减操作的可变累积类型(上例中不存在)
R:可变减少操作的结果类型(上例中的集合类型List)
这个方法是将N个输入元素T转化为1个输出元素R的过程,比如算平均数:
Stream stream = Stream.of(1, 2, 3, 4, 5);
double d = stream.collect(Collectors.averagingInt(i -> i));
1
2
3
Streamstream=Stream.of(1,2,3,4,5);
doubled=stream.collect(Collectors.averagingInt(i->i));
还有更复杂的groupby操作:
// Student {id, classId, score}
List list = ...;
Map map =
list.stream().collect(Collectors.groupingBy(Student::getClassId,
Collectors.averagingInt(Student::getScore)));
1
2
3
4
5
6
// Student {id, classId, score}
Listlist=...;
Mapmap=
list.stream().collect(Collectors.groupingBy(Student::getClassId,
Collectors.averagingInt(Student::getScore)));
第二个方法稍微复杂些,下面是该方法几个参数的接口:
@FunctionalInterface
public interface Supplier {
T get();
}
1
2
3
4
5
@FunctionalInterface
publicinterfaceSupplier{
Tget();
}
supplier用来创建最终的结果类型R(第一个例子中的List)
@FunctionalInterface
public interface BiConsumer {
void accept(T t, U u);
default BiConsumer andThen(BiConsumer super T, ? super U> after) {
Objects.requireNonNull(after);
return (l, r) -> {
accept(l, r);
after.accept(l, r);
};
}
}
1
2
3
4
5
6
7
8
9
10
11
12
@FunctionalInterface
publicinterfaceBiConsumer{
voidaccept(Tt,Uu);
defaultBiConsumerandThen(BiConsumer<?superT ,?superU>after){
Objects.requireNonNull(after);
return(l,r)->{
accept(l,r);
after.accept(l,r);
};
}
}
accumulator和combiner都实现了上面的接口,accumulator用来将输入元素转化为中间元素(第一个例子中将String插入List,T->A。这个例子中的中间元素和结果元素的类型相同)。combiner用来将中间元素转化为结果元素(第一个例子中将多个List合并为一个List,A->R),下图为整个合并的过程:
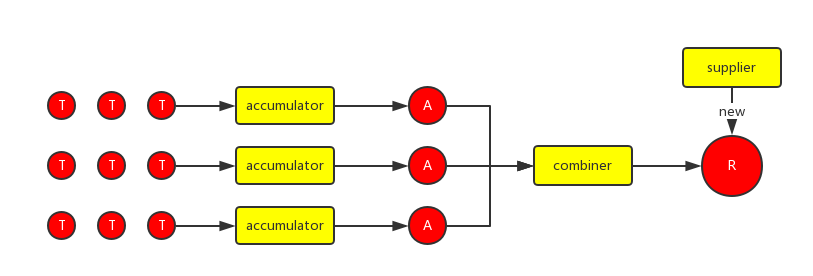
用这种方式改写下第一个例子:
Stream stream = Stream.of("I", "love", "you", "too");
List list = stream.collect(() -> {
return new ArrayList();
}, (List list0, String str) -> {
list0.add(str);
}, (List list1, List list2) -> {
list1.addAll(list2);
});
1
2
3
4
5
6
7
8
9
Streamstream=Stream.of("I","love","you","too");
Listlist=stream.collect(()->{
returnnewArrayList();
},(Listlist0,Stringstr)->{
list0.add(str);
},(Listlist1,Listlist2)->{
list1.addAll(list2);
});
最后
以上就是粗心野狼最近收集整理的关于java stream collec,Java stream的collect和Collector的全部内容,更多相关java内容请搜索靠谱客的其他文章。








发表评论 取消回复