之前我们说过了MapReduce的运算流程,整体架构方法,JobTracker与TaskTracker之间的通信协调关系等等,但是虽然我们知道了,自己只需要完成Map和Reduce 就可以完成整个MapReduce运算了,但是很多人还是习惯用sql进行数据分析,写MapReduce并不顺手,所以就有了Hive的存在。
首先我们来看看MapReduce是如何实现sql数据分析的。
MapReduce实现sql的原理
首先先看一句sql语句
select pageid , age,count(1) from pv_users group by pageid,age;
我们可以来看看MapReduce实现sql的原理。
具体数据输入和执行结果可以看下图:

左边是要分析的数据表,右边是分析结果。实际上把左边表相同的行进行累计求和,就得到右边的表了,看起来和wordCount的计算的计算很相似,也确实是这样。
然后我们来看看具体的处理过程:
- 首先是Map的计算,先整理成map的形式,也就是<1,25>,<2,25>诸如此类的,然后与count值进行结合成一个新的map,也就是<<2,25>,1>这样。
- map的输出经过shuffle之后,相同的key value组合到一起,也就是<<2,25>,<1,1>>,<1,1>代表的是Value记录
- 到了reduce阶段,进行聚合,也就是<<2,25>,2>
如下图

在Hive中,sql是常用的分析工具,既然一条sql能够通过MapReduce实现,那么Hive自然也可以。
然后我们来看一下Hive的架构。
Hive的架构
Hive的操作就是直接输入sql,调用MapReduce计算框架来完成数据分析操作。可以看看架构图。
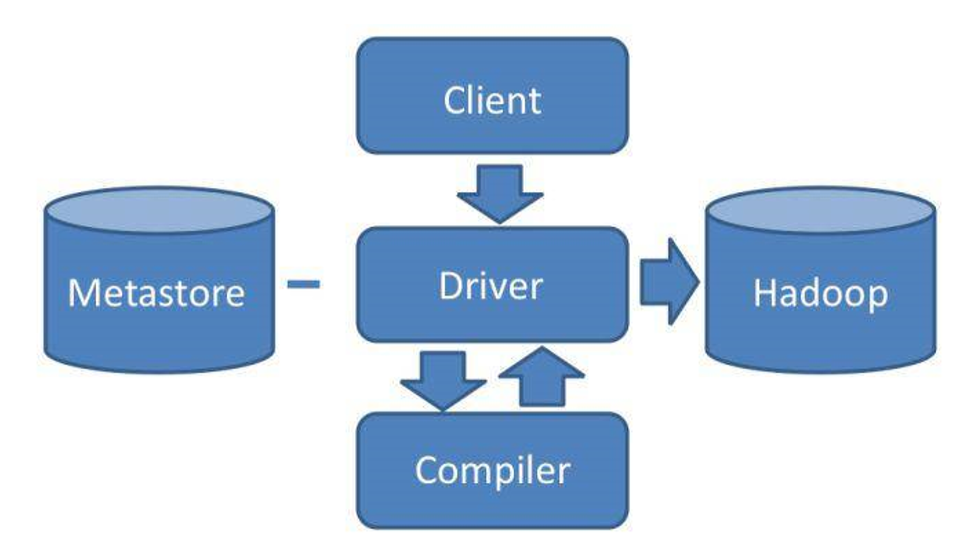
通过Hive 的Client向Hive提交sql语句。
如果是创建数据表的DDL语句,Hive就会通过执行引擎Driver将数据表的信息记录记录在MetaStore元数据组件中,这个组件通常用一个关系数据库实现,记录表明,字段名,字段类型,关联HDFS文件路径等等这些数据库的元数据信息。
如果是查询分析数据的DQL语句,Driver就会将该语句提交给自己的编译器Compiler进行语法分析、语法解析、语法优化等等一系列的操作,最后生成一个MapReduce执行计划。然后根据执行计划生成一个MapReduce的作业,提交给Hadoop MapReduce计算框架处理。
对于一个叫简单的sql命令,比如:
select * from status_updates where status Like 'michael jackson';
对应的Hive执行计划如下:
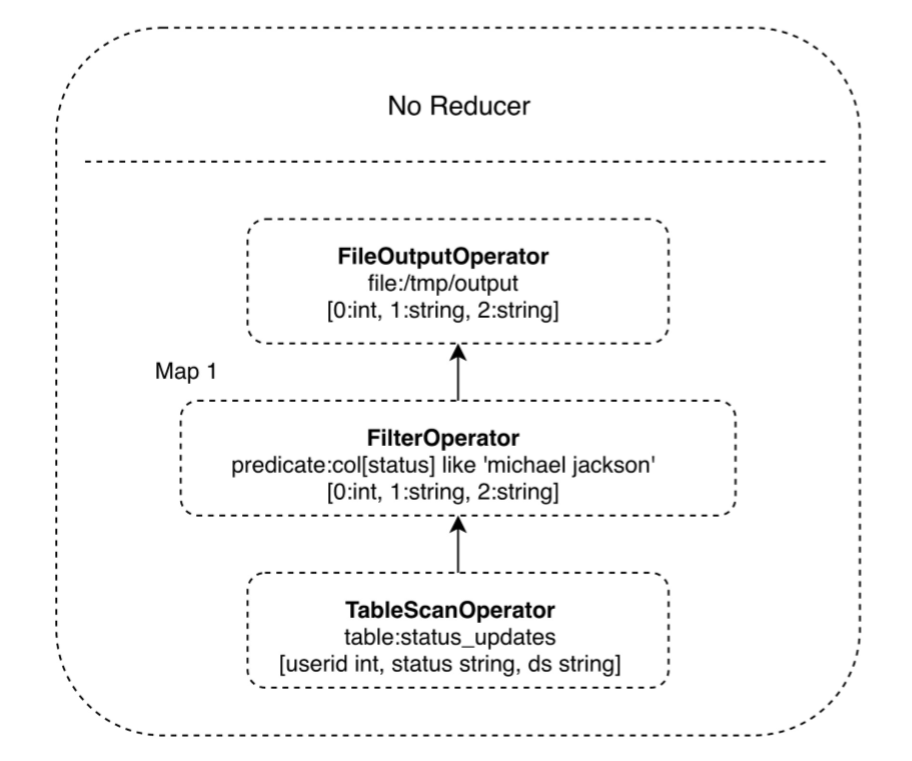
因为Hive本身内置了很多函数,所以执行计划就是根据sql生成这些函数的DAG(有向无环图),然后封装进MapReduce的map和reduce函数中。这个例子中,map函数调用了三个Hive内置函数:TableScanOperator 、FilterOperator、 FileOutputOperator,就完成了map计算,而且不需要reduce函数。
Hive如何实现join操作
除了上面简单的聚合过滤操作,Hive也可以实现join。
select pageid , age,count(1) from pv_users group by pageid,age;
这是文章开头的sql,但是假如。pv_user表是和另一张表关联的,我们select的数据也来自不同的表,那么就需要join操作了,先看我所说的两张表:
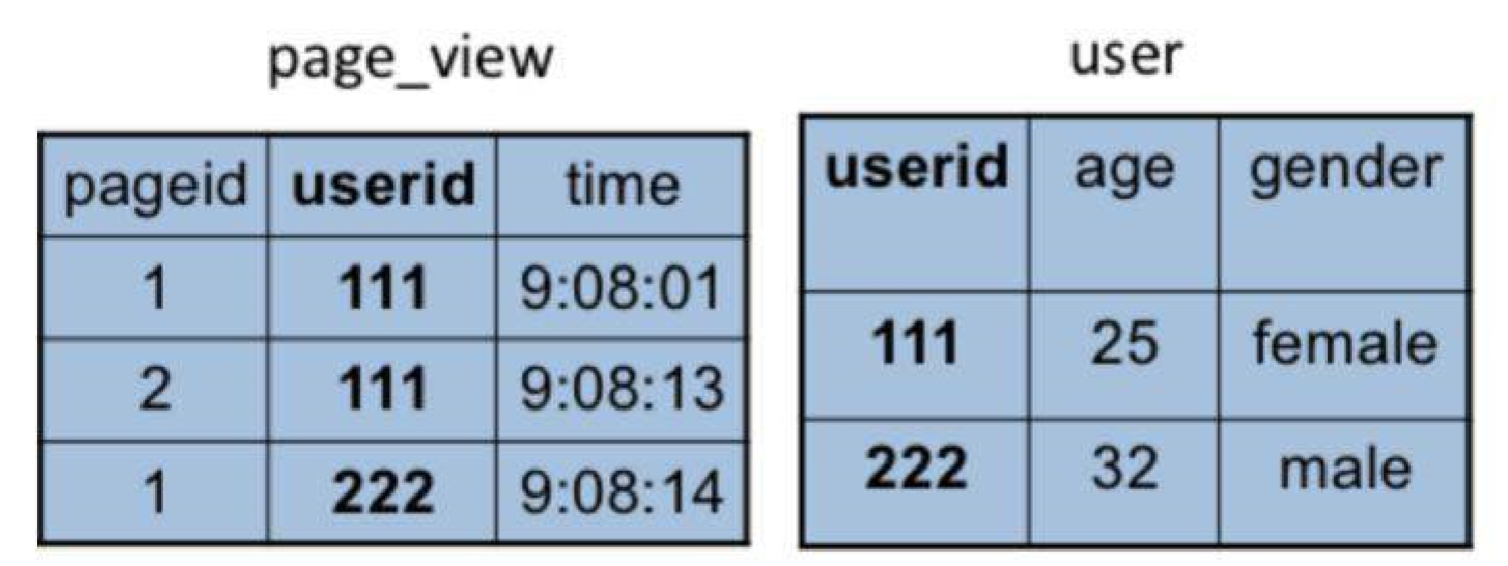
假设就是靠userid关联的,然后我们来重新表达一下新的sql语句。
select pv.pageid,u.age
from page_view pv
join user u on (pv.userid = u.userid);
同样,这个sql也可以转化成MapReduce计算,连接过程如下:
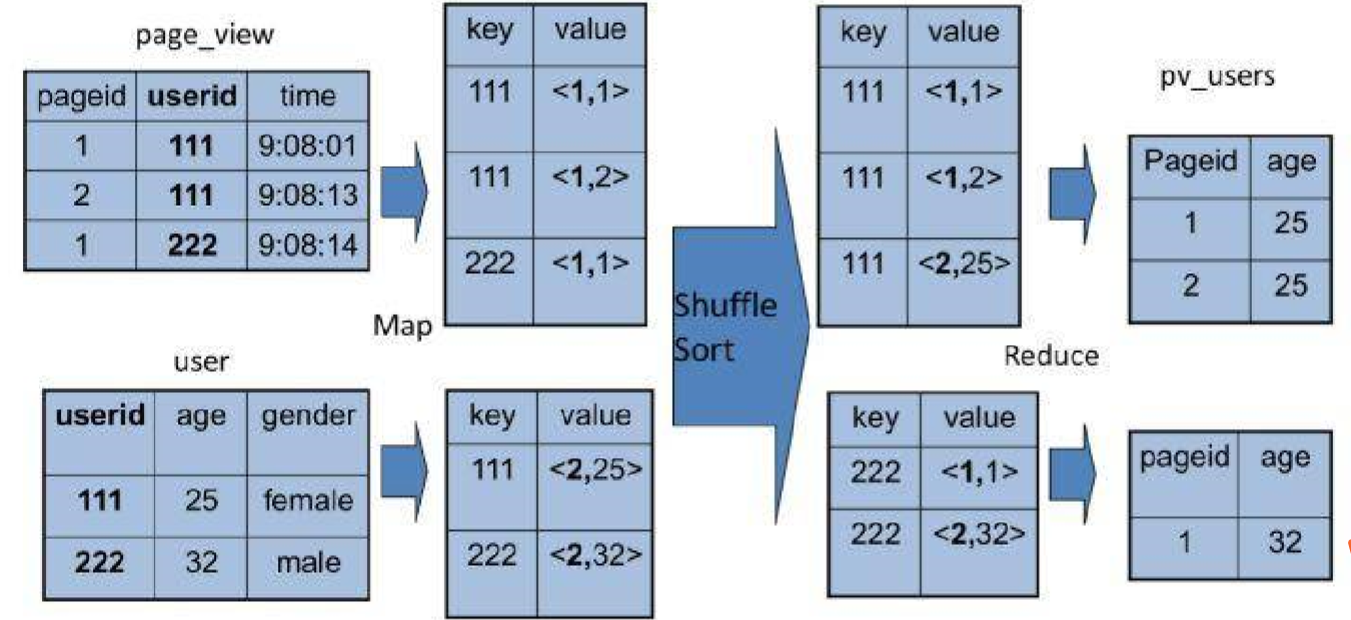
从上图来看,join的MapReduce计算的过程和前面的group by稍微有不同,因为join涉及到两张表,来自两个文件,所以需要在map输出的时候进行标记,比如来自第一张表,输出的Value标记为<1,x>,1就代表第一张表。
然后进行shuffle,相同的key输入到一个reduce进行聚合,根据表的标记进行笛卡尔积,然后每一张表进行连接,输出的就是join的结果。
HIVE的源代码里,join的时间复杂度为O(n²),对来自两张表的记录进行连接操作。
扩展
随着大数据sql的应用市场多样化之后,更多的大数据sql引擎也火了。
Cloudera开发了Impala,这是一种在HDFS上的MPP架构的sql引擎。与MapReduce启动Map和Reduce两种执行过程,将计算分为两个阶段的计算,并且Impala是在所有DataNode服务器上部署相同的Impalad进程,多个进程相互合作,完成高效的计算。
后来有了sparksql,它的引擎都是基于Shark的,由于速度很快,甚至快于Hive,所以Hive也后来兼容了Spark,可以在spark上计算Hive的执行计划。不得不说,这么多的集群,能做到技术嫁接,还是很有创新性的。
最后
以上就是大力滑板最近收集整理的关于Hive是如何让MapReduce实现SQL操作的的全部内容,更多相关Hive是如何让MapReduce实现SQL操作内容请搜索靠谱客的其他文章。





![[Hive]MapReduce将数据写入Hive分区表](https://www.shuijiaxian.com/files_image/reation/bcimg25.png)


发表评论 取消回复