使用云上GPU资源训练一个图像分类模型
- 一、使用前提
- 二、连接和初始化工作区
- 三、创建试验
- 四、创建计算资源
- 五、数据集
- 下载MNIST数据集
- 示例图片
- 创建和注册数据集
- 六、创建运行脚本
- 七、设置试验运行环境
- 设置试验Python环境
- TensorFlow估计器(Estimator)
- 八、提交试验
- 九、监控试验运行状态
- 十、查看运行结果(Run object)
- 十一、下载模型
- 十二、在测试集上评估模型
- 十三、总结
在计算机视觉中使用GPU计算资源可以大大加速模型的训练过程。如果本地没有GPU资源,可以通过Azure机器学习利用Azure上的GPU计算集群。Azure上的计算集群支持并行计算,在有计算任务时启动节点,在完成任务后关闭节点。整个过程都是自动执行的,不仅加速了开发过程,也一定程度上节省了成本。
本节将演示使用Azure机器学习Python SDK 在多节点GPU计算集群上训练一个图像多分类模型,使用的框架为TensorFlow,使用的数据集为著名的MNIST数据集。整个过程都在Jupyter notebook中运行。
模型训练流程如下图所示,涉及到的 工作区、试验、计算集群、Azure机器学习studio等概念,如果不清楚,请查阅: Azure机器学习(理论篇)——Azure机器学习介绍。
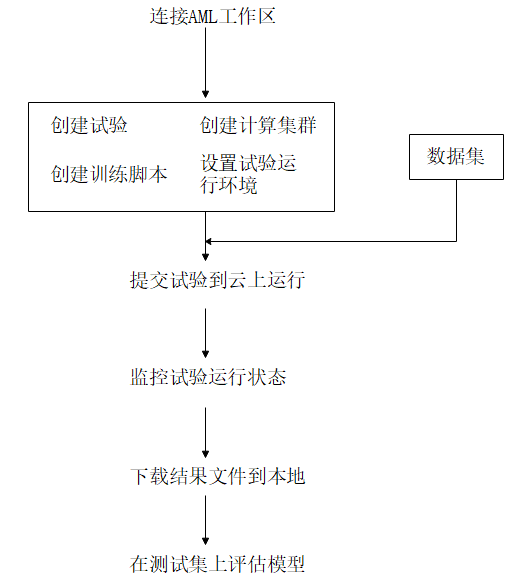
图1 使用Azure机器学习训练模型流程
一、使用前提
在开始本节内容之前,你需要:
- Azure 订阅和Azure机器学习工作区。创建方法:Azure机器学习(实战篇)——创建Azure机器学习服务
- 配置Azure机器学习开发环境。配置方法:Azure机器学习(实战篇)——配置 Azure 机器学习开发环境
查看Azure机器学习版本:
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
import azureml.core
from azureml.core import Workspace
# check core SDK version number
print("Azure ML SDK Version: ", azureml.core.VERSION)输出:
SDK version: 1.0.85二、连接和初始化工作区
整个训练过程都是在Azure机器学习工作区内开展的。所以第一步是要连接到工作区。如果还没有工作区,请先创建一个,创建步骤详见:Azure机器学习(实战篇)——创建Azure机器学习服务的第二部分。
使用以下代码连接到Azure机器学习工作区:
ws = Workspace.from_config('config.json')
print('Workspace name: ' + ws.name, 'Azure region: ' + ws.location,
'Subscription id: ' + ws.subscription_id, 'Resource group: ' + ws.resource_group, sep = 'n')'config.json’是存在本地的连接工作区的配置文件,该文件生成方法详见:Azure机器学习(实战篇)——配置 Azure 机器学习开发环境的第四部分。
输出:

三、创建试验
在当前工作区中创建一个试验,以便在该试验下训练模型。
试验是工作区下面的一个逻辑容器,它涵盖了每一次模型训练的运行记录和结果信息。
from azureml.core import Experiment
experiment_name = 'tf-mnist'
experiment = Experiment(ws, name=experiment_name)试验创建成功后,可以在Azure机器学习studio中查看。
Azure机器学习studio是除Python SDK外使用Azure机器学习的另一种方式。
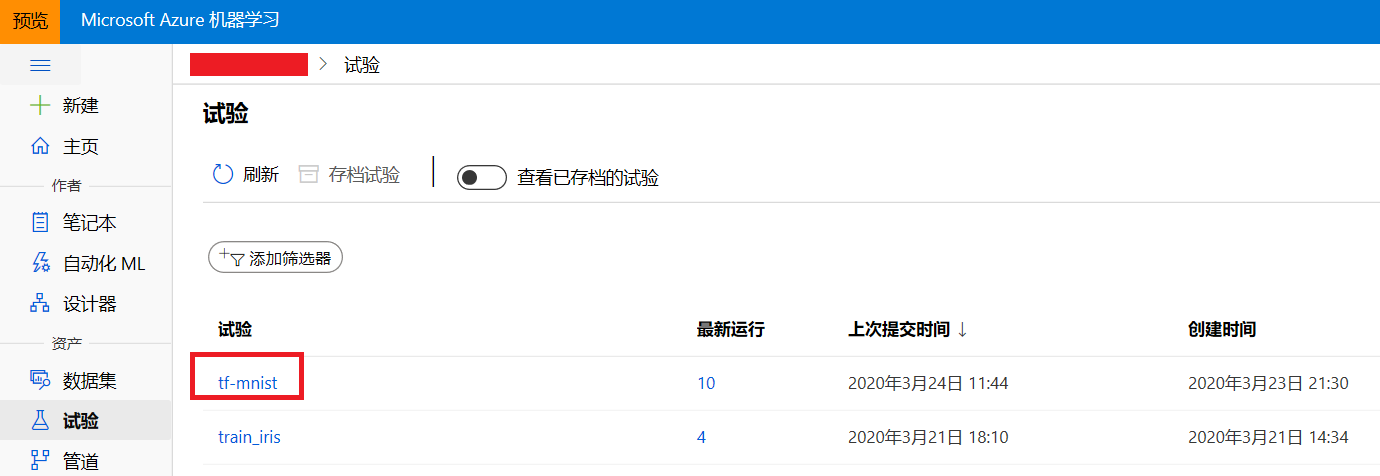
图2 在Azure机器学习studio中查看试验信息
四、创建计算资源
与本地训练不同,使用Azure机器学习可以利用云上的计算资源,将训练脚本提交到远程计算集群得到训练结果。
首先创建一个Azure机器学习托管的计算集群AmlCompute,该计算集群支持并行计算,在调参时候非常有用。
通过max_nodes和min_nodes定义集群中的最大和最小计算节点数目。代码中:
- vm_size=‘STANDARD_NC6’,表示计算集群中的节点是’STANDARD_NC6’规格的虚拟机,该系列虚拟机上有1个或者1个以上的NVIDIA Tesla K80 GPU。更多虚拟机规格请查看此链接。
- max_nodes=4,表示计算集群最大并行任务数为4;
- min_nodes=0,表示计算集群在没有任务时不会有节点运行,节约开销。
每个Azure订阅的计算集群节点数目都是有限制的,如果创建后的计算集群max_nodes没有达到目标节点数,那可能是已创建的计算集群用光了节点配额,你可以删除不用的计算集群或者申请更多的Azure计算集群节点配额。
from azureml.core.compute import AmlCompute
from azureml.core.compute import ComputeTarget
import os
# choose a name for your cluster
compute_name = os.environ.get("AML_COMPUTE_CLUSTER_NAME", "gpu-cluster")
compute_min_nodes = os.environ.get("AML_COMPUTE_CLUSTER_MIN_NODES", 0)
compute_max_nodes = os.environ.get("AML_COMPUTE_CLUSTER_MAX_NODES", 4)
# This example uses GPU VM. For using CPU VM, set SKU to STANDARD_D2_V2
vm_size = os.environ.get("AML_COMPUTE_CLUSTER_SKU", "STANDARD_NC6")
if compute_name in ws.compute_targets:
compute_target = ws.compute_targets[compute_name]
if compute_target and type(compute_target) is AmlCompute:
print("found compute target: " + compute_name)
else:
print("creating new compute target...")
provisioning_config = AmlCompute.provisioning_configuration(vm_size = vm_size,
min_nodes = compute_min_nodes,
max_nodes = compute_max_nodes)
# create the cluster
compute_target = ComputeTarget.create(ws, compute_name, provisioning_config)
# can poll for a minimum number of nodes and for a specific timeout.
# if no min node count is provided it will use the scale settings for the cluster
compute_target.wait_for_completion(show_output=True, min_node_count=None, timeout_in_minutes=20)
# For a more detailed view of current AmlCompute status, use get_status()
print(compute_target.get_status().serialize())可以在Azure机器学习studio中查看创建好的计算集群。
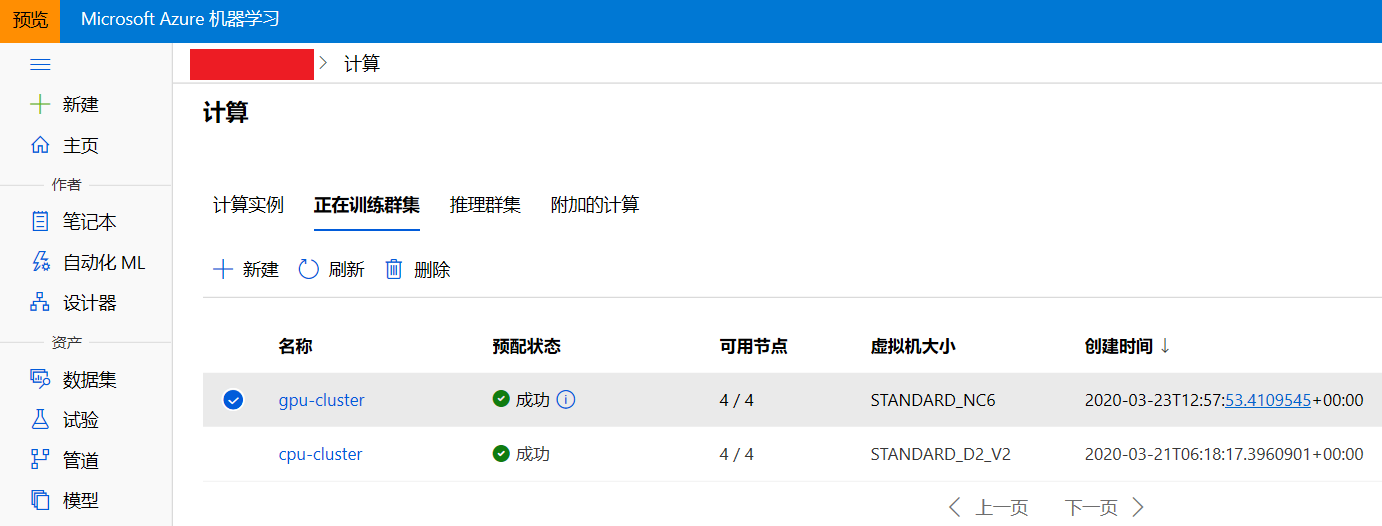
图3 在Azure机器学习studio中查看计算资源信息
也可以通过SDK来查询:
compute_targets = ws.compute_targets
for name, ct in compute_targets.items():
print(name, ct.type, ct.provisioning_state)输出:
cpu-cluster AmlCompute Succeeded
gpu-cluster AmlCompute Succeeded**注意:1 元试用订阅不支持创建GPU计算节点,如需使用云上GPU资源,需要充值成为标准预付费订阅。**具体内容请参考:1 元试用订阅详情。
五、数据集
下载MNIST数据集
从Yan LeCun’s website下载MNIST数据集到本地文件夹:
import urllib
os.makedirs('./data/mnist', exist_ok=True)
urllib.request.urlretrieve('http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz', filename = './data/mnist/train-images.gz')
urllib.request.urlretrieve('http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz', filename = './data/mnist/train-labels.gz')
urllib.request.urlretrieve('http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz', filename = './data/mnist/test-images.gz')
urllib.request.urlretrieve('http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz', filename = './data/mnist/test-labels.gz')示例图片
通过一个utils.py脚本文件将上述数据集压缩文件加载为numpy数组,utils.py保存在当前目录下,代码如下所示:
import gzip
import numpy as np
import struct
# load compressed MNIST gz files and return numpy arrays
def load_data(filename, label=False):
with gzip.open(filename) as gz:
struct.unpack('I', gz.read(4))
n_items = struct.unpack('>I', gz.read(4))
if not label:
n_rows = struct.unpack('>I', gz.read(4))[0]
n_cols = struct.unpack('>I', gz.read(4))[0]
res = np.frombuffer(gz.read(n_items[0] * n_rows * n_cols), dtype=np.uint8)
res = res.reshape(n_items[0], n_rows * n_cols)
else:
res = np.frombuffer(gz.read(n_items[0]), dtype=np.uint8)
res = res.reshape(n_items[0], 1)
return res
# one-hot encode a 1-D array
def one_hot_encode(array, num_of_classes):
return np.eye(num_of_classes)[array.reshape(-1)]随机显示30张图片及其标签:
from utils import load_data
# note we also shrink the intensity values (X) from 0-255 to 0-1. This helps the neural network converge faster.
X_train = load_data('./data/mnist/train-images.gz', False) / 255.0
y_train = load_data('./data/mnist/train-labels.gz', True).reshape(-1)
X_test = load_data('./data/mnist/test-images.gz', False) / 255.0
y_test = load_data('./data/mnist/test-labels.gz', True).reshape(-1)
count = 0
sample_size = 30
plt.figure(figsize = (16, 6))
for i in np.random.permutation(X_train.shape[0])[:sample_size]:
count = count + 1
plt.subplot(1, sample_size, count)
plt.axhline('')
plt.axvline('')
plt.text(x = 10, y = -10, s = y_train[i], fontsize = 18)
plt.imshow(X_train[i].reshape(28, 28), cmap = plt.cm.Greys)
plt.show()输出:

创建和注册数据集
将数据集创建和注册为 Azure 机器学习的数据集(Dataset)后,可以方便本地或远程试验访问。
数据集(Dataset)可以引用Azure Blob存储或者公共urls中任何格式的数据。创建数据集(Dataset),相当于创建了源数据集的引用,你可以通过数据集(Dataset)将源数据下载到本地或者mount到远程计算集群供其使用。数据始终存在原来的位置,不会占用额外的存储空间。
首先从公共urls获取数据集:
from azureml.core.dataset import Dataset
web_paths = ['http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz',
'http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz',
'http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz',
'http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz'
]
dataset = Dataset.File.from_files(path = web_paths)你可以将上述数据集(Dataset)注册到当前工作区,已注册的数据集可以给其他用户使用,也可以供工作区的其他试验重复使用,在脚本中只需要通过数据集的注册名字就可以轻松访问。详细内容请查看:Azure机器学习(实战篇)——数据集02:创建和注册数据集
dataset = dataset.register(workspace=ws,
name='mnist dataset',
description='training and test dataset',
create_new_version=True)
# list the files referenced by dataset
dataset.to_path()输出:
['/http/yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz',
'/http/yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz',
'/http/yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz',
'/http/yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz']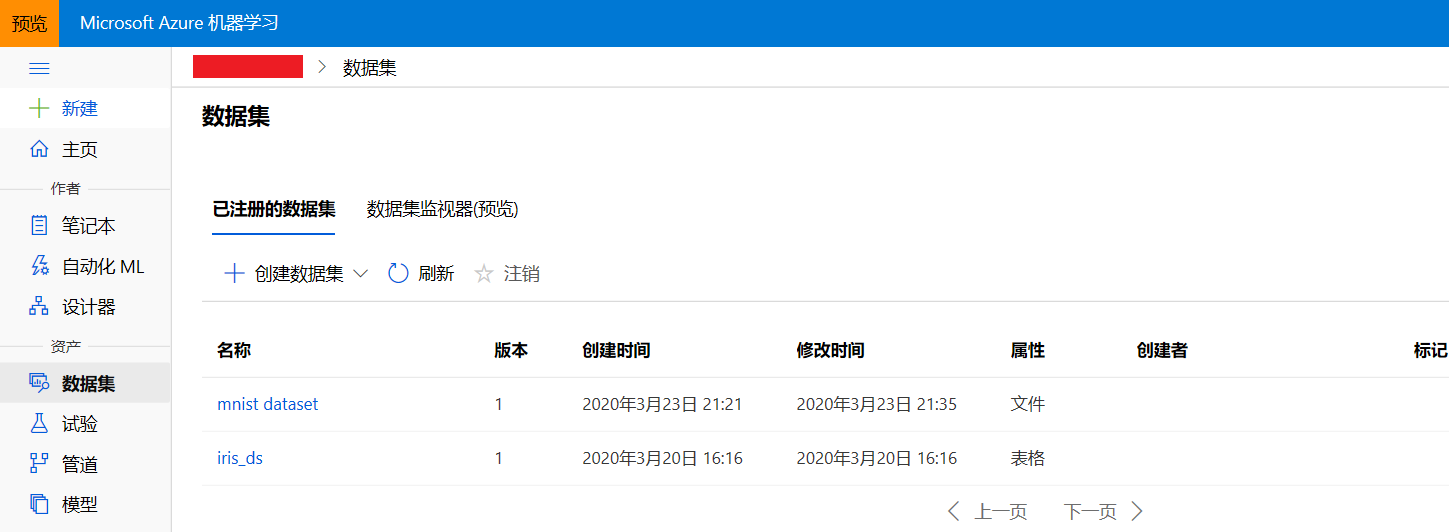
图4 Azure机器学习studio中已注册数据集
六、创建运行脚本
首先在本地创建一个文件夹,用来保存脚本及其所依赖的文件。
script_folder = './tf-mnist'
os.makedirs(script_folder, exist_ok=True)创建训练脚本tf_mnist.py,脚本代码如下:
import numpy as np
import argparse
import os
import tensorflow as tf
import glob
from azureml.core import Run
import sys
sys.path.append(".")
from utils import load_data
print("TensorFlow version:", tf.__version__)
parser = argparse.ArgumentParser()
parser.add_argument('--data-folder', type=str, dest='data_folder', help='data folder mounting point')
parser.add_argument('--batch-size', type=int, dest='batch_size', default=50, help='mini batch size for training')
parser.add_argument('--first-layer-neurons', type=int, dest='n_hidden_1', default=100,
help='# of neurons in the first layer')
parser.add_argument('--second-layer-neurons', type=int, dest='n_hidden_2', default=100,
help='# of neurons in the second layer')
parser.add_argument('--learning-rate', type=float, dest='learning_rate', default=0.01, help='learning rate')
args = parser.parse_args()
data_folder = args.data_folder
print('Data folder:', data_folder)
# load train and test set into numpy arrays
# note we scale the pixel intensity values to 0-1 (by dividing it with 255.0) so the model can converge faster.
X_train = load_data(glob.glob(os.path.join(data_folder, '**/train-images-idx3-ubyte.gz'),
recursive=True)[0], False) / 255.0
X_test = load_data(glob.glob(os.path.join(data_folder, '**/t10k-images-idx3-ubyte.gz'),
recursive=True)[0], False) / 255.0
y_train = load_data(glob.glob(os.path.join(data_folder, '**/train-labels-idx1-ubyte.gz'),
recursive=True)[0], True).reshape(-1)
y_test = load_data(glob.glob(os.path.join(data_folder, '**/t10k-labels-idx1-ubyte.gz'),
recursive=True)[0], True).reshape(-1)
print(X_train.shape, y_train.shape, X_test.shape, y_test.shape, sep='n')
training_set_size = X_train.shape[0]
n_inputs = 28 * 28
n_h1 = args.n_hidden_1
n_h2 = args.n_hidden_2
n_outputs = 10
learning_rate = args.learning_rate
n_epochs = 20
batch_size = args.batch_size
with tf.name_scope('network'):
# construct the DNN
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name='X')
y = tf.placeholder(tf.int64, shape=(None), name='y')
h1 = tf.layers.dense(X, n_h1, activation=tf.nn.relu, name='h1')
h2 = tf.layers.dense(h1, n_h2, activation=tf.nn.relu, name='h2')
output = tf.layers.dense(h2, n_outputs, name='output')
with tf.name_scope('train'):
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=output)
loss = tf.reduce_mean(cross_entropy, name='loss')
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
train_op = optimizer.minimize(loss)
with tf.name_scope('eval'):
correct = tf.nn.in_top_k(output, y, 1)
acc_op = tf.reduce_mean(tf.cast(correct, tf.float32))
init = tf.global_variables_initializer()
saver = tf.train.Saver()
# start an Azure ML run
run = Run.get_context()
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
# randomly shuffle training set
indices = np.random.permutation(training_set_size)
X_train = X_train[indices]
y_train = y_train[indices]
# batch index
b_start = 0
b_end = b_start + batch_size
for _ in range(training_set_size // batch_size):
# get a batch
X_batch, y_batch = X_train[b_start: b_end], y_train[b_start: b_end]
# update batch index for the next batch
b_start = b_start + batch_size
b_end = min(b_start + batch_size, training_set_size)
# train
sess.run(train_op, feed_dict={X: X_batch, y: y_batch})
# evaluate training set
acc_train = acc_op.eval(feed_dict={X: X_batch, y: y_batch})
# evaluate validation set
acc_val = acc_op.eval(feed_dict={X: X_test, y: y_test})
# log accuracies
run.log('training_acc', np.float(acc_train))
run.log('validation_acc', np.float(acc_val))
print(epoch, '-- Training accuracy:', acc_train, 'b Validation accuracy:', acc_val)
y_hat = np.argmax(output.eval(feed_dict={X: X_test}), axis=1)
run.log('final_acc', np.float(acc_val))
os.makedirs('./outputs/model', exist_ok=True)
# files saved in the "./outputs" folder are automatically uploaded into run history
saver.save(sess, './outputs/model/mnist-tf.model')将训练脚本tf_mnist.py和utils.py都移动到script_folder文件夹下面,确保script_folder文件夹下面有这两个脚本文件:
print(os.listdir(script_folder))输出:
['tf_mnist.py', 'utils.py']和本地训练相比,云上训练脚本有以下几处不同:
- –data_folder
通过传参的方式在训练脚本中指定数据集所在位置。
parser = argparse.ArgumentParser()
parser.add_argument('--data_folder')- run = Run.get_context()
脚本从azureml.core.run导入了Run这个类,接下来使用了Run.get_context()这个方法,该方法可以记录训练中的日志信息,比如模型参数、模型精度等。等训练完成后,可以到Web页面查看这些参数的可视化结果。
run.log('training_acc', np.float(acc_train))
run.log('validation_acc', np.float(acc_val))- ./outputs文件夹
远程计算集群在训练过程中保存的模型等文件将输出到这个文件夹中,而这个文件夹下面的文件又将会自动上传到run的“history file store”中。训练完成后,可以通过run.get_file_names()和run.download_file()下载这些结果文件。
七、设置试验运行环境
设置试验Python环境
由于云上计算集群的节点是以docker容器的形式运行计算任务,而不同的试验任务会使用不同的Python环境和依赖。所以对每次试验运行,我们都要先定义一个Python环境,然后根据该环境创建docker镜像,计算节点再使用这些docker镜像初始化容器并执行计算。
一般来说,直接使用Azure机器学习Python SDK中现成的SKLearn、PyTorch和TensorFlow等框架提交试验任务,任务的Python环境都会自动配置好,基本不需要自行设置。但是在Mooncake上创建docker镜像时,因为网络原因conda和pip从默认源获取资源的速度非常慢,因此我们用下面的代码自己设置试验运行需要的依赖包和更新conda和pip的国内源。
更详细的介绍请参考:Azure机器学习(实战篇)——配置 Azure 机器学习Python环境
from azureml.core.environment import Environment
from azureml.core.conda_dependencies import CondaDependencies
# to install required packages
env = Environment('tf-mnist-env')
cd = CondaDependencies.create(pip_packages=['tensorflow==1.10.0','numpy=1.13.3','azureml-dataprep[pandas,fuse]', 'azureml-defaults'])
env.python.conda_dependencies = cd
env.docker.enabled = True
# Specify docker steps as a string. Alternatively, load the string from a file.
dockerfile = r"""
FROM mcr.microsoft.com/azureml/base:intelmpi2018.3-ubuntu16.04
RUN conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/main/ &&
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/ &&
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/conda-forge/ &&
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/msys2/ &&
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/bioconda/ &&
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/menpo/ &&
conda config --set show_channel_urls yes
RUN pip install -U pip
RUN pip config set global.index-url http://mirrors.aliyun.com/pypi/simple
RUN pip config set install.trusted-host mirrors.aliyun.com
RUN echo "Hello from custom container!"
"""
# Set base image to None, because the image is defined by dockerfile.
env.docker.base_image = None
env.docker.base_dockerfile = dockerfile
# Register environment to re-use later
env.register(workspace = ws)如果中科大源报错就换成清华源或者上交大源。
TensorFlow估计器(Estimator)
由于使用TensorFlow框架来训练模型,这里我们从azureml.train导入了TensorFlow这个对象。
Azure机器学习Python SDK集成了SKLearn、PyTorch、TensorFlow等常用的训练框架,为了方便管理各个训练框架及其依赖包的版本更新和设置运行环境,Azure机器学习将他们在SDK中以各自的名字分开包装,但都在azureml.train这个目录下。

图5 Azure机器学习Python SDK中集成的训练框架
使用以下代码设置TensorFlow训练环境:
from azureml.train.dnn import TensorFlow
script_params = {
'--data-folder': dataset.as_named_input('mnist').as_mount(),
'--batch-size': 50,
'--first-layer-neurons': 300,
'--second-layer-neurons': 100,
'--learning-rate': 0.01
}
est = TensorFlow(source_directory=script_folder,
script_params=script_params,
compute_target=compute_target,
entry_script='tf_mnist.py',
environment_definition=env)TensorFlow的参数:
- source_directory是之前创建的本地文件夹,包含了tf_mnist.py和utils.py这两个脚本。
- script_params是脚本的参数,这里定义了深度学习网络的batch-size、learning-rate,以及网络第一层和第二层神经元个数,通过Dataset的as_mount()方法告诉了脚本数据集的所在位置。更多关于将数据集文件mount到计算资源的内容请查看:Azure机器学习(实战篇)——数据集03:在训练中使用数据集第六节。
- compute_target是本次训练用到的计算集群。这里我们用云上的计算集群,但你也可以选择其他计算目标类型,例如 Azure Vm,甚至是本地计算机。
- entry_script是训练模型的脚本的相对路径。
- Azure机器学习每次训练模型时都会创建docker容器来执行具体的计算,此处调用TensorFlow估计器对象,系统会使用一个已经安装好了TensorFlow的docker镜像。但是为了修改pip和conda的源,这里自己新建了一个环境env,用的是Azure机器学习的baseImage。
-
八、提交试验
运行以下代码将试验提交到云上进行计算:
run = experiment.submit(est)可以从studio中查看试验运行状态,每次运行都会生成一个运行id。
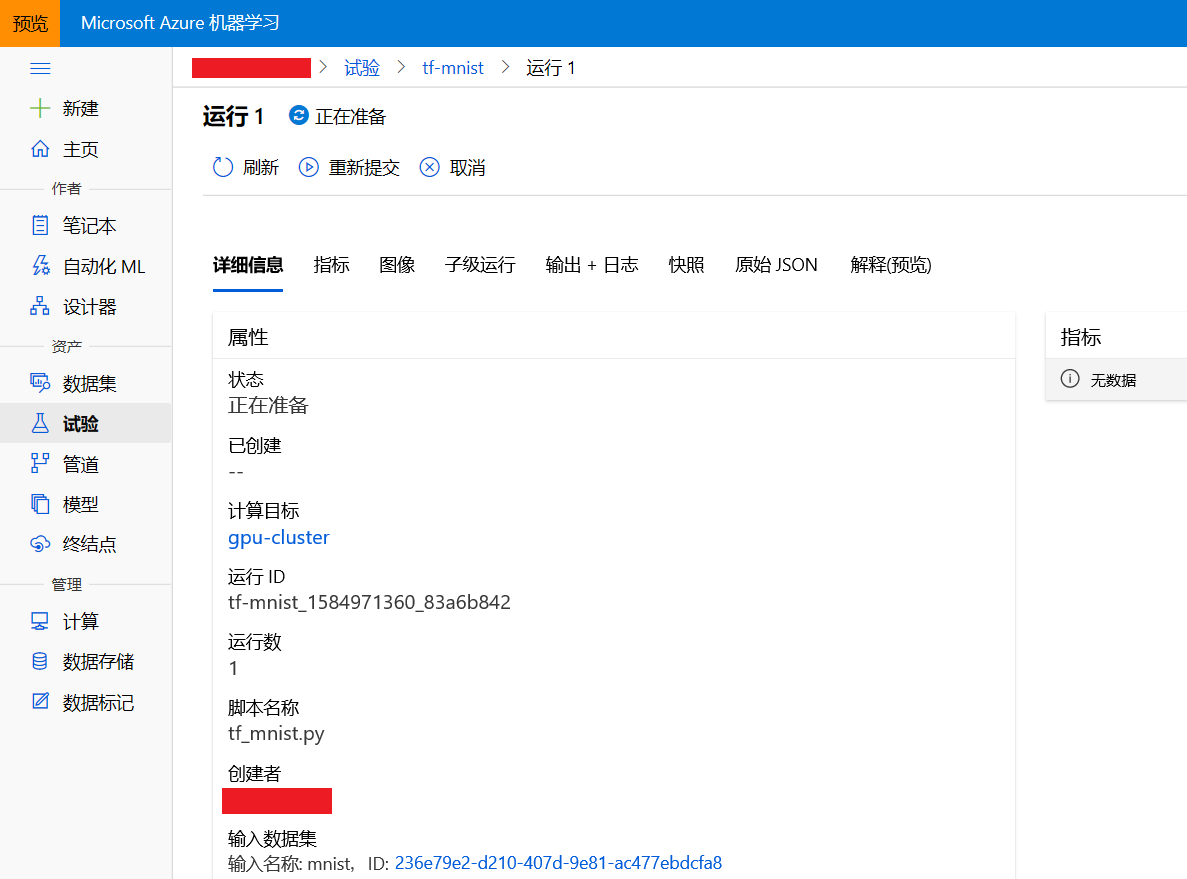
图6 试验运行正在准备
在图6中能够看到:
- 此次运行的详细信息:运行状态、计算目标、运行id等。
- 指标:模型的参数和评价指标。
- 输出+日志:可以看到训练的输出文件和日志文件,包括docker镜像的创建日志、job准备日志、模型训练日志和报错信息等。
试验运行经历以下阶段:
- 准备:提交试验后,试验会进入“正在准备”状态,此阶段主要是docker镜像的创建,如图7所示。可以看到,试验准备了大约8分钟,虽然时间不短,但是此次准备好的运行环境是可以给后面的试验重复使用的,后面再使用此环境时准备时间会大大缩短。
- 计算节点缩放:准备完成后,训练进入“已排队”状态。这是因为我们上面将计算集群的min_nodes设置为0,此时计算集群中没有节点在运行。计算集群接收到试验任务后,会逐渐启动试验所需要的计算节点,大概需要5分钟时间。虽然这样增加了训练时间,但是能够做到即用即付,可以节约成本,特别是GPU开销。
- 运行:source_directory文件夹中的所有脚本文件都会上传到计算节点,数据集也会mount给计算节点,然后节点执行entry_script。运行例是数据会被保存到run.log()中。
- 后处理:拷贝./outputs等文件夹到run的“history file store”中。
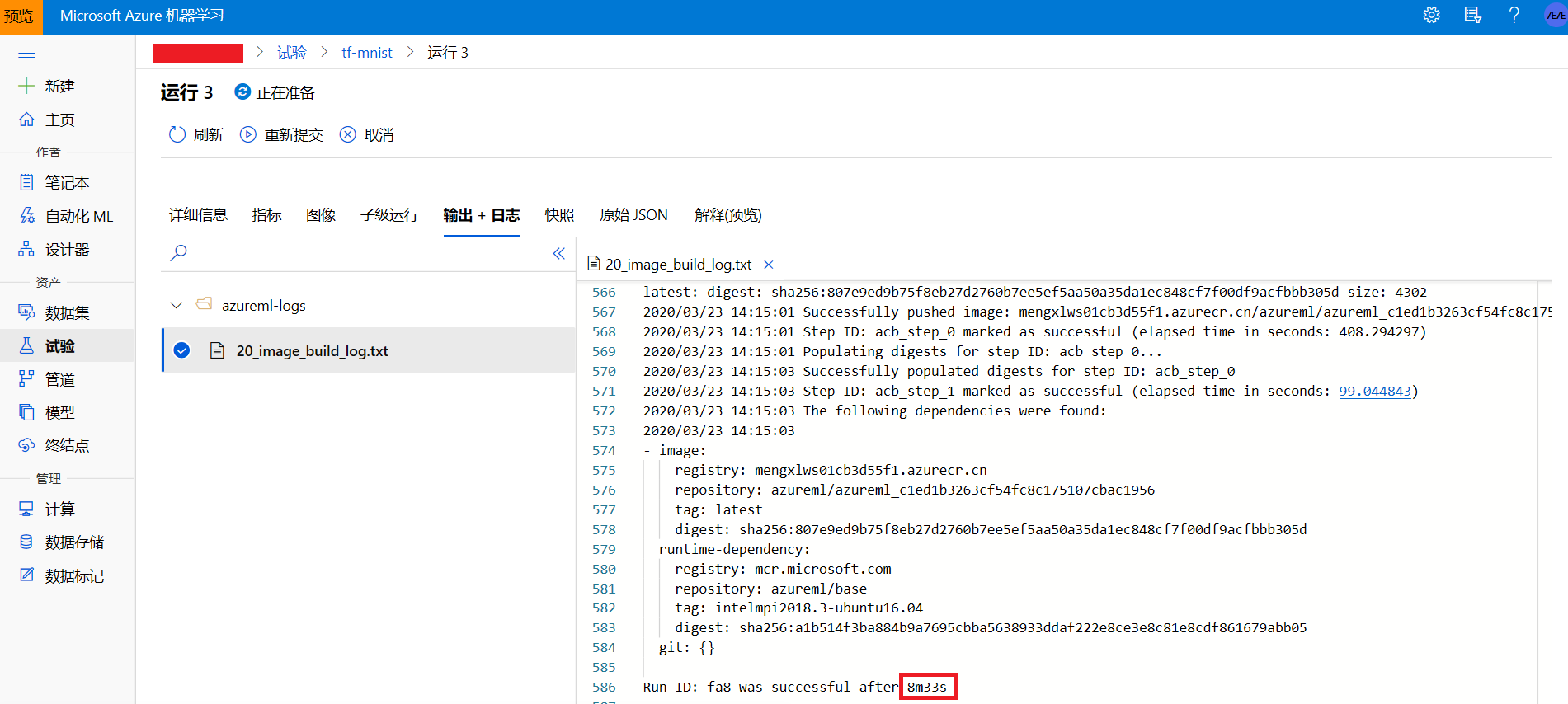
图7 试验准备期间创建docker镜像的输出日志
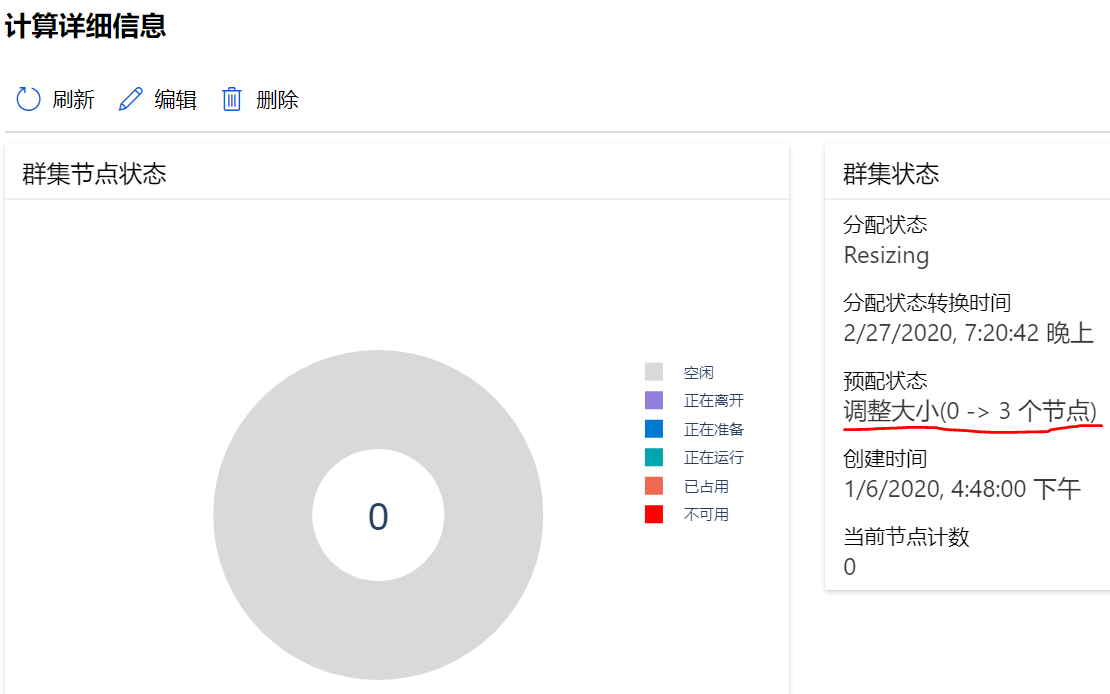
图8 计算节点正在启动(示例)
九、监控试验运行状态
我们既可以在像上面一样在studio中监控试验运行,也可以通过代码来查看试验运行状态。
使用以下代码可以在Jupyter widget中每隔10到15秒钟更新一次试验运行状态。
from azureml.widgets import RunDetails
RunDetails(run).show()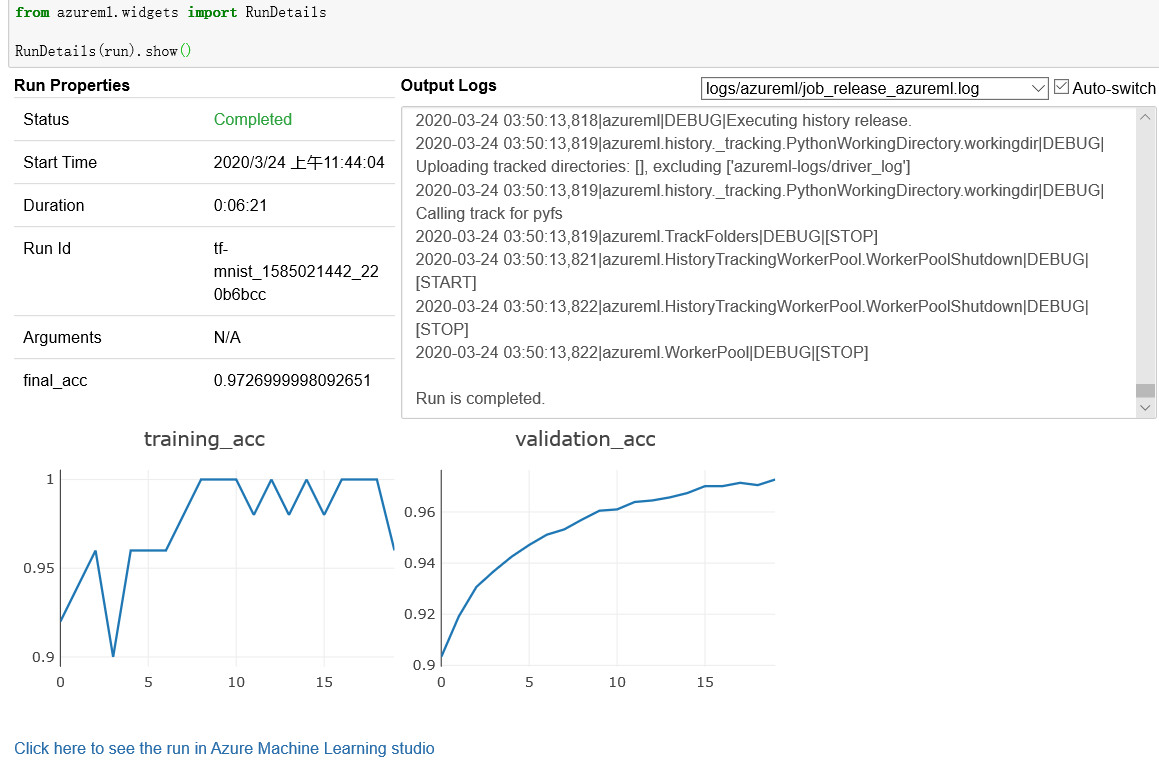
图8 通过SDK查看试验运行状态
在整个试验运行过程中,可以通过上图的小窗口查看试验状态、开始时间、运行时间、运行id、模型度量值和输出log日志等运行信息。
还可以通过run来查看试验状态并获得该试验的studio链接:
run输出:

在studio中同样可以看到图8中的运行信息:
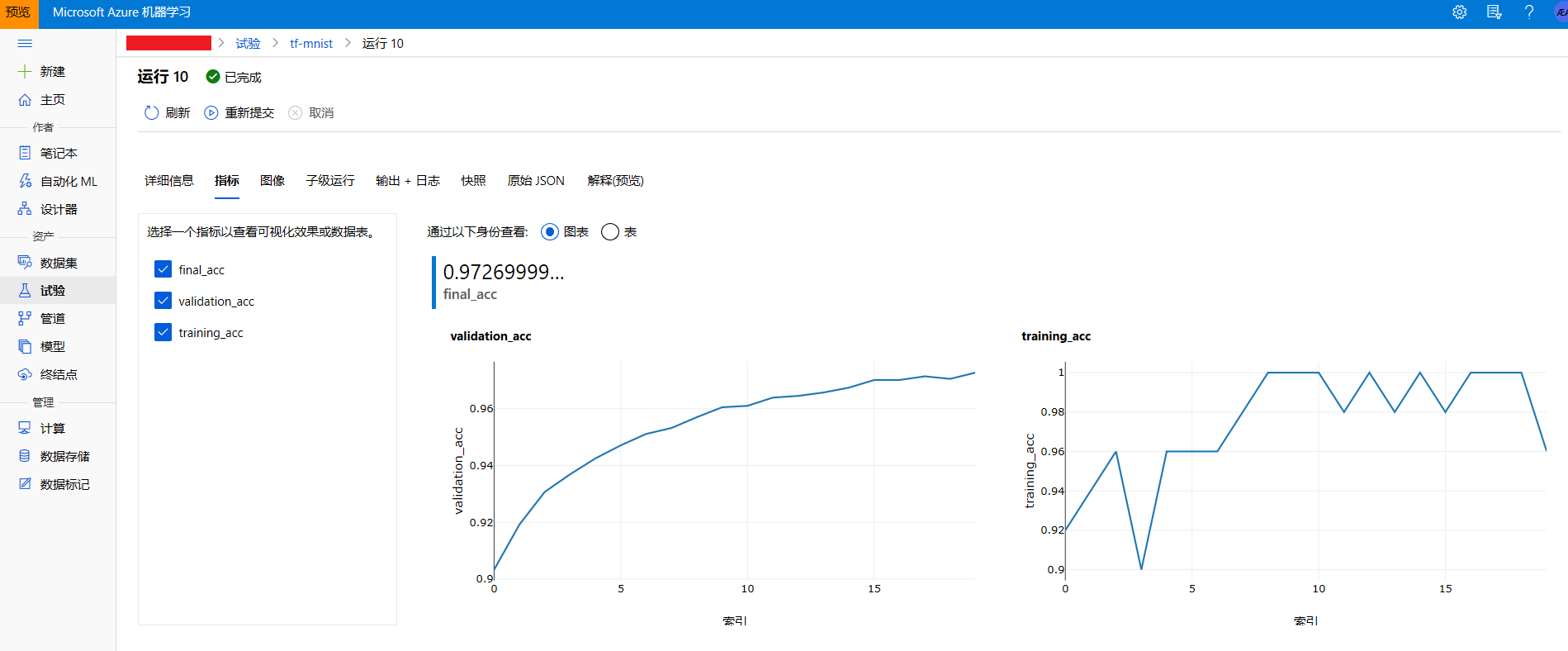
图9 在studio中查看模型指标
运行完成后可以使用wait_for_completion来打印试验运行日志信息:
# specify show_output to True for a verbose log
run.wait_for_completion(show_output=True) 十、查看运行结果(Run object)
可以通过run保存的运行记录查看试验结果。run提供了很多有用的方法,其中常用的有以下3个:
- run.get_details():返回运行详细信息。
- run.get_metrics(): 返回训练中记录的模型度量信息的字典。
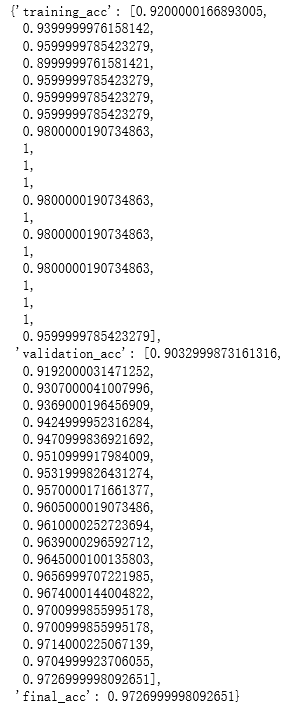
- run.get_file_names(): 返回一个list,其中包含了outputs和各种logs文件的路径。
['azureml-logs/55_azureml-execution-tvmps_114def75925c4721e3ea2a24a0adbc9d50d07b8fcf9e3fe2452e0b806752ed58_d.txt',
'azureml-logs/65_job_prep-tvmps_114def75925c4721e3ea2a24a0adbc9d50d07b8fcf9e3fe2452e0b806752ed58_d.txt',
'azureml-logs/70_driver_log.txt',
'azureml-logs/75_job_post-tvmps_114def75925c4721e3ea2a24a0adbc9d50d07b8fcf9e3fe2452e0b806752ed58_d.txt',
'azureml-logs/process_info.json',
'azureml-logs/process_status.json',
'logs/azureml/141_azureml.log',
'logs/azureml/job_prep_azureml.log',
'logs/azureml/job_release_azureml.log',
'outputs/model/checkpoint',
'outputs/model/mnist-tf.model.data-00000-of-00001',
'outputs/model/mnist-tf.model.index',
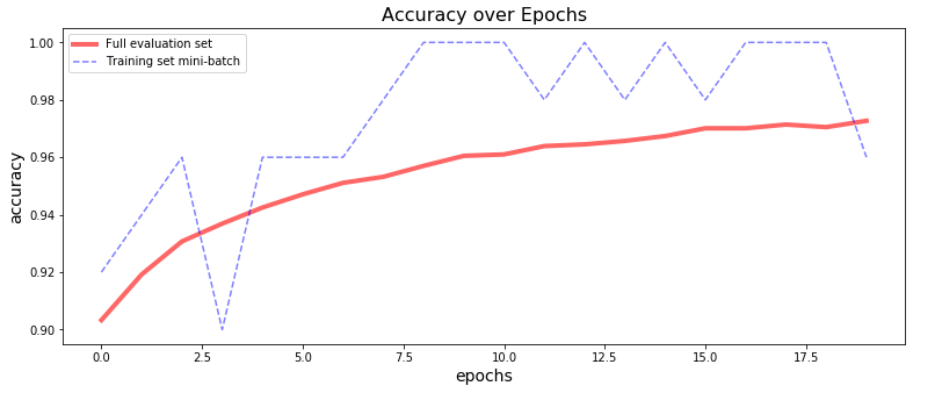
'outputs/model/mnist-tf.model.meta']我们可以使用上述返回的模型度量值绘制准确度和epoch的曲线,并使用run.log_image()将曲线也一并上传到Azure机器学习studio中,这样可以把运行相关信息都集中到一起方便查看。
os.makedirs('./imgs', exist_ok=True)
metrics = run.get_metrics()
plt.figure(figsize = (13,5))
plt.plot(metrics['validation_acc'], 'r-', lw=4, alpha=.6)
plt.plot(metrics['training_acc'], 'b--', alpha=0.5)
plt.legend(['Full evaluation set', 'Training set mini-batch'])
plt.xlabel('epochs', fontsize=14)
plt.ylabel('accuracy', fontsize=14)
plt.title('Accuracy over Epochs', fontsize=16)
run.log_image(name='acc_over_epochs.png', plot=plt)
plt.show()输出:
该图像已通过run.log_image()上传到了studio中,可在上面查看:
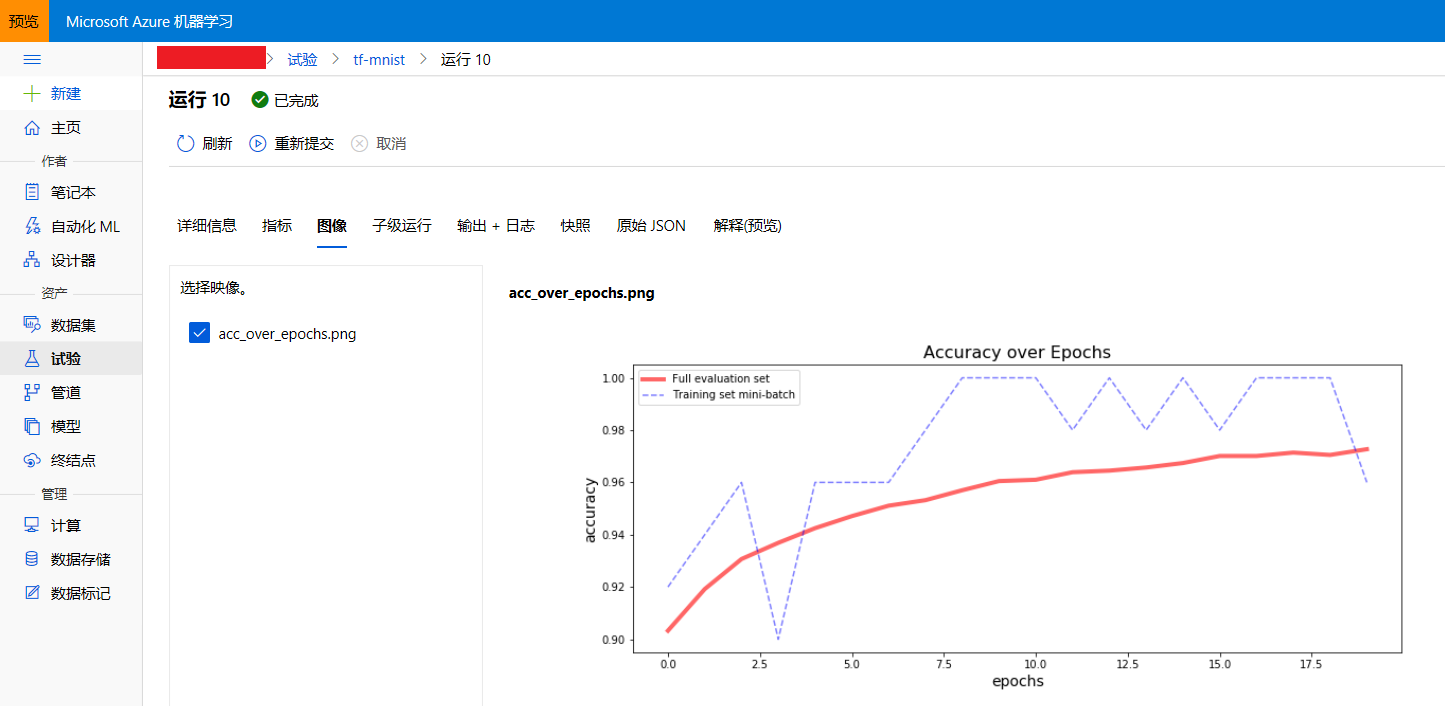
图11 在studio中查看上传的图像
十一、下载模型
在训练脚本中,我们将训练好的模型保存到了远程计算目标的./outputs本地文件夹中。Azure机器学习会自动将写到这个文件夹的文件run的“history file store”中,因此我们可以使用run这个对象的download_file()来下载脚本中保存的模型到本地文件夹。
# create a model folder in the current directory
os.makedirs('./model', exist_ok=True)
for f in run.get_file_names():
if f.startswith('outputs/model'):
output_file_path = os.path.join('./model', f.split('/')[-1])
print('Downloading from {} to {} ...'.format(f, output_file_path))
run.download_file(name=f, output_file_path=output_file_path)输出:
Downloading from outputs/model/checkpoint to ./modelcheckpoint ...
Downloading from outputs/model/mnist-tf.model.data-00000-of-00001 to ./modelmnist-tf.model.data-00000-of-00001 ...
Downloading from outputs/model/mnist-tf.model.index to ./modelmnist-tf.model.index ...
Downloading from outputs/model/mnist-tf.model.meta to ./modelmnist-tf.model.meta ...十二、在测试集上评估模型
加载上面下载的TensorFlow模型的graph,打印出所有“network”下的operation。从而找到输入向量“network/X:0”和输出向量“network/output/MatMul:0”,接下来会用到它们预测测试集。
如果本地的TensorFlow版本和云上计算集群的版本不一致,会出现"compiletime version mismatch"的警告,可以不用管它。
import tensorflow as tf
tf.reset_default_graph()
saver = tf.train.import_meta_graph("./model/mnist-tf.model.meta")
graph = tf.get_default_graph()
for op in graph.get_operations():
if op.name.startswith('network'):
print(op.name)输出:
network/X
network/y
network/h1/MatMul
network/h1/BiasAdd
network/h1/Relu
network/h2/MatMul
network/h2/BiasAdd
network/h2/Relu
network/output/MatMul
network/output/BiasAdd在测试集上运行模型:
# input tensor. this is an array of 784 elements, each representing the intensity of a pixel in the digit image.
X = tf.get_default_graph().get_tensor_by_name("network/X:0")
# output tensor. this is an array of 10 elements, each representing the probability of predicted value of the digit.
output = tf.get_default_graph().get_tensor_by_name("network/output/MatMul:0")
with tf.Session() as sess:
saver.restore(sess, './model/mnist-tf.model')
k = output.eval(feed_dict={X : X_test})
# get the prediction, which is the index of the element that has the largest probability value.
y_hat = np.argmax(k, axis=1)
# print the first 30 labels and predictions
print('labels: t', y_test[:30])
print('predictions:t', y_hat[:30])输出:
labels: [7 2 1 0 4 1 4 9 5 9 0 6 9 0 1 5 9 7 3 4 9 6 6 5 4 0 7 4 0 1]
predictions: [7 2 1 0 4 1 4 9 5 9 0 6 9 0 1 5 9 7 3 4 9 6 6 5 4 0 7 4 0 1]计算模型在测试集上的准确率:
print("Accuracy on the test set:", np.average(y_hat == y_test))输出:
Accuracy on the test set: 0.9717十三、总结
本节使用Azure机器学习创建了图像多分类模型,将图像数据集注册到Azure机器学习工作区并利用了云上的GPU资源来训练模型,演示了Azure机器学习训练模型的一般步骤以及查看模型结果、下载模型到本地和在测试集上进行预测等内容。
最后
以上就是羞涩摩托最近收集整理的关于Azure机器学习——动手实验02:使用云上GPU资源训练一个图像分类模型一、使用前提二、连接和初始化工作区三、创建试验四、创建计算资源五、数据集六、创建运行脚本七、设置试验运行环境八、提交试验九、监控试验运行状态十、查看运行结果(Run object)十一、下载模型十二、在测试集上评估模型十三、总结的全部内容,更多相关Azure机器学习——动手实验02:使用云上GPU资源训练一个图像分类模型一、使用前提二、连接和初始化工作区三、创建试验四、创建计算资源五、数据集六、创建运行脚本七、设置试验运行环境八、提交试验九、监控试验运行状态十、查看运行结果(Run内容请搜索靠谱客的其他文章。








发表评论 取消回复