文章目录
- 机器学习基础
- 机器学习开发流程
- 数据类型
- 机器学习算法分类
- sklearn数据集
- 转换器和预估器
- 机器学习核心算法
- 分类算法-k近邻算法
- 案例:k近邻算法实例-预测入住位置
- 分类算法-朴素贝叶斯算法
- 朴素贝叶斯案例
机器学习基础
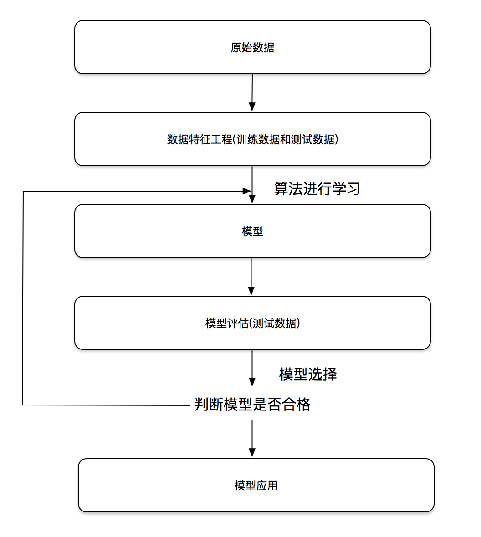
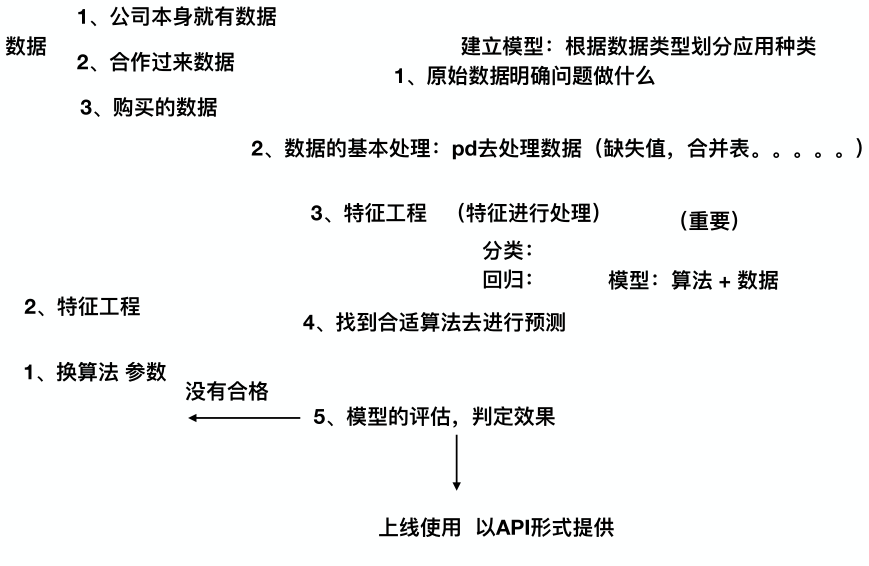
机器学习开发流程

数据类型


注:只要记住一点,离散型是区间内不可分,连续型是区间内可分

离散型:图像识别,判断是猫是狗?

离散型:文本主题分析,科技还是体育?
连续型:预测票房数据!
【注】对于不同类型的数据会有不同的算法进行处理。
机器学习算法分类

举个例子,监督学习就是给你一大堆男性,女性的特征,身高,体重等,给你的这些数据既有特征值也有目标值,也就是你已经知道了这些特征对应的性别是什么了,然后你再输入一组新的特征值让程序去帮你预测目标值,也就是预测是男是女。无监督学习是指事先不知道目标值是什么,也就是不能像监督学习那样分类,甚至我们不知道我们在分什么类。。这么说有点抽象,可以看看接下来的博客。




sklearn数据集

下面我们来介绍一些API及其例子,自己准备数据集,耗时耗力,不一定真实,所以我们用sklearn自带的数据集,以下内容都是为了说明训练集与测试集到底是怎么回事所用的sklearn自带的数据集来做实验。

获取数据集返回的类型:(新闻数据,手写数字,回归数据集没有特征名)

先说_load()的情况:*
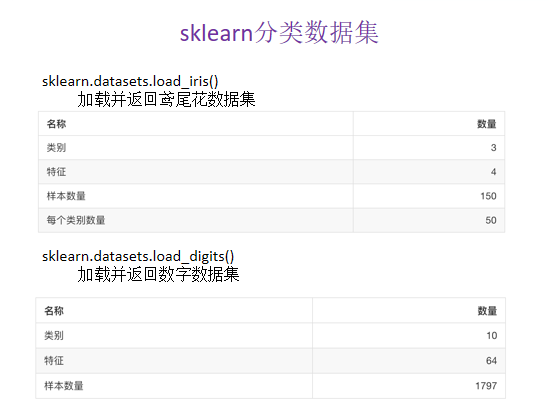
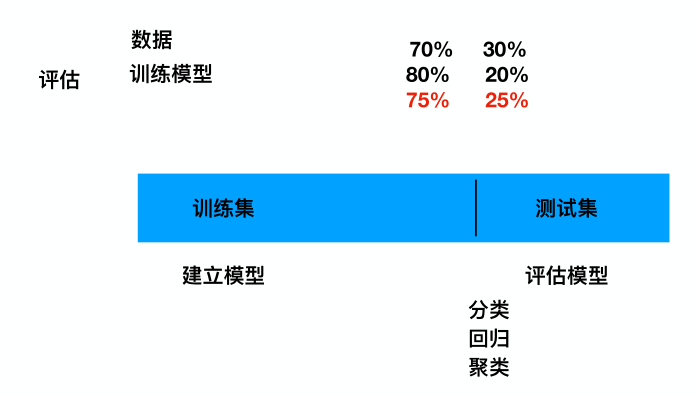
数据集的分割API

from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
li = load_iris()
print("获取特征值")
print(li.data)
print("目标值")
print(li.target)
##输出特征值描述
print(li.DESCR)
# 注意返回值, 训练集 train x_train, y_train 测试集 test x_test, y_test
#一定得按照这个顺序写变量
x_train, x_test, y_train, y_test = train_test_split(li.data, li.target, test_size=0.25)
#测试集占了25%
print("训练集特征值和目标值:", x_train, y_train)
print("测试集特征值和目标值:", x_test, y_test)
运行结果:
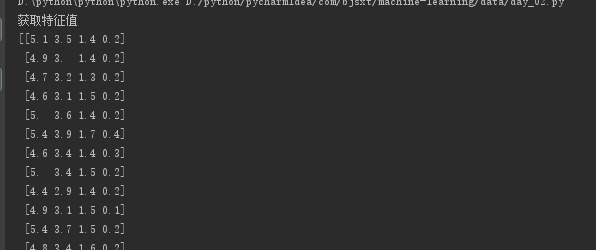
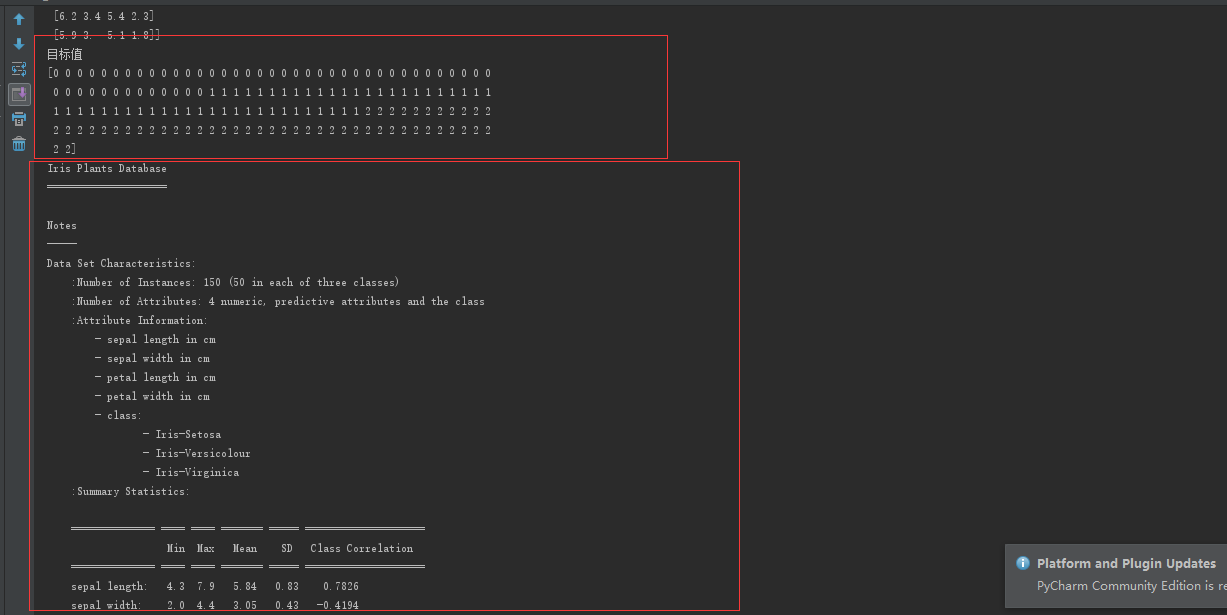
上面两图展示了数据集的特征值和目标值,以及相关描述。
下面四张图会展示该数据集划分训练集和测试集后的特征值和目标值,注意划分的时候是乱序!!自己观察对比!
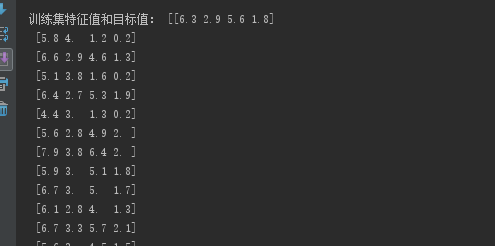

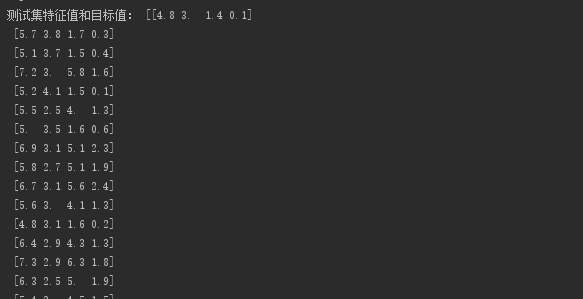

明显可看到训练集和测试集数量的不同,这里我就只写了鸢尾花的例子,load_digit道理一样,就不赘述了。
回归数据集同样也使用现成的数据集!
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
lb = load_boston()
print("获取特征值")
print(lb.data)
print("目标值")
print(lb.target)
print(lb.DESCR)
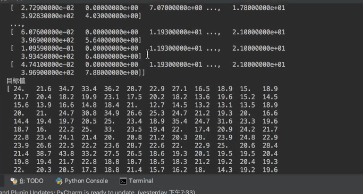
我们可以看到结果与鸢尾花不太一样了,鸢尾花有具体的某一类(离散),而波士顿房价这个是一组浮点数,不能简单的认为某一个浮点数就代表一类(连续)。
下面来说说_fetch的情况!!*
这是新闻数据集,表示有20种新闻。


from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
news = fetch_20newsgroups(subset='all')
#
print(news.data)
print(news.target)
转换器和预估器
转换器
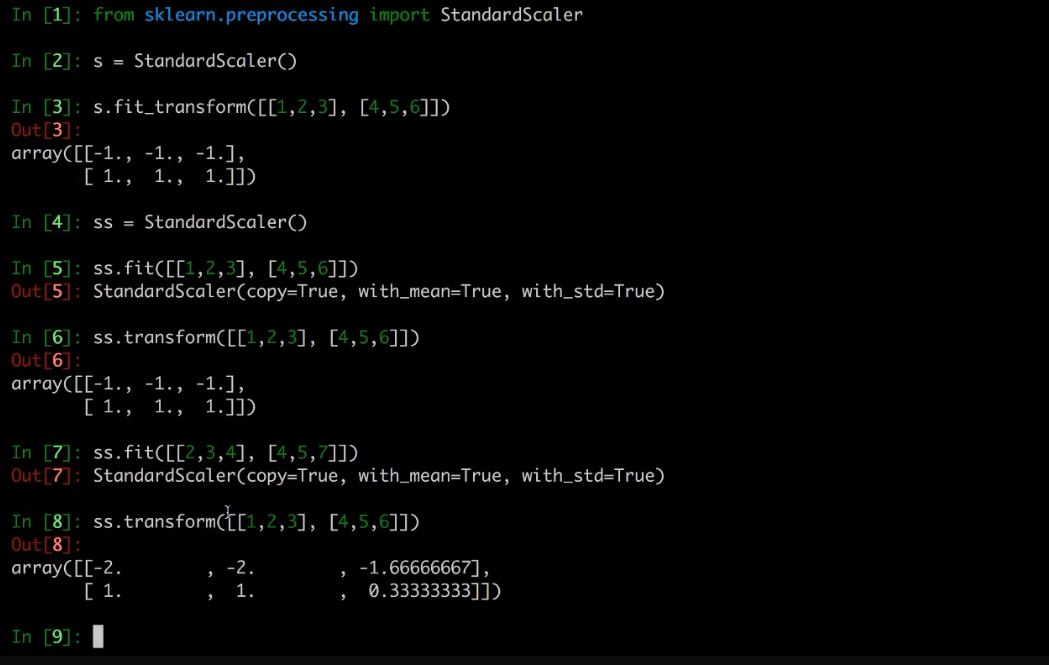
由上图我们可以看到fit_transform的作用等于fit+transform。
fit先对数据进行处理,算平均值,标准差等数据,然后tramsform对fit后的数据进行最终转换,转换成我们想要的。当然,如果fit与transform传入的数据不一致,那么结果就不太对了,我们通常就用fit_transform.
估计器

转换器是对数据的特征处理,而估计器才是真正的用于算法的API,不同算法有不同的估计器。
估计器工作流程
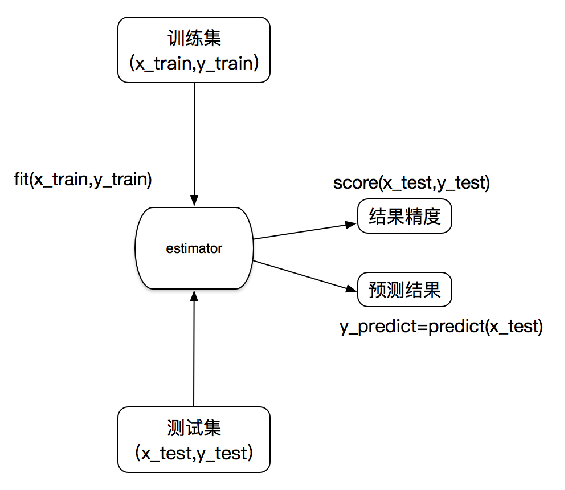
机器学习核心算法
分类算法-k近邻算法
我们来看一下下面的表,我们能够从前面的六部电影预测出未知电影是什么,k-近邻算法就是算要预测的目标和已知目标的距离是多少,我们选距离最小的前k个。
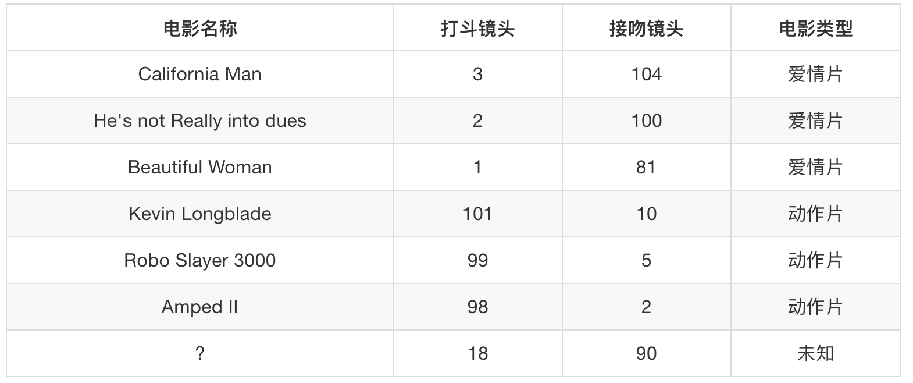

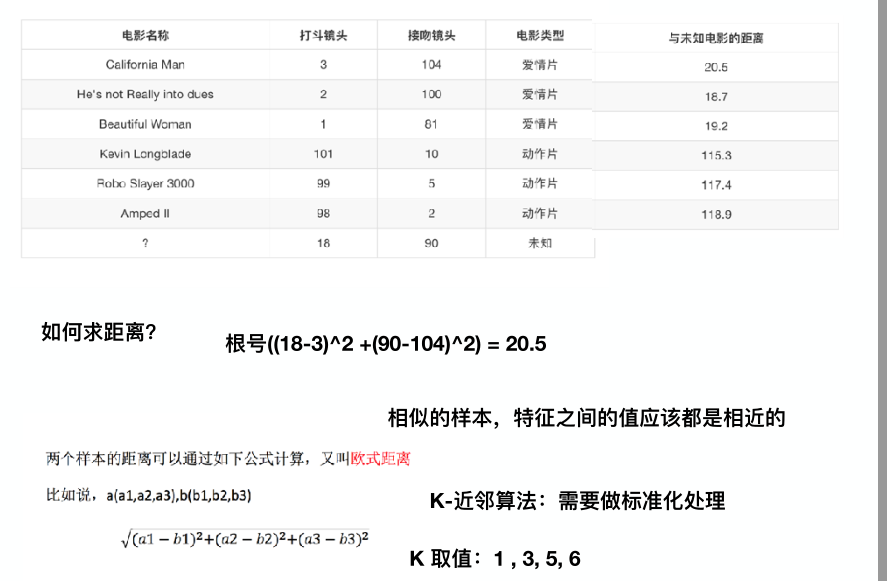
还记得第一节的标准化归一化吗,我举过一个距离的例子,很显然这的欧氏距离与那个例子的一样,会受异常数据的影响,于是我们要将其标准化!!!并且,选取合适的k也十分重要。



案例:k近邻算法实例-预测入住位置
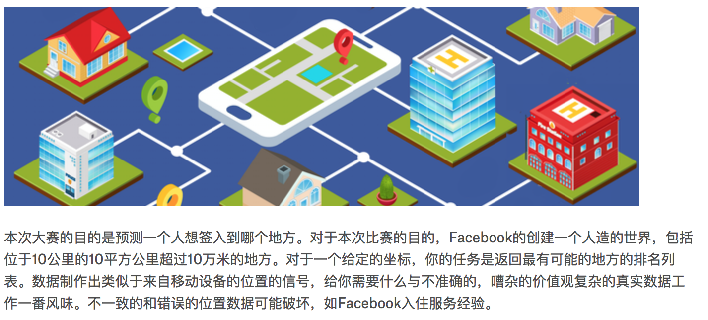
下图是各个特征的名称:

训练集与测试集的数据来源是kaggle上的。
我们先来看看数据长啥样?
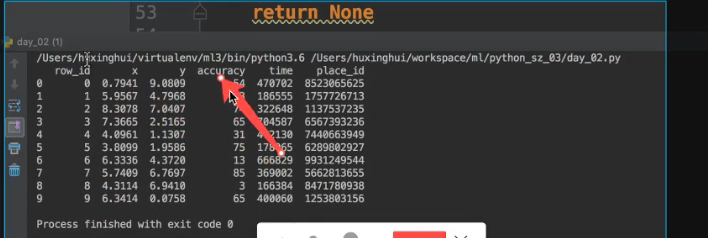
然后我们来分析要怎么做,如下图所示:

这数据有1.5个G,太庞大了,于是我做处理筛选了一部分,然后时间戳我转换成年月日时分秒的样子,并且从中提取出了新的特征值,最后预测的入住id太多了,我还要筛选一下。
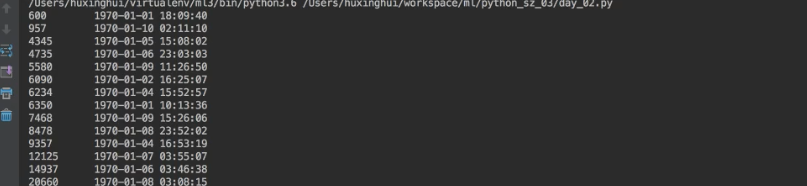
时间戳转化为时间如下:
具体的预测代码如下:
import pandas as pd
def knncls():
"""
K-近邻预测用户签到位置
:return:None
"""
# 读取数据
data = pd.read_csv("./data/FBlocation/train.csv")
# print(data.head(10))
# 处理数据
# 1、缩小数据,查询数据晒讯
data = data.query("x > 1.0 & x < 1.25 & y > 2.5 & y < 2.75")
# 处理时间的数据,pandas的api,unit是按秒的意思
time_value = pd.to_datetime(data['time'], unit='s')
#输出结果是上面那张图
print(time_value)
# 把日期格式转换成字典格式,然后可以用键去获取年月日等
time_value = pd.DatetimeIndex(time_value)
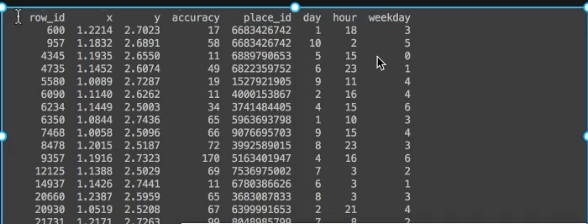
# 构造一些特征,相当于新加了三列特征
data['day'] = time_value.day
data['hour'] = time_value.hour
data['weekday'] = time_value.weekday
# 把时间戳特征删除,pandas的axis=1是列,sklearn的1是行
data = data.drop(['time'], axis=1)
#输出结果是下面第一张图
print(data)
# 把签到数量少于n个目标位置删除
#按照place_id分组,并计数
place_count = data.groupby('place_id').count()
tf = place_count[place_count.row_id > 3].reset_index()
data = data[data['place_id'].isin(tf.place_id)]
# 取出数据当中的特征值和目标值
y = data['place_id']
x = data.drop(['place_id'], axis=1)
# 进行数据的分割训练集合测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
# 特征工程(标准化)
std = StandardScaler()
# 对测试集和训练集的特征值进行标准化
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
# 进行算法流程 # 超参数
knn = KNeighborsClassifier()
# # fit, predict,score
knn.fit(x_train, y_train)
#
# # 得出预测结果
y_predict = knn.predict(x_test)
#
print("预测的目标签到位置为:", y_predict)
#
# # 得出准确率
print("预测的准确率:", knn.score(x_test, y_test))
return None
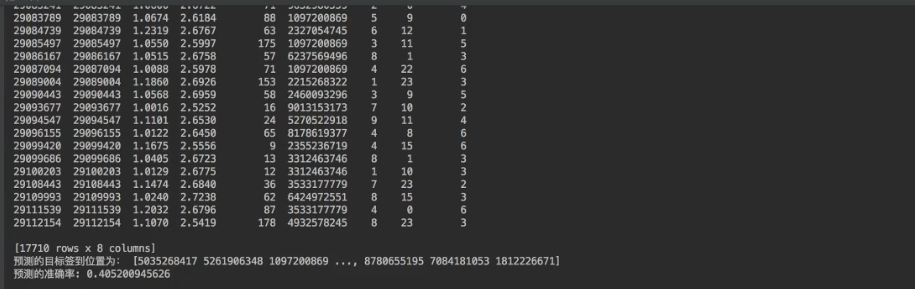
我们可以看到准确率只有4成,这是因为我们没有删row_id,这个特征没有实际含义!!!

分类算法-朴素贝叶斯算法
先来说说这个算法是干啥的,比如给我四篇文章,我统计其中的关键字,然后来判断属于该文章属于哪一种类别,取可能性最大的类别为预测值!!!
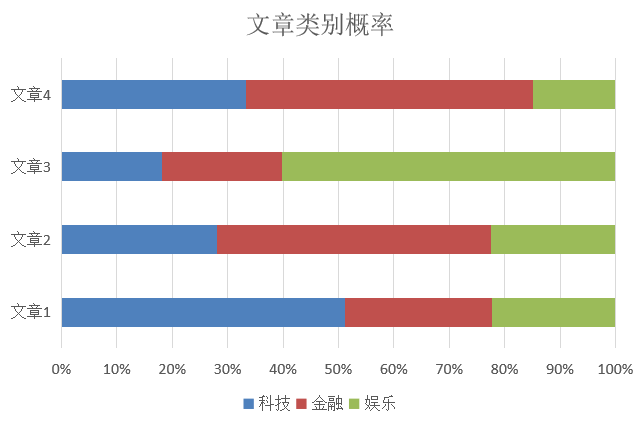
再举个例子:
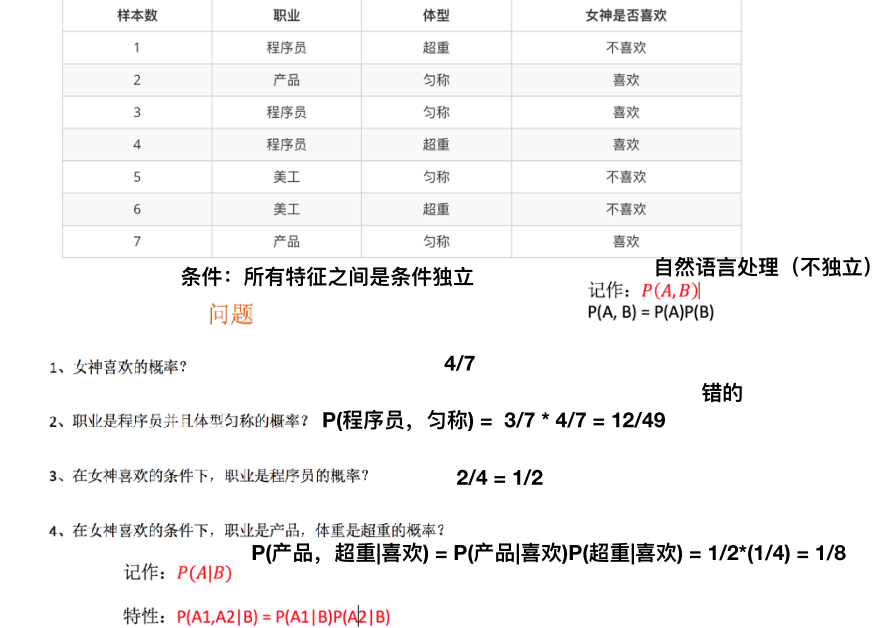

朴素贝叶斯这里的朴素就是指各特征值相互独立,也就是不能互相影响对方!!比如博士的工资比大专的工资高,这里是什么学历根工资的多少就有影响!!
朴素贝叶斯-贝叶斯公式
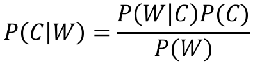

每部分说明:



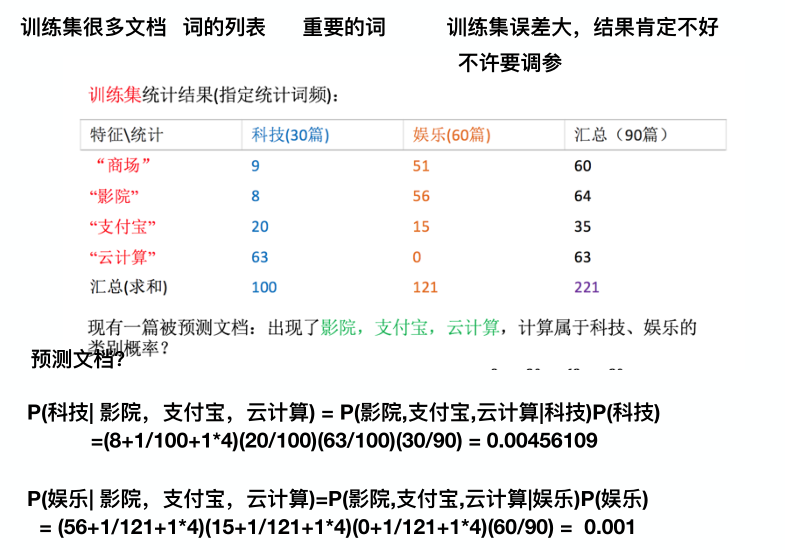
下面这个例子就用上述公式来演示:
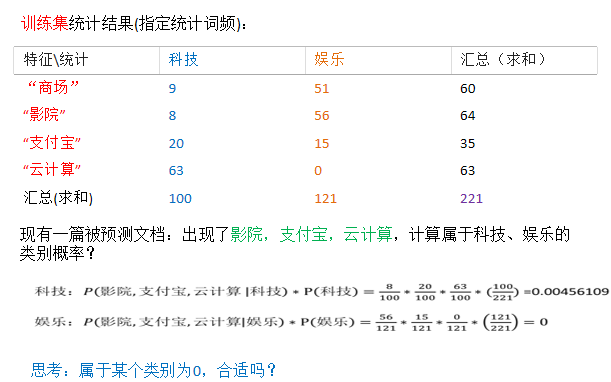
怎么算的一目了然,然后如果有一个部分为0,那么整个概率就为零了,这显然不合适!!于是我们要做处理使他不为0,如下:

下面是经过拉普拉斯处理的(注意不光是处理娱乐的那一组概率,还要处理科技那一组的概率,每一项都要处理):
sklearn朴素贝叶斯实现API


朴素贝叶斯案例
def naviebayes():
"""
朴素贝叶斯进行文本分类
:return: None
"""
news = fetch_20newsgroups(subset='all')
# 进行数据分割
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25)
# 对数据集进行特征抽取,因为文章里面有一些不重要的词,虽然那些词次数出现的很多
tf = TfidfVectorizer()
# 以训练集当中的词的列表进行每篇文章重要性统计如['a','b','c','d']
x_train = tf.fit_transform(x_train)
print(tf.get_feature_names())
x_test = tf.transform(x_test)
# 进行朴素贝叶斯算法的预测
mlt = MultinomialNB(alpha=1.0)
print(x_train.toarray())
mlt.fit(x_train, y_train)
y_predict = mlt.predict(x_test)
print("预测的文章类别为:", y_predict)
# 得出准确率
print("准确率为:", mlt.score(x_test, y_test))
print("每个类别的精确率和召回率:", classification_report(y_test, y_predict, target_names=news.target_names))
return None
结果如下:
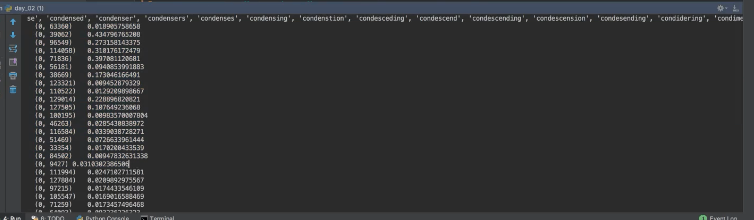
我们可以看到第一行是我打印的特征名,然后从第二行开始默认以sparse矩阵打印每个词的重要性!!然后我转成二维数组的形式来观察,如下:

每一行代表一篇文章,然后可以看出每个词在那一篇文章里的重要性程度。



最后
以上就是标致冬日最近收集整理的关于机器学习之Scikit-Learn数据集及分类算法(k近邻算法与朴素贝叶斯算法)的全部内容,更多相关机器学习之Scikit-Learn数据集及分类算法(k近邻算法与朴素贝叶斯算法)内容请搜索靠谱客的其他文章。








发表评论 取消回复