一、天气案例:细粒度介绍计算框架
(1)需求:找出每个月气温最高的2天
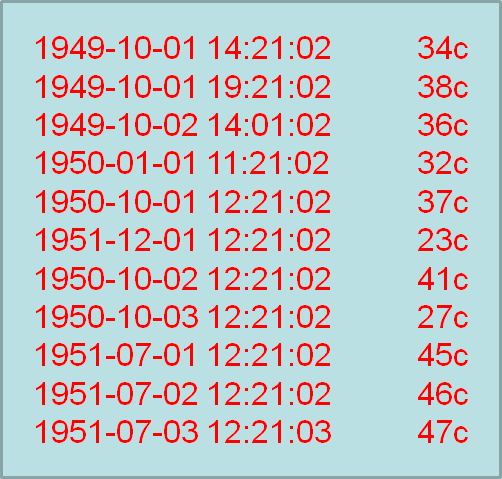
(2)思路
- 每年
- 每个月
- 最高
- 2天
- 1天多条记录?
进一部思考:
- 年月分组
- 温度升序
- key中要包含时间和温度呀!
MR原语:相同的key分到一组,通过GroupCompartor设置分组规则
(3)实现具体思路
自定义数据类型Weather:
- 包含时间
- 包含温度
- 自定义排序比较规则
自定义分组比较:
- 年月相同被视为相同的key
那么reduce迭代时,相同年月的记录有可能是同一天的:
- reduce中需要判断是否同一天
- 注意OOM
数据量很大:
- 全量数据可以切分成最少按一个月份的数据量进行判断
- 这种业务场景可以设置多个reduce
- 通过实现partition
二、FOF案例:推荐好友的好友,MR与数据模型
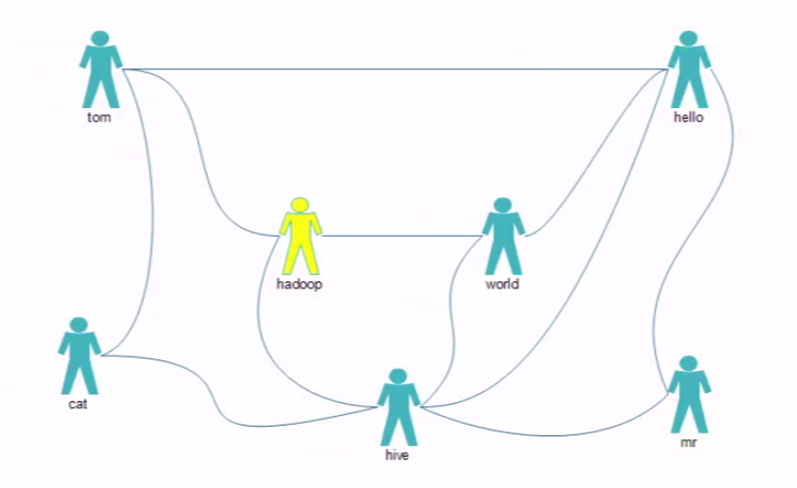
(1)疑问:
是简单的好友列表的差集吗?
最应该推荐的好友TopN,如何排名?

(2)思路:
- 推荐者与被推荐者一定有一个或多个相同的好友
- 全局去寻找好友列表中两两关系
- 去除直接好友
- 统计两两关系出现次数
(3)API接口设计:
- map:按好友列表输出两俩关系
- reduce:sum两两关系
- 再设计一个MR
- 生成详细报表
- reduce:
三、PageRank案例
(1)什么是pagerank
PageRank是Google提出的算法,用于衡量特定网页相对于搜索引擎索引中的其他网页而言的重要程度。
PageRank实现了将链接价值概念作为排名因素。
(2)算法原理
思考超链接在互联网中的作用?
入链 ====给?的投票
PageRank让链接来“投票“,到一个页面的超链接相当于对该页投一票。
入链数量:如果一个页面节点接收到的其他网页指向的入链数量越多,那么这个页面越重要。
入链质量:指向页面A的入链质量不同,质量高的页面会通过链接向其他页面传递更多的权重。所以越是质量高的页面指向页面A,则页面A越重要。
(3)网络上各个页面的链接图:
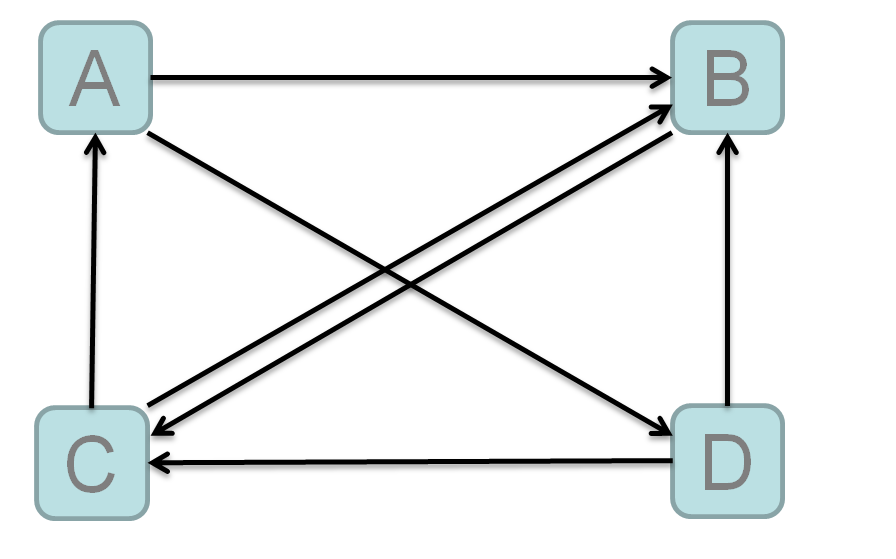
站在A的角度:需要将自己的PR值分给B,D
站在B的角度:收到来自A,C,D的PR值
(3)PageRank计算
PR(PageRank)需要迭代计算,其PR值会趋于稳定
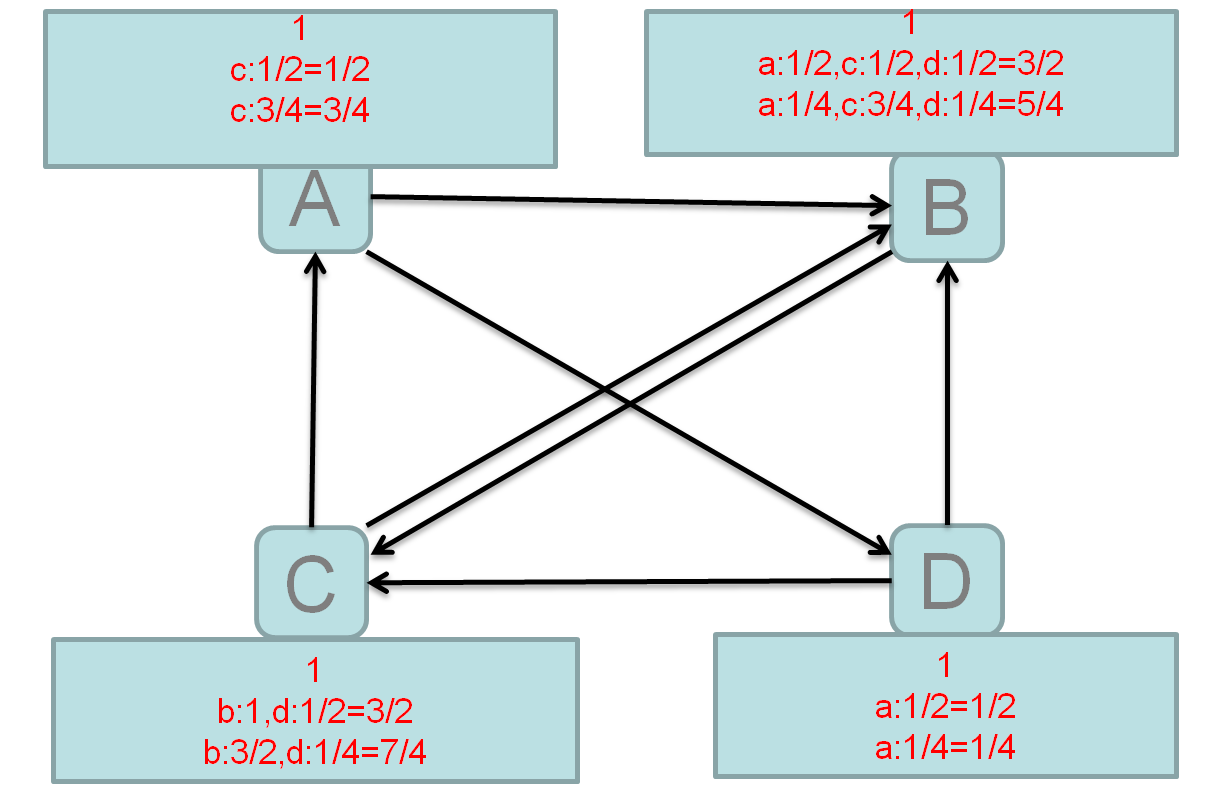
(4)PR算法原理
初始值:Google的每个页面设置相同的页面价值,即PR值,pagerank算法给每个页面的PR初始值为1。
迭代计算(收敛):Google不断的重复计算每个页面的PageRank。那么经过不断的重复计算,这些页面的PR值会趋向于稳定,也就是收敛的状态。
在具体企业应用中怎么样确定收敛标准?
- 每个页面的PR值和上一次计算的PR相等
- 设定一个差值指标(0.0001)。当所有页面和上一次计算的PR差值平均小于该标准时,则收敛。
- 设定一个百分比(99%),当99%的页面和上一次计算的PR相等
(5)具体算法
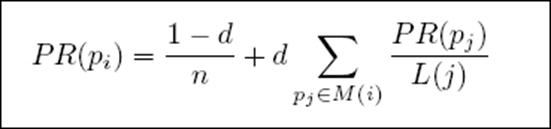
- d:阻尼系数(一般取值d=0.85)
- M(i):指向i的页面集合
- L(j):页面的出链数
- PR(pj):j页面的PR值
- n:所有页面数
站在互联网的角度:
- 只出,不入:PR会为0
- 只入,不出:PR会很高
- 直接访问网页
(6)思路
**MR原语不被破坏
PR计算是一个迭代的过程,首先考虑一次计算
思考:
- 页面包含超链接
- 每次迭代将PR值除以链接数后得到的值传递给所链接的页面
- so:每次迭代都要包含页面链接关系和该页面的PR值
- mr:相同的key为一组的特征
map:
- 读懂数据:第一次附加初始pr值
- 映射k:v
- 传递页面链接关系,key为该页面,value为页面链接关系
- 计算链接的pr值,key为所链接的页面,value为pr值
reduce:
- 按页面分组
- 两类value分别处理
- 最终合并为一条数据输出:key为页面&新的pr值,value为链接关系
四、TF-IDF案例
(1)什么是TFIDF:是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度,(也是一种用于资讯检索与资讯探勘的常用加权技术)
- 字词的重要性随着它在文件中出现的次数成正比增加
- 但同时会随着它在语料库中出现的频率成反比下降
(2)TFIDF作用
TF-IDF加权的各种形式——常被搜寻引擎应用
- 作为文件与用户查询之间相关程度的度量或评级。
- 除了TF-IDF以外,因特网上的搜寻引擎还会使用基于链接分析的评级方法,以确定文件在搜寻结果中出现的顺序:PR。
通俗点讲:
- 打开百度
- 搜索:王者
- 搜索:王者荣耀
- 继续搜索:王者荣耀 露娜
- 继续搜索:王者荣耀 露娜 连招
用户通过调整字词来缩小范围,每个字词都有对应出现的页面,通过字词数量缩小范围,最终通过字词对于页面的权重来进行排序
最后
以上就是斯文汉堡最近收集整理的关于Hadoop学习(3)——Mapreduce案例分析的全部内容,更多相关Hadoop学习(3)——Mapreduce案例分析内容请搜索靠谱客的其他文章。








发表评论 取消回复