
目录
1. 网站分析意义
2. 如何进行网站分析
3. 整体技术流程及架构
3.1. 数据处理流程
3.2. 系统的架构
4. 模块开发----数据采集
5. 数据采集之 js 自定义采集
1. 原理分析
1. 网站分析意义

首先,网站分析是网站的眼睛。是从网站的营销角度看到的网站分析。在这 部分中,网站分析的主要对象是访问者,访问者在网站中的行为以及不同流量之 间的关系。
其次,网站分析是整个网站的神经系统。这是从产品和架构的角度看到的网 站分析。在这部分中,网站分析的主要对象是网站的逻辑和结构,网站的导航构是否合理,注册购买流程的逻辑是否顺畅。
最后,网站分析是网站的大脑,在这部门中,网站分析的主要分析对象是投 资回报率(ROI)。也就是说在现有的情况下,如何合理的分配预算和资源以完成 网站的目标。 终极意义:改善网站的运营,获取更高投资回报率(ROI)。赚更多的钱。
2. 如何进行网站分析
网站分析整体来说是一个内涵非常丰富的体系,整体过程是一个金字塔结构:
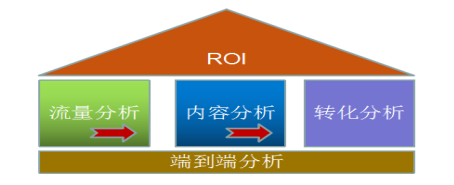
金字塔的顶部是网站的目标:投资回报率(ROI)。
2.1. 网站流量质量分析(流量分析)
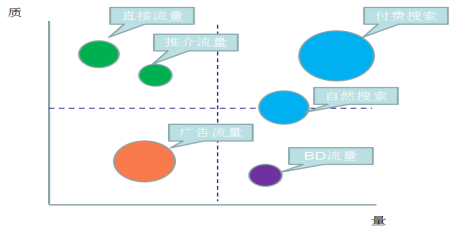
X 轴代表量,指网站获得的访问量。Y 轴代表质,指可以促进网站目标的事 件次数(比如商品浏览、注册、购买等行为)。圆圈大小表示获得流量的成本。
- 第一象限:质高量高。这是网站的核心流量,对于这部分流量保持即可。建 议降低获取流量的成本。
- 第二象限:质高量低。这部分是网站的忠诚用户,有很高的质,建议提高量。
- 第三象限: 量可以质较低,并且获取量的成本比较高。
- 第四象限: 量高质低。这部分需要提高质量。
BD 流量是指商务拓展流量。一般指的是互联网经过运营或者竞价排名等方式,从 外部拉来的流量。比如在百度上花钱来竞价排名,产生的流量就是 BD 流量的一部分(CSDN,博客园技术类)。
2.2. 网站流量多维度细分(流量分析)
细分是指通过不同维度对指标进行分割,查看同一个指标在不同维度下的表 现,进而找出有问题的那部分指标,对这部分指标进行优化。 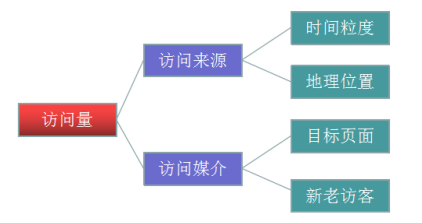
指标是访问量,就是我们常说的流量。在来源维度、媒介维度、时间维 度、位置维度等维度下,我们可以对访问量进行单独或者重叠的多维度细分。
2.3. 网站内容及导航分析(内容分析)
第一个问题:访问者从导航类页面(首页)进入,还没有看到内容类页面(详 情页)之前就从导航类页面(列表页)离开网站。在这次访问中,访问者并没有 完成任务,导航类页面也没有将访问者带入到内容类页面(详情页)中。因此, 需要分析导航类页面(列表页)造成访问者中途离开的原因。
第二个问题:访问者从导航类页面(首页或列表页)进入网站,从内容类页 面(详情页)又返回到导航类页面(首页)。看似访问者在这次访问中完成了任 务(如果浏览内容页就是这个网站的最终目标的话),但其实访问者返回首页是 在开始一次新的导航或任务。说明需要分析内容页的最初设计,并考虑中内容页 提供交叉的信息推荐。
2.4. 网站转化以及漏斗分析(转化分析)
下图描述了转化率分析中一个常见场景,对访问路径“首页-搜索-菜品-下单-支付”做分析,统计按照顺序访问每层节点的用户数,得到访问过程的转化率。
统计上有一些维度约束,比如日期,时间窗口(整个访问过程在规定时间内完成,否则统计无效),城市或操作系统等,因此这也是一个典型的OLAP分析需求。此外,每个访问节点可能还有埋点属性,比如搜索页上的关键词属性,支付页的价格属性等。从结果上看,用户数是逐层收敛的,在可视化上构成了一个漏斗的形状,因此这一类需求又称之为“有序漏斗”。

- 转化中的阻力的流失
- 访问者的迷失
3. 整体技术流程及架构
3.1. 数据处理流程
网站流量日志数据分析是一个纯粹的数据分析项目,其整体流程基本上就是 依据数据的处理流转流程进行。通俗可以概括为:数据从哪里来和数据到哪里去, 可以分为以下几个大的步骤:
1.1. 数据采集
数据采集概念,目前行业会有两种解释:
一是数据从无到有产生的过程(服务器打印的 log、自定义采集的日志等) 叫做数据采集;
另一方面也有把通过使用 Flume 等工具把数据采集搬运到指定位置的这个 过程叫做数据采集。 关于具体含义要结合语境具体分析,明白语境中具体含义即可。
1.2. 数据预处理
数据预处理(data preprocessing)是指在正式处理以前对数据进行的一些 处理。现实世界中数据大体上都是不完整,不一致的脏数据,无法直接进行数据 分析,或者说不利于分析。为了提高数据分析的质量和便捷性产生了数据预处理 技术。
数据预处理有多种方法:数据清理,数据集成,数据变换等。这些数据处技术在正式数据分析之前使用,大大提高了后续数据分析的质量与便捷,降低实 际分析所需要的时间。
技术上原则来说,任何可以接受数据经过处理输出数据的语言技术都可以用 来进行数据预处理。比如 java、Python、shell 等。 本项目中通过 MapReduce 程序对采集到的原始日志数据进行预处理,比如 数据清洗,日期格式整理,滤除不合法数据等,并且梳理成点击流模型数据。 使用 MapReduce 的好处在于:一是 java 语言熟悉度高,有很多开源的工具 库便于数据处理,二是 MR 可以进行分布式的计算,并发处理效率高。
预处理完的结构化数据通常会导入到 Hive 数据仓库中,建立相应的库和表 与之映射关联。这样后续就可以使用 Hive SQL 针对数据进行分析。 因此这里所说的入库是把数据加进面向分析的数据仓库,而不是数据库。因 项目中数据格式比较清晰简明,可以直接 load 进入数据仓库。 实际中,入库过程有个更加专业的叫法—ETL。ETL 是将业务系统的数据经 过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、 标准不统一的数据整合到一起,为企业的决策提供分析依据。
ETL 的设计分三部分:数据抽取、数据的清洗转换、数据的加载。在设计 ETL 的时候我们 也是从这三部分出发。数据的抽取是从各个不同的数据源抽取到 ODS(Operational Data Store,操作型数据存储)中——这个过程也可以做一些数据的清洗和转换),在抽取的过程中 需要挑选不同的抽取方法,尽可能的提高 ETL 的运行效率。ETL 三个部分中,花费时间最长是“T”(Transform,清洗、转换)的部分,一般情况下这部分工作量是整个 ETL 的 2/3。数据 的加载一般在数据清洗完了之后直接写入 DW(Data Warehousing,数据仓库)中去。
1.4. 数据分析
将分析所得数据结果进行数据可视化,一般通过图表进行展示。 数据可视化可以帮你更容易的解释趋势和统计数据。
3.2. 系统的架构
相对于传统的 BI 数据处理,流程几乎差不多,但是因为是处理大数据,所 以流程中各环节所使用的技术则跟传统 BI 完全不同:
- 数据采集:页面埋点 JavaScript
- 采集:开源框架 Apache Flume
- 数据预处理: Hadoop MapReduce 程序
- 数据仓库技术:基于 hadoop 的数据仓库 Hive
- 数据导出:基于 hadoop 的 sqoop 数据导入导出工具
- 数据可视化:定制开发 web 程序(echarts)
- 整个过程的流程调度:hadoop 生态圈中的 azkaban 工具
4. 模块开发----数据采集
1. 网站流量日志数据获取 随着网站在技术和运营上的不断技术发展,人们对数据的要求越来越高,以 求实现更加精细的运营来提升网站的质量。所以数据的获取方式也随着网站技术 的进步和人们对网站数据需求的加深而不断地发展。从使用发展来看,主要分为 2 类:网站日志文件(Log files)和页面埋点 js 自定义采集。
1.1. 网站日志文件 记录网站日志文件的方式是最原始的数据获取方式,主要在服务端完成,在 网站的应用服务器配置相应的写日志的功能就能够实现,很多 web 应用服务器带日志的记录功能。如 Nginx 的 access.log 日志等。
优点是获取数据时不需要对页面做相关处理,可以直接开始统计相关请求信 息,缺点在于有些信息无法采集,比如用户在页面端的操作(如点击、ajax 的使 用等)无法记录。限制了一些指标的统计和计算。
所谓的代码埋点就是在你需要统计数据的地方植入N行代码,统计用户的关键行为。比如你想统计首页某个banner的点击量,上报的数据可以采用KEY-VALUE形式,我们定义 KEY为「CLICK_ADD_BTN」,VALUE的值为点击的次数。当用户点击banner时,banner详情的代码会通过按钮的「回调」来触发执行,程序猿在业务代码执行完后,又加上了统计代码,把「CLICK_ADD_BTN」对应的VALUE加1,banner被统计到了一次使用。
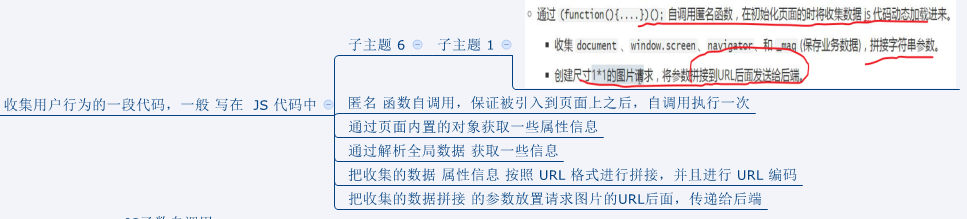
5. 数据采集之 js 自定义采集
1. 原理分析
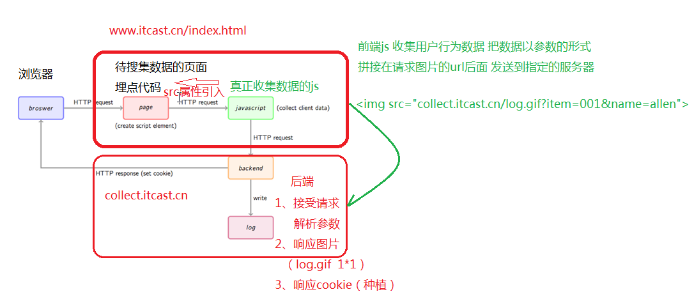
最后
以上就是外向老虎最近收集整理的关于网站日志采集和分析流程1. 网站分析意义 2. 如何进行网站分析3. 整体技术流程及架构4. 模块开发----数据采集5. 数据采集之 js 自定义采集的全部内容,更多相关网站日志采集和分析流程1.内容请搜索靠谱客的其他文章。








发表评论 取消回复