转自Stream系列:
- Java 8系列之Stream的基本语法详解
- Java 8系列之Stream的强大工具Collector
- Java 8系列之重构和定制收集器
- Java 8系列之Stream中万能的reduce
概述
前面我们使用过collect(toList()),在流中生成列表。实际开发过程中,List又是我们经常用到的数据结构,但是有时候我们也希望Stream能够转换生成其他的值,比如Map或者set,甚至希望定制生成想要的数据结构。
collect也就是收集器,是Stream一种通用的、从流生成复杂值的结构。只要将它传给collect方法,也就是所谓的转换方法,其就会生成想要的数据结构。这里不得不提下,Collectors这个工具库,在该库中封装了相应的转换方法。当然,Collectors工具库仅仅封装了常用的一些情景,如果有特殊需求,那就要自定义了。
显然,List是能想到的从流中生成的最自然的数据结构, 但是有时人们还希望从流生成其他值, 比如 Map 或 Set, 或者你希望定制一个类将你想要的东西抽象出来。
前面已经讲过,仅凭流上方法的签名,就能判断出这是否是一个及早求值的操作。 reduce操作就是一个很好的例子, 但有时人们希望能做得更多。
这就是收集器,一种通用的、从流生成复杂值的结构。只要将它传给collect 方法,所有的流就都可以使用它了。
<R, A> R collect(Collector<? super T, A, R> collector);
<R> R collect(Supplier<R> supplier,
BiConsumer<R, ? super T> accumulator,
BiConsumer<R, R> combiner);
辅助接口
Supplier
Supplier<T>接口是一个函数接口,该接口声明了一个get方法,主要用来创建返回一个指定数据类型的对象。
T:指定的数据类型
@FunctionalInterface
public interface Supplier {
T get();
}
BiConsumer
BiConsumer<T, U>接口是一个函数接口,该接口声明了accept方法,并无返回值,该函数接口主要用来声明一些预期操作。
同时,该接口定义了一个默认方法andThen,该方法接受一个BiConsumer,并返回一个组合的BiConsumer,其会按照顺序执行操作。如果执行任一操作抛出异常,则将其传递给组合操作的调用者。 如果执行此操作抛出异常,将不执行后操作(after)。
@FunctionalInterface
public interface BiConsumer<T, U> {
void accept(T t, U u);
default BiConsumer<T, U> andThen(BiConsumer<? super T, ? super U> after) {
Objects.requireNonNull(after);
return (l, r) -> {
accept(l, r);
after.accept(l, r);
};
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
BinaryOperator
BinaryOperator接口继承于BiFunction接口,该接口指定了apply方法执行的参数类型及返回值类型均为T。
@FunctionalInterface
public interface BinaryOperator<T> extends BiFunction<T,T,T> {
public static <T> BinaryOperator<T> minBy(Comparator<? super T> comparator) {
Objects.requireNonNull(comparator);
return (a, b) -> comparator.compare(a, b) <= 0 ? a : b;
}
public static <T> BinaryOperator<T> maxBy(Comparator<? super T> comparator) {
Objects.requireNonNull(comparator);
return (a, b) -> comparator.compare(a, b) >= 0 ? a : b;
}
}
@FunctionalInterface
public interface BiFunction<T, U, R> {
R apply(T t, U u);
default <V> BiFunction<T, U, V> andThen(Function<? super R, ? extends V> after) {
Objects.requireNonNull(after);
return (T t, U u) -> after.apply(apply(t, u));
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
Function
Funtion是一个函数接口,其内定义了一个转换函数,将T转换为R。比如Stream中的map方法便是接受该函数参数,将T转换为R。
@FunctionalInterface
public interface Function<T, R> {
/**
* 转换函数,将T转换为R
*/
R apply(T t);
/**
* 返回一个组合函数Function,首先执行before,然后再执行该Function
*
* 如果两个函数的求值都抛出异常,它将被中继到组合函数的调用者。
* 如果before为null,将会抛出NullPointerException
*/
default <V> Function<V, R> compose(Function<? super V, ? extends T> before) {
Objects.requireNonNull(before);
return (V v) -> apply(before.apply(v));
}
/**
* 返回一个组合函数Function,首先执行Function,然后再执行after
*
* 如果两个函数的求值都抛出异常,它将被中继到组合函数的调用者。
* 如果after为null,将会抛出NullPointerException
*/
default <V> Function<T, V> andThen(Function<? super R, ? extends V> after) {
Objects.requireNonNull(after);
return (T t) -> after.apply(apply(t));
}
/**
* 将输入参数返回的函数
*/
static <T> Function<T, T> identity() {
return t -> t;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
Collector
Collector是Stream的可变减少操作接口,可变减少操作包括:将元素累积到集合中,使用StringBuilder连接字符串;计算元素相关的统计信息,例如sum,min,max或average等。Collectors(类收集器)提供了许多常见的可变减少操作的实现。
Collector<T, A, R>接受三个泛型参数,对可变减少操作的数据类型作相应限制:
- T:输入元素类型
- A:缩减操作的可变累积类型(通常隐藏为实现细节)
- R:可变减少操作的结果类型
Collector接口声明了4个函数,这四个函数一起协调执行以将元素目累积到可变结果容器中,并且可以选择地对结果进行最终的变换.
- Supplier<A> supplier(): 创建新的结果结
- BiConsumer<A, T> accumulator(): 将元素添加到结果容器
- BinaryOperator<A> combiner(): 将两个结果容器合并为一个结果容器
- Function<A, R> finisher(): 对结果容器作相应的变换
在Collector接口的characteristics方法内,可以对Collector声明相关约束
- Set<Characteristics> characteristics():
而Characteristics是Collector内的一个枚举类,声明了CONCURRENT、UNORDERED、IDENTITY_FINISH等三个属性,用来约束Collector的属性。
- CONCURRENT:表示此收集器支持并发,意味着允许在多个线程中,累加器可以调用结果容器
- UNORDERED:表示收集器并不按照Stream中的元素输入顺序执行
IDENTITY_FINISH:表示finisher实现的是识别功能,可忽略。
注:- 如果一个容器仅声明CONCURRENT属性,而不是UNORDERED属性,那么该容器仅仅支持无序的Stream在多线程中执行。
身份约束和相关性约束
Stream可以顺序执行,或者并发执行,或者顺序并发执行,为了保证Stream可以产生相同的结果,收集器函数必须满足身份约束和相关项约束。
身份约束说,对于任何部分累积的结果,将其与空结果容器组合必须产生等效结果。也就是说,对于作为任何系列的累加器和组合器调用的结果的部分累加结果a,a必须等于combiner.apply(a,supplier.get())。
相关性约束说,分裂计算必须产生等效的结果。也就是说,对于任何输入元素t1和t2,以下计算中的结果r1和r2必须是等效的:
A a1 = supplier.get();
accumulator.accept(a1,t1);
accumulator.accept(a1,t2);
R r1 = finisher.apply(a1); // result without splitting
A a2 = supplier.get();
accumulator.accept(a2,t1);
A a3 = supplier.get();
accumulator.accept(a3,t2);
R r2 = finisher.apply(combiner.apply(a2,a3));
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
创建Collector
自定义Collector
Java 8系列之重构和定制收集器
基于Collector工具库
在Collector工具库中,声明了许多常用的收集器,以供我们快速创建一个收集器。前面我们已经了解到,收集器函数必须满足身份约束和相关项约束。而基于Collector实现简化的库(如Stream.collect(Collector))创建收集器时,必须遵守以下约束:
- 第一个参数传递给accumulator()函数,两个参数都传递给combiner()函数,传递给finisher()函数的参数必须是上一次调用supplier(),accumulator()或combiner()函数的结果。
- 实现不应该对任何accumulator(),combiner()或finisher()函数的结果做任何事情,除非收集器将返回的结果返回给调用者
- 如果结果传递到combiner()或finisher()函数,而且返回对象与传入的不相同,则不会再将对象传递给accumulator()函数调用。
- 一旦结果传递到combiner()或finisher()函数,它就不会再次传递到accumulator()函数。
- 对于串行收集器,supplier(),accumulator()或combiner()函数返回的任何结果必须是限制串行的。这使得收集器可以并行进行,而收集器不需要执行任何额外的同步。reduce操作实现必须管理Stream的元素被正确区别并分别处理,并且仅在累积完成之后,对累加器中的数据合并。
- 对于并发收集器,实现可以自由地(但不是必须)同时实现reduce操作。accumulator()可以在多个线程同时调用,而不是在累积期间保持结果的独立性。仅当收集器具有Collector.Characteristics.UNORDERED特性或者原始数据是无序的时才应用并发还原。
转换成其他集合
对于前面提到了很多Stream的链式操作,但是,我们总是要将Strea生成一个集合,比如:
- 已有代码是为集合编写的, 因此需要将流转换成集合传入;
- 在集合上进行一系列链式操作后, 最终希望生成一个值;
- 写单元测试时, 需要对某个具体的集合做断言。
有些Stream可以转成集合,比如前面提到toList,生成了java.util.List 类的实例。当然了,还有还有toSet和toCollection,分别生成 Set和Collection 类的实例。
toList
示例:
List<Integer> collectList = Stream.of(1, 2, 3, 4)
.collect(Collectors.toList());
System.out.println("collectList: " + collectList);
// 打印结果
// collectList: [1, 2, 3, 4]
- 1
- 2
- 3
- 4
- 5
- 6
toSet
示例:
Set<Integer> collectSet = Stream.of(1, 2, 3, 4)
.collect(Collectors.toSet());
System.out.println("collectSet: " + collectSet);
// 打印结果
// collectSet: [1, 2, 3, 4]
- 1
- 2
- 3
- 4
- 5
- 6
toCollection
通常情况下,创建集合时需要调用适当的构造函数指明集合的具体类型:
List<Artist> artists = new ArrayList<>();
- 1
- 2
但是调用toList或者toSet方法时,不需要指定具体的类型,Stream类库会自动推断并生成合适的类型。当然,有时候我们对转换生成的集合有特定要求,比如,希望生成一个TreeSet,而不是由Stream类库自动指定的一种类型。此时使用toCollection,它接受一个函数作为参数, 来创建集合。
值得我们注意的是,看Collectors的源码,因为其接受的函数参数必须继承于Collection,也就是意味着Collection并不能转换所有的继承类,最明显的就是不能通过toCollection转换成Map
toMap
如果生成一个Map,我们需要调用toMap方法。由于Map中有Key和Value这两个值,故该方法与toSet、toList等的处理方式是不一样的。toMap最少应接受两个参数,一个用来生成key,另外一个用来生成value。toMap方法有三种变形:
toMap(Function<? super T, ? extends K> keyMapper,Function<? super T, ? extends U> valueMapper)
- keyMapper: 该Funtion用来生成Key
- valueMapper:该Funtion用来生成value
注:若Stream中有重复的值,导致Map中key重复,在运行时会报异常java.lang.IllegalStateException: Duplicate key **
toMap(Function
转成值
使用collect可以将Stream转换成值。maxBy和minBy允许用户按照某个特定的顺序生成一个值。
- averagingDouble:求平均值,Stream的元素类型为double
- averagingInt:求平均值,Stream的元素类型为int
- averagingLong:求平均值,Stream的元素类型为long
- counting:Stream的元素个数
- maxBy:在指定条件下的,Stream的最大元素
- minBy:在指定条件下的,Stream的最小元素
- reducing: reduce操作
- summarizingDouble:统计Stream的数据(double)状态,其中包括count,min,max,sum和平均。
- summarizingInt:统计Stream的数据(int)状态,其中包括count,min,max,sum和平均。
- summarizingLong:统计Stream的数据(long)状态,其中包括count,min,max,sum和平均。
- summingDouble:求和,Stream的元素类型为double
- summingInt:求和,Stream的元素类型为int
- summingLong:求和,Stream的元素类型为long
示例:
Optional<Integer> collectMaxBy = Stream.of(1, 2, 3, 4)
.collect(Collectors.maxBy(Comparator.comparingInt(o -> o)));
System.out.println("collectMaxBy:" + collectMaxBy.get());
// 打印结果
// collectMaxBy:4
- 1
- 2
- 3
- 4
- 5
- 6
分割数据块
collect的一个常用操作将Stream分解成两个集合。假如一个数字的Stream,我们可能希望将其分割成两个集合,一个是偶数集合,另外一个是奇数集合。我们首先想到的就是过滤操作,通过两次过滤操作,很简单的就完成了我们的需求。
但是这样操作起来有问题。首先,为了执行两次过滤操作,需要有两个流。其次,如果过滤操作复杂,每个流上都要执行这样的操作, 代码也会变得冗余。
这里我们就不得不说Collectors库中的partitioningBy方法,它接受一个流,并将其分成两部分:使用Predicate对象,指定条件并判断一个元素应该属于哪个部分,并根据布尔值返回一个Map到列表。因此对于key为true所对应的List中的元素,满足Predicate对象中指定的条件;同样,key为false所对应的List中的元素,不满足Predicate对象中指定的条件
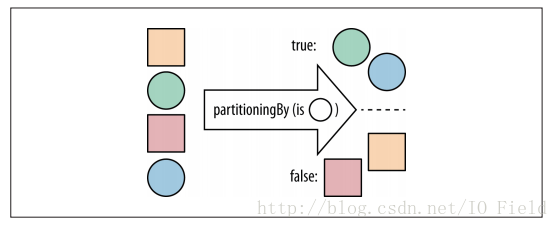
这样,使用partitioningBy,我们就可以将数字的Stream分解成奇数集合和偶数集合了。
Map<Boolean, List<Integer>> collectParti = Stream.of(1, 2, 3, 4)
.collect(Collectors.partitioningBy(it -> it % 2 == 0));
System.out.println("collectParti : " + collectParti);
// 打印结果
// collectParti : {false=[1, 3], true=[2, 4]}
- 1
- 2
- 3
- 4
- 5
- 6
数据分组
数据分组是一种更自然的分割数据操作, 与将数据分成true和false两部分不同,可以使用任意值对数据分组。
调用Stream的collect方法,传入一个收集器,groupingBy接受一个分类函数,用来对数据分组,就像partitioningBy一样,接受一个
Predicate对象将数据分成true和false两部分。我们使用的分类器是一个Function对象,和map操作用到的一样。
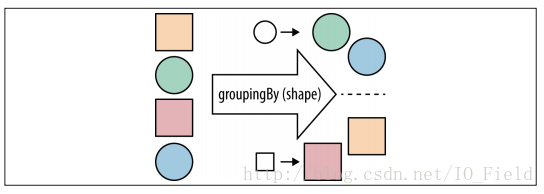
示例:
Map<Boolean, List<Integer>> collectGroup= Stream.of(1, 2, 3, 4)
.collect(Collectors.groupingBy(it -> it > 3));
System.out.println("collectGroup : " + collectGroup);
// 打印结果
// collectGroup : {false=[1, 2, 3], true=[4]}
- 1
- 2
- 3
- 4
- 5
- 6
注:
看groupingBy和partitioningBy的例子,他们的效果都是一样的,都是将Stream的数据进行了分割处理并返回一个Map。可能举的例子给你带来了误区,实际上他们两个完全是不一样的。
- partitioningBy是根据指定条件,将Stream分割,返回的Map为Map
字符串
有时候,我们将Stream的元素(String类型)最后生成一组字符串。比如在Stream.of(“1”, “2”, “3”, “4”)中,将Stream格式化成“1,2,3,4”。
如果不使用Stream,我们可以通过for循环迭代实现。
ArrayList<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
StringBuilder sb = new StringBuilder();
for (Integer it : list) {
if (sb.length() > 0) {
sb.append(",");
}
sb.append(it);
}
System.out.println(sb.toString());
// 打印结果
// 1,2,3,4
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
在Java 1.8中,我们可以使用Stream来实现。这里我们将使用 Collectors.joining 收集Stream中的值,该方法可以方便地将Stream得到一个字符串。joining函数接受三个参数,分别表示允(用以分隔元素)、前缀和后缀。
示例:
String strJoin = Stream.of("1", "2", "3", "4")
.collect(Collectors.joining(",", "[", "]"));
System.out.println("strJoin: " + strJoin);
// 打印结果
// strJoin: [1,2,3,4]
- 1
- 2
- 3
- 4
- 5
- 6
组合Collector
前面,我们已经了解到Collector的强大,而且非常的使用。如果将他们组合起来,是不是更厉害呢?看前面举过的例子,在数据分组时,我们是得到的分组后的数据列表 collectGroup : {false=[1, 2, 3], true=[4]}。如果我们的要求更高点,我们不需要分组后的列表,只要得到分组后列表的个数就好了。
这时候,很多人下意识的都会想到,便利Map就好了,然后使用list.size(),就可以轻松的得到各个分组的列表个数。
// 分割数据块
Map<Boolean, List<Integer>> collectParti = Stream.of(1, 2, 3, 4)
.collect(Collectors.partitioningBy(it -> it % 2 == 0));
Map<Boolean, Integer> mapSize = new HashMap<>();
collectParti.entrySet()
.forEach(entry -> mapSize.put(entry.getKey(), entry.getValue().size()));
System.out.println("mapSize : " + mapSize);
// 打印结果
// mapSize : {false=2, true=2}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
在partitioningBy方法中,有这么一个变形:
Map<Boolean, Long> partiCount = Stream.of(1, 2, 3, 4)
.collect(Collectors.partitioningBy(it -> it.intValue() % 2 == 0,
Collectors.counting()));
System.out.println("partiCount: " + partiCount);
// 打印结果
// partiCount: {false=2, true=2}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
在partitioningBy方法中,我们不仅传递了条件函数,同时传入了第二个收集器,用以收集最终结果的一个子集,这些收集器叫作下游收集器。收集器是生成最终结果的一剂配方,下游收集器则是生成部分结果的配方,主收集器中会用到下游收集器。这种组合使用收集器的方式, 使得它们在 Stream 类库中的作用更加强大。
那些为基本类型特殊定制的函数,如averagingInt、summarizingLong等,事实上和调用特殊Stream上的方法是等价的,加上它们是为了将它们当作下游收集器来使用的。
最后
以上就是明理夏天最近收集整理的关于Java 8系列之Stream的强大工具Collector概述辅助接口Collector身份约束和相关性约束创建Collector转换成其他集合转成值分割数据块数据分组字符串组合Collector的全部内容,更多相关Java内容请搜索靠谱客的其他文章。








发表评论 取消回复