目的: 实现对网站流量数据分析 (MapReduce+Hive综合实验)
文件说明:
http.log 日志文件,是电信运营商记录用户手机上网访问某些网站行为的日志记录数据,其中上行流量+下行流量 = 总流量;
phone.txt 是手机号段规则,是手机号码对应地区城市和运营商的数据。
数据部分内容:
 http.log 部分数据
http.log 部分数据
.
 phone.txt 部分数据
phone.txt 部分数据
数据格式说明:
- http.log日志 数据格式:
手机号码,请求网站的URL,上行流量(20字节),下行流量(5000字节)
例如:18611132889 http://v.baidu.com/tv 20 5000 - phone.txt 数据格式:
手机号前缀,手机号段,手机号码对应的省份,城市,运营商,邮编,区号,行政划分代码
例如:133 1332170 广西 南宁 电信 530000 0771 450100
(一条数据中多个字段用空格或制表符分隔)
要求:
- 用 MapReduce 将数据段的间隔改成“,”
- 根据给的用户上网日志记录数据,计算出总流量最高的网站Top3(网站例如:v.baidu.com,weibo.com);
- 根据给的用户上网日志记录数据,计算出总流量最高的手机号Top3;
- 根据给的手机号段归属地规则,计算出总流量最高的省份Top3;
- 根据给的手机号段运营商规则,计算出总流量最高的运营商Top2;
- 根据给的手机号段归属地规则,计算出总流量最高的城市Top3;
首先对数据用 MapReduce 进行简单的处理,流程如下:
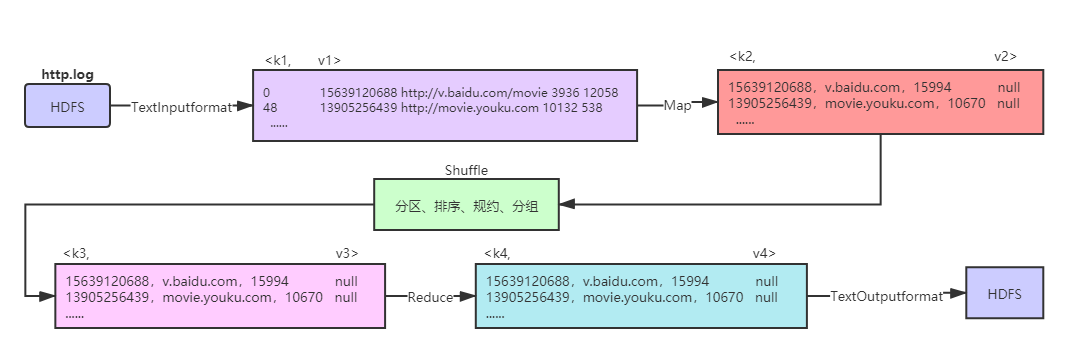 http.log 数据处理流程
http.log 数据处理流程
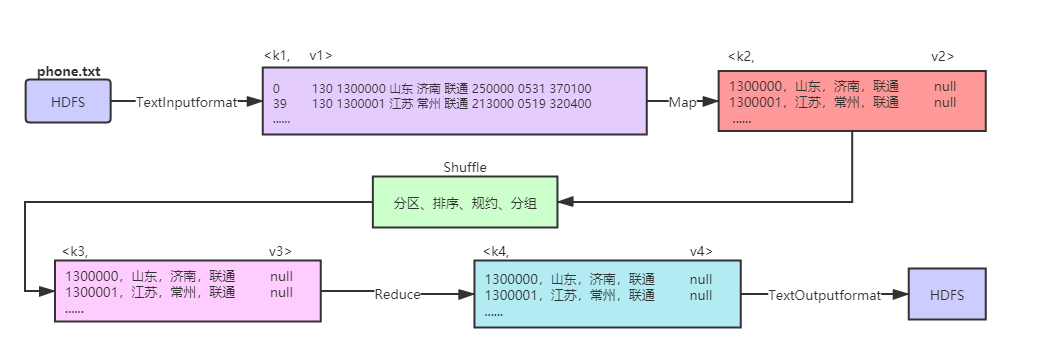 phone.txt 数据处理流程
phone.txt 数据处理流程
处理完数据,得到我们想要的数据,如下:
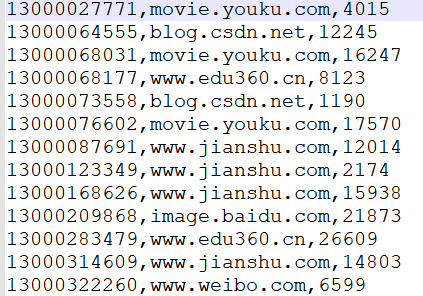 http.log 处理后的数据
http.log 处理后的数据
.
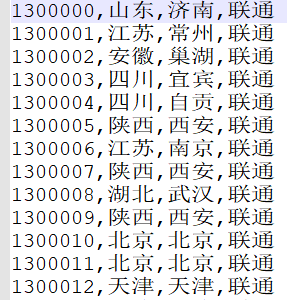 phone.txt 处理后的数据
phone.txt 处理后的数据
以下是 MapReduce 主要代码。
http_Mapper 代码:
public class http_Mapper extends Mapper<LongWritable, Text, Text, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//用正则表达式将文件每一行的制表符和空格换成逗号
String new_value = value.toString().replaceAll("s+", ",");
//将修改后的每一行数据切割成数组
String[] new_value_split = new_value.split(",");
//将每一行数据的网站保留有效域名
String domain_name = new_value_split[1].replaceAll("[a-zA-Z]+://|(/.*)", "");
//将每一行数据的上下行流量求和
int all_flow = Integer.parseInt(new_value_split[2]) + Integer.parseInt(new_value_split[3]);
//将手机号、域名网址、总流量作为处理后的有效数据,例如:15639120688 v.baidu.com 15994
String k2 = new_value_split[0] + "," + domain_name + "," + all_flow;
//写入上下文对象
context.write(new Text(k2), NullWritable.get());
}
}
http_Reducer 代码:
public class http_Reducer extends Reducer<Text, NullWritable, Text, NullWritable> {
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
//将shuffle过来的(k3,v3)直接当(k4,v4)就好了
context.write(key, NullWritable.get());
}
}
phone_Mapper 代码:
public class phone_Mapper extends Mapper<LongWritable, Text, Text, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//将文件每一行的制表符换成逗号
String new_value = value.toString().replace("t", ",");
//将修改后的每一行数据切割成数组
String[] new_value_split = new_value.split(",");
//将手机号段、省份、城市、运营商作为最后的有效数据,例如:1300000 山东 济南 联通
String mes = new_value_split[1] + "," + new_value_split[2] + "," + new_value_split[3] + "," + new_value_split[4];
//写入上下文对象
context.write(new Text(mes), NullWritable.get());
}
}
phone_Reducer 代码:
public class phone_Reducer extends Reducer<Text, NullWritable, Text, NullWritable> {
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
//将shuffle过来的(k3,v3)直接当(k4,v4)就好了
context.write(key, NullWritable.get());
}
}
接下来,创建 Hive 表,
输入命令:
create table if not exists lhr_http
(h_no bigint ,h_url string ,h_allstream int)
row format delimited fields terminated by ',';
create table if not exists lhr_phone
(p_no bigint ,p_prov string ,p_city string ,p_oper string)
row format delimited fields terminated by ',';
运行结果:

将清洗后的数据导入Hive
输入命令:
load data inpath '/http_out/part-r-00000' into table lhr_http;
load data inpath '/phone_out/part-r-00000' into table lhr_phone;
运行结果:

导入的的数据:
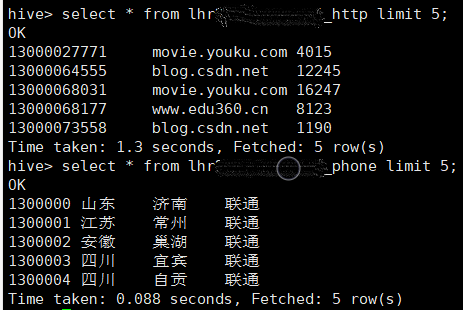
现在我们已经将处理好的数据导入到创建的两张 Hive 表了,接下来就可以写 Hql 语句来完成前面提到的 5 个要求了。
1.根据给的用户上网日志记录数据,计算出总流量最高的网站Top3(网站例如:v.baidu.com, weibo.com)
输入命令:
select h_url,sum(h_allstream) as sum
from lhr_http
group by h_url
order by sum desc
limit 3;
输出结果:
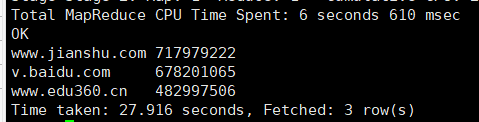
2. 根据给的用户上网日志记录数据,计算出总流量最高的手机号Top3
输入命令:
select h_no,sum(h_allstream) as sum
from lhr_http
group by h_no
order by sum desc
limit 3;
输出结果:
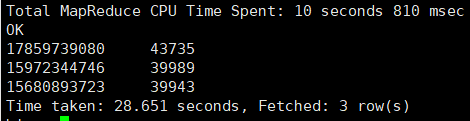
3. 根据给的手机号段归属地规则,计算出总流量最高的省份Top3
输入命令:
select p_prov,sum(h_allstream) as sum
from lhr_http, lhr_phone
where substr(h_no,0,7)=p_no
group by p_prov
order by sum desc limit 3;
输出结果:
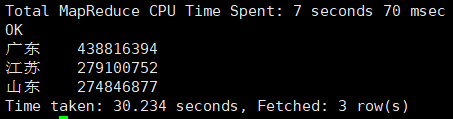
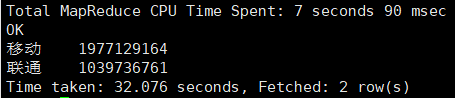
4. 根据给的手机号段运营商规则,计算出总流量最高的运营商Top2
输入命令:
select p_oper,sum(h_allstream) as sum
from lhr_http,lhr_phone
where substr(h_no,0,7)=p_no
group by p_oper
order by sum desc
limit 2;
输出结果:
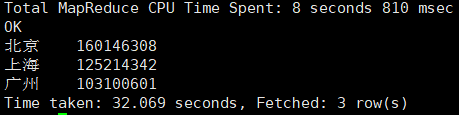
5. 根据给的手机号段归属地规则,计算出总流量最高的城市Top3
输入命令:
select p_city,sum(h_allstream) as sum
from lhr_http,lhr_phone
where substr(h_no,0,7)=p_no
group by p_city
order by sum desc
limit 3;
输出结果:
over!!!
最后
以上就是耍酷小蝴蝶最近收集整理的关于Hive+MapReduce实现对网站流量数据分析的全部内容,更多相关Hive+MapReduce实现对网站流量数据分析内容请搜索靠谱客的其他文章。








发表评论 取消回复